


Funktionen


Anwendungsüberwachung und -protokollierung: Ein Leitfaden für Entwickler zur Übernahme der Kontrolle
BeobachtbarkeitDevOpsperformanceautomatisierung
18 August 2025
Diese Seite wurde von unseren Experten auf Englisch verfasst und mithilfe einer KI übersetzt, um einen schnellen Zugriff zu ermöglichen! Die Originalversion findest du hier.
Kein Entwickler wünscht sich um 3 Uhr morgens dringende Serverausfälle und Leistungswarnungen, aber genau das kann ohne solide Anwendungsüberwachung passieren. Schlechte Leistung und Ausfälle wirken sich direkt auf Ihren Umsatz aus.
Die Untersuchungen vonAkamai und SOASTAzeigen die brutalen wirtschaftlichen Auswirkungen von Performance-Problemen: Schon eine Erhöhung der Latenzzeit um 100 ms führt zu einem Rückgang der Konversionsraten um 7 %, während längere Ausfallzeiten stündlich Tausende von Dollar verschlingen können. Dieser direkte Zusammenhang zwischen der technischen Leistung und den Geschäftsergebnissen ist genau der Grund, warum sich Ihr Überwachungsstack über eine einfache Nachverfolgung hinaus zu einem Frühwarnsystem entwickeln muss, das Probleme erkennt und behebt, bevor sie überhaupt auf den Bildschirmen Ihrer Benutzer erscheinen.
Die Überwachung der Anwendungsleistung bedeutet, Probleme zu stoppen, bevor sie entstehen. Gut konfigurierte Service Level Objectives (SLOs) verwandeln potenzielle Katastrophen in kleine Korrekturen.
"Die beste Zeit, einen Fehler zu beheben, ist, bevor er existiert" - Andrew Hunt, Mitautor von The Pragmatic Programmer
In diesem Leitfaden werden wir diese Schlüsselbereiche untersuchen:
- Frühwarnsysteme, die Probleme gleich zu Beginn erkennen
- Präzise Warnungen, die die Grundursachen identifizieren
- Datengesteuerte Wartungsplanung
- Einsatzerprobte Tools, die zu Ihrem Stack passen
Warum überwachen? Die wahren Kosten von Ausfallzeiten
Was schmerzt mehr als ein Weckruf um 3 Uhr morgens, wenn die Einnahmen nach einem Systemausfall sinken. Hier erfahren Sie, wie intelligente Überwachung Brände stoppt, bevor sie entstehen:
- Sehen Sie, wie es kaputt geht: Die Benutzer werden Ihnen nicht sagen, wenn etwas langsamer wird - sie werden es Ihnen vorgaukeln.
- Schneller reparieren: Präzise Systemeinblicke können Ihre Lösungszeit erheblich verkürzen
- Intelligente Skalierung: Überwachen Sie Kapazitätsmetriken, um Ressourcen auf der Grundlage der tatsächlichen Nachfrage zu skalieren
- Datengestützte Entscheidungen: Endlich können Sie die tatsächlichen Auswirkungen Ihrer technischen Entscheidungen messen
Proaktive Sicherheit: Warten Sie nicht auf Sicherheitsverletzungen. Erkennen und blockieren Sie Bedrohungen in Echtzeit mit kontinuierlicher Überwachung.


Die drei Kernelemente der Anwendungsüberwachung
Die Anwendungsüberwachung sorgt dafür, dass Ihre Systeme ehrlich bleiben. Drei Elemente arbeiten zusammen, um Ihnen mitzuteilen, was unter der Haube vor sich geht.
1. Metriken: Verfolgen Sie wichtige Zustandsindikatoren
- Überwachen Sie den Zustand Ihres Systems in Echtzeit - fangen Sie kleine Probleme ab, bevor sie zu echten Kopfschmerzen werden
- Überwachen Sie Schlüsselindikatoren wie CPU-Auslastung, Antwortzeiten und Fehlerquoten
- Stellen Sie intelligente Warnmeldungen ein, die Sie benachrichtigen, wenn Metriken außerhalb akzeptabler Bereiche liegen.
2. Protokolle: Die digitale Papierspur Ihres Systems
- Erfassen Sie detaillierte Aufzeichnungen zu jedem wichtigen Ereignis in Ihrer Anwendung
- Protokollieren Sie alles, was sich in Ihrem Systembewegt. Jeder Fehler, jede Warnung und jede Benutzeraktion. Das ist Ihr digitales Protokoll, wenn etwas schief geht.
- Fehlersuche mit vollständigen Kontext- und Zeitstempeldaten
3. Rückverfolgungen: Die Karte der Reise Ihrer Anfrage
- Verfolgen Sie Anfragen auf ihrem Weg durch Ihre verteilten Dienste
- Finden Sie Leistungsengpässe und verbessern Sie Dienstverbindungen
- Sehen Sie, wie die verschiedenen Teile Ihrer Anwendung zusammenarbeiten, von API-Aufrufen bis hin zu Datenbankabfragen und Dienstkommunikation
Diese drei Teile bilden zusammen die Grundlage für die Überwachung und helfen Ihnen, Probleme frühzeitig zu erkennen und einen reibungslosen Ablauf zu gewährleisten. Wissen Sie, was toll ist? Moderne Cloud-Plattformen machen es ziemlich einfach, diese Überwachungs-Tools einzurichten - es sind keine Fachkenntnisse erforderlich. Wie das geht, erfahren Sie im nächsten Abschnitt.
Überwachung in der Cloud-Ära
Die Cloud-Überwachung bietet Ihnen eine direkte Verbindung zwischen dem Systemzustand und den Auswirkungen auf das Geschäft. Durch die Überwachung in Echtzeit können Sie kleine Probleme erkennen und beheben, bevor sie sich zu großen Problemen auswachsen, die Ihre Benutzer beeinträchtigen. Sie können Ihr System auf der Grundlage aktueller Leistungskennzahlen optimieren.
Moderne Container-Plattformen wie Kubernetes haben die Art und Weise, wie wir Daten betrachten, verändert und bieten detaillierte Einblicke in jede Komponente unserer Anwendungen. Sie erhalten granulare Einblicke und behalten gleichzeitig den vollständigen Kontext Ihres Systems.
Multi-Runtime-Architektur: Optimierte Überwachung über Ihren gesamten Stack
Moderne Anwendungen sind vielseitig und anpassungsfähig, da sie verschiedene spezialisierte Tools (sogenannte Laufzeiten) verwenden, um verschiedene Aufgaben effizient zu erledigen. Rust erledigt die schweren Arbeiten, Node steuert Web-APIs und Python verarbeitet Daten. Jede Laufzeitumgebung benötigt einen eigenen Überwachungsansatz, um Probleme frühzeitig zu erkennen - stellen Sie sich vor, Sie hätten spezialisierte Ärzte für verschiedene Teile Ihres Systems.
| Laufzeit | Anfragen/Sek. | Speicher-Muster | Schwerpunkt der Überwachung | Häufiger Anwendungsfall |
|---|---|---|---|---|
| Rust | 690 | Statische Zuweisung | Thread-Metriken, Speichersicherheit | Leistungsstarke Dienste |
| Node.js | 100 | Ereignisgesteuert | Ereignisschleife, asynchrone Operationen | API-Dienste, Echtzeit-Anwendungen |
| Python | 50 | Zählen von Referenzen | GIL-Konkurrenz, Speichernutzung | Datenverarbeitung, ML-Dienste |
Laufzeitspezifische Überwachungsstrategien:
Diese Strategie trägt dazu bei, die optimale Leistung Ihrer gesamten Anwendung aufrechtzuerhalten und gleichzeitig die mittlere Zeit bis zur Problemlösung zu verkürzen, wenn Probleme auftauchen.
- Node.js-Überwachung
- Verfolgen Sie die Verzögerung von Ereignisschleifen (Warnschwelle: >100ms)
- Überwachung von Heap-Nutzungsmustern mit Tools wie clinic.js
- Beispiel-Konfiguration:
{ "eventLoopLag": { "warning": 100, "critical": 500 }, "heapUsage": { "warning": "70%", "critical": "85%" } }
- Python-Überwachung
- Überwachung auf GIL-Konkurrenz mit py-spy
- Aufspüren von Speicherlecks mit memory_profiler
- Beispiel-Konfiguration:
{ "gilContentionRate": { "warning": "25%", "critical": "40%" }, "memoryGrowth": { "warning": "10MB/min", "kritisch": "50MB/min" } }
- Rust-Überwachung
- Überwachen Sie die Nutzung des Threadpools, um die Reaktionsfähigkeit des Dienstes zu erhalten
- Verwenden Sie metrics-rs, um die Systemressourcen zu überwachen.
- Beispiel-Konfiguration:
{ "threadPoolUtilization": { "warning": "85%", "critical": "95%" }, "requestLatency": { "warning": "10ms", "critical": "50ms" } }
Upsun macht die Arbeit mit mehreren Laufzeiten weniger komplex, indem es Ihnen von einem einzigen Ort aus Einblick in Ihren gesamten Stack gibt. Sie können Abhängigkeiten zwischen den Diensten definieren und verwalten, was Ihnen hilft, potenzielle Engpässe zu erkennen. Mit unserer einheitlichen Überwachung können Sie die Leistung über alle Technologien hinweg verfolgen.
Zahlen als Entscheidungsgrundlage
Im Folgenden finden Sie die wichtigsten Kennzahlen, die Sie im Auge behalten sollten, sowie deren Schwellenwerte und was zu tun ist, wenn etwas schief läuft:
1. Leistungsmetriken (Geschwindigkeit und Reaktionsfähigkeit)
Titelspartentest
| Kennzahl | Normal | Warnung | Kritisch |
|---|---|---|---|
| Reaktionszeit | < 200ms | > 500ms | > 1000ms |
| Fehlerrate | < 0.1% | > 1% | > 5% |
Überwachung der Antwortzeit: Verfolgen Sie die Antwortgeschwindigkeit von Anfragen - das ist der Pulsschlag für Ihre Benutzererfahrung.
- Wenn die Warnschwelle erreicht ist: Erstellen Sie ein Profil langsamer Abfragen (mit Datenbank-Profiling-Tools), optimieren Sie Code-Pfade und überprüfen Sie die Netzwerklatenz (mit Traceroute, mtr).
- Wenn die kritische Schwelle erreicht ist: APM-Diagnose einführen. Verfolgen Sie Engpässe. Überprüfen Sie Timeouts. Ressourcen überwachen.
[2025-02-13 12:15:23] [WARN] Langsame Abfrage entdeckt - Endpunkt: /payment - Dauer: 650ms - Abfrage: SELECT * FROM orders WHERE user_id = ?
Überwachung der Fehlerrate: Verfolgen Sie Anfragen, die fehlschlagen, um einen reibungslosen Betrieb Ihres Dienstes zu gewährleisten.
- Wenn die Warnschwelle erreicht ist: Analysieren Sie die Fehlermuster in Ihrem gesamten Stack (mithilfe von Tools zur Fehlerverfolgung).
- Wenn der kritische Schwellenwert erreicht wird: Überprüfen Sie die jüngsten Deployments und Infrastrukturänderungen.
[2025-02-13 12:30:00] [ERROR] POST /api/users - 500 Internal Server Error - Grund: Datenbankverbindung fehlgeschlagen
2. System-Vitalien
| Metrik | Normal | Warnung | Kritisch |
|---|---|---|---|
| CPU-Auslastung | < 70% | > 70% (5+ min) | > 85% (2+ Min.) |
| Speicherauslastung | < 75% | > 85% | > 95% |
CPU-Überwachung: Finden Sie Leistungsengpässe frühzeitig und beheben Sie sie, bevor Ihre Benutzer merken, dass etwas nicht in Ordnung ist.
- Wenn die Warnschwelle erreicht ist: Profilieren Sie CPU-lastige Prozesse (mit top, htop), optimieren Sie Algorithmen.
- Wenn die kritische Schwelle erreicht ist: Skalieren Sie die Rechenkapazität, optimieren Sie kritische Ausführungspfade.
[2025-02-13 14:20:33] [WARN] Hohe CPU-Auslastung - Dienst: API - Auslastung: 82%
Speicherüberwachung: Die Verfolgung der Speichernutzung findet Speicherlecks, bevor sie Ihre Anwendung zerstören. Keine Abstürze, keine Überraschungen.
- Wenn die Warnschwelle erreicht ist: Führen Sie Speicher-Profiler aus, um Heap-Dumps und Garbage Collection zu überprüfen.
- Wenn der kritische Schwellenwert erreicht ist: Suchen Sie nach Speicherlecks und starten Sie bei Bedarf neu.
[2025-02-13 14:45:10] [WARN] Speicherdruck - Dienst: BackgroundJobProcessor - Heap-Auslastung: 90%
Festplatten-E/A-Überwachung: Überwachen Sie sowohl die Geschwindigkeit, mit der Ihr Speicher Operationen verarbeiten kann (IOPS), als auch die Datenmenge, die er auf einmal bewegen kann (Durchsatz), damit alles gut läuft.
- Legen Sie Basiswerte für Ihre spezifischen Arbeitslasten fest (mit iostat, iotop)
- Warnung bei signifikanten Musteränderungen
- Überwachen Sie die Datenbank- und Dateivorgänge genau und passen Sie sie an, wenn die Leistung zu schwächeln beginnt.
3. Service-Level-Ziele (SLOs)
Verfolgung der Verfügbarkeit: Definieren Sie messbare SLOs, die Ihre Serviceleistung quantifizieren. Verfolgen Sie Latenz, Fehlerraten und Betriebszeit.
- Zielvorgabe: Angestrebte Betriebszeit von 99,95 %. Verfolgen Sie das Fehlerbudget (die zulässige Anzahl von Ausfallzeiten oder Fehlern, bevor die Service Level Agreements verletzt werden).
- Bei Verletzung: Automatische Skalierung auslösen, wenn das Fehlerbudget 90 % erreicht, um die Kapazität proaktiv zu verwalten.
[2025-02-13 15:00:00] [LOG] SLO-Verletzung erkannt - Fehlerbudget: 92% - Region: US-Ost - Status: Initiierung einer Kapazitätsanalyse
Leistungs-SLOs: Definieren Sie Antwortzeitziele, die den Erwartungen der Benutzer entsprechen, und messen Sie diese regelmäßig.
- Zielvorgabe: Halten Sie die p99-Latenz (99. Perzentil der Antwortzeit) unter 500 ms, um sicherzustellen, dass die meisten Nutzer ein schnelles, reibungsloses Erlebnis haben.
- Bei Durchbruch: Erhöhen Sie die Ressourcen und optimieren Sie die Codepfade, um das Serviceniveau wiederherzustellen.
4. Echte Benutzerkennzahlen, die wichtig sind
- Seitenladezeit:
- Normal: < 2s
- Warnung: > 3s
- Kritisch: > 5s (Benutzer verlassen die Seite)
- Aktionsschritte:
- Profil der Frontend-Leistung (mit Lighthouse, WebPageTest)
- Optimieren Sie Assets und API-Aufrufe
- Verwendung von Netzwerktest-Tools zur Identifizierung und Behebung von Leistungsengpässen
[2025-02-13 16:10:22] [WARN] Langsamer Seitenaufbau - URL: /products - Durchschnittliche Ladezeit: 4.2s
- Abschluss des Benutzerflusses: Verfolgen Sie erfolgreiche User Journeys.
- Normal: > 95%
- Warnung: < 90%
- Kritisch: < 85%
- Aktionsschritte:
- Analysieren Sie die Trichteranalyse
- Fehlerprotokolle überprüfen
- Überprüfung der Sitzungsdaten auf Abbruchpunkte
[2025-02-13 16:30:45] [WARN] Warenkorbabbruch-Spike - User Journey: Checkout - Abschlussrate: 88%
Verfolgen Sie diese benutzerorientierten Metriken konsequent und ergreifen Sie schnelle Maßnahmen, wenn Warnzeichen auftauchen; so halten Sie einen soliden Service aufrecht und verhindern Frustration der Benutzer. Wenn Sie diese Erkenntnisse mit Ihrer Systemüberwachung und -protokollierung kombinieren, erhalten Sie ein Bild der Beobachtbarkeit, das sowohl technische Spitzenleistungen als auch geschäftlichen Erfolg ermöglicht. Auf dieser Grundlage wollen wir nun untersuchen, wie Sie Ihre Systeme in Echtzeit mit einer robusten Sicherheitsüberwachung schützen können.
5. Schützen Sie Ihre Systeme in Echtzeit
Die Sicherheitsüberwachung arbeitet mit der Leistungsüberwachung zusammen, um Ihre Systeme vor Bedrohungen zu schützen. Hier ist Ihr praktisches Sicherheits-Toolkit:
- Intelligente Erkennung
- Blockieren verdächtiger IPs nach 10 fehlgeschlagenen Anmeldeversuchen pro Minute
- Alarmieren Sie, wenn der Datenverkehr innerhalb von 5 Minuten um das Dreifache über das normale Maß ansteigt.
Scannen von Sicherheitsereignissen alle 30 Sekunden, um Angriffsmuster in Echtzeit zu erkennen - Ihre erste Verteidigung gegen neue Bedrohungen
| Angriffsart | Erkennungsmethode | Reaktion |
|---|---|---|
| Missbrauch von Zugangsdaten | Login-Geschwindigkeit pro IP | Progressive Ratenbegrenzung |
| Datendiebstahl | Ungewöhnliche Datenmuster | Netzwerk-Isolierung |
- Aktive Verteidigung
- Ratenbegrenzung, die sich an Ihr Datenverkehrsmuster anpasst
- Sofortige Blockierung von bösartigen Aktivitäten
- Integration von Bedrohungsdaten in Echtzeit
- Playbook für schnelle Reaktionen
- Standardisierter Umgang mit Bedrohungen mit MITRE ATT&CK
- Automatisierte Antwortsequenzen
Ziele für die Reaktionszeit:
| Art der Bedrohung | Reaktionszeit | Erforderliche Aktion |
|---|---|---|
| Brachiale Gewalt | < 5 Minuten | IPs blockieren, Sicherheit alarmieren |
| Datenverletzung | < 15 Minuten | Betroffene Systeme isolieren |
| DDoS | < 10 min | Schutzmaßnahmen skalieren, Datenverkehr filtern |
| Zero-Day | < 30 Minuten | Systeme patchen und aktualisieren |
6. Geschäftliche Metriken
Die technischen Metriken Ihrer Anwendung wirken sich direkt auf Ihr Endergebnis aus. Hier erfahren Sie, wie Sie Leistungsdaten in Geschäftswert umwandeln:
| Metrik | Normal | Warnung | Kritisch | Aktion |
|---|---|---|---|---|
| Transaktion Erfolg | ≥99% | 98-99% | <95% | Zahlungssysteme und API-Status prüfen |
| Einnahmeverlust | $0 | $1-5K/Std. | >$10K/Std. | Aktivieren Sie die Reaktion auf Vorfälle |
Reaktionsmatrix für Transaktionsprobleme:
- 98-99%: Genaue Überwachung
- Systemprotokolle überprüfen
- Überprüfung der letzten Einsätze
- 95-98%: Sofortige Maßnahmen
- Analysieren Sie den Zustand des Zahlungsgateways
- Überprüfung der Verkehrsmuster
- <95%: Kritische Reaktion
- Aktivieren Sie das Notfallteam
- Ausführen von Rollback-Verfahren
Wichtigste Schlussfolgerung: Verfolgen Sie diese Metriken in Echtzeit und passen Sie die Schwellenwerte auf der Grundlage Ihrer Geschäftsmuster an. Eine schnelle Reaktion auf eine Verschlechterung verhindert größere Umsatzeinbußen.
Protokolle:
Jedes Ereignis, jeder Fehler und jede Benutzeraktion wird in den Protokollen festgehalten, so dass Sie im Falle eines Fehlers einen vollständigen Überblick erhalten. Sie sind Ihre erste Verteidigungslinie bei Produktionsproblemen.
Warum strukturierte Protokolle wichtig sind
- Sicherheitswarnungen: Erkennen Sie verdächtige Muster frühzeitig
- Systemklarheit: Sehen Sie, wie Dienste in Echtzeit interagieren
- Frühzeitige Erkennung: Beheben Sie Probleme, bevor Benutzer sie melden
Was das für Sie bedeutet:
- Schnelle Suche: Suchen Sie nach Problemen anhand von request_id, user_id, error_type oder Zeitstempel
- Erkennen Sie Muster: Erkennen Sie wiederkehrende Probleme, bevor sie zu Problemen werden
- Automatisieren Sie Antworten: Richten Sie Warnmeldungen ein, die ausgelöst werden, wenn bestimmte Dinge beachtet werden müssen.
- Saubere Daten: Konsistente Analyse von Protokollen über Ihren gesamten Stack
Pro-Protokollierungsverfahren
- Wählen Sie Ihre Protokollebenen mit Bedacht:
DEBUG: Details nur für Entwickler (nicht für Produktentwickler)INFO: Normale SystemereignisseWARN: Probleme, die Aufmerksamkeit erfordernERROR: Behebbare AusfälleKRITISCH: Alles fallen lassen und sofort beheben
- Wichtige Felder in jedem Protokoll:
request_id: Verknüpfung von Ereignissen über Dienste hinwegZeitstempel: UTC für globale Verfolgunguser_id: Wer hat das Ereignis ausgelöstservice_name: Wo es passiert istlog_level: Wie dringend ist es
- Bleiben Sie sauber: Überall ein Format verwenden
- Speichern Sie es intelligent: Zentralisierung in ELK oder Cloud Logging mit Aufbewahrungsplänen, die Ihren Bedürfnissen entsprechen
Beispiel: Strukturiertes Logging in Python
`import logging import json logger = logging.getLogger(name) def process_order(order_id, user_id, product_name, quantity): logger.info("Processing order", extra={ "order_id": order_id, "user_id": user_id, "product_name": product_name, "quantity": quantity, "event_type": "order_processing" # Hinzufügen von Kontext für die Analyse }) try: # ... Logik der Auftragsverarbeitung ... logger.info("Auftrag erfolgreich verarbeitet", extra={ "order_id": order_id, "status": "success", "event_type": "order_completion" }) except Exception as e: logger.error("Fehler bei der Verarbeitung der Bestellung", extra={ "order_id": order_id, "error_message": str(e), "event_type": "order_error" }, exc_info=True) # Stack-Trace für Fehler einbeziehen raise
Beispiel für die Verwendung
process_order("ORD-12345", "user-42", "Awesome Widget", 2)`
Beispiel Log-Ausgabe (JSON):
{"asctime": "2025-02-13 18:00:00", "levelname": "INFO", "name": "__main__", "message": "Processing order", "order_id": "ORD-12345", "user_id": "user-42", "product_name": "Awesome Widget", "quantity": 2, "event_type": "order_processing"} {"asctime": "2025-02-13 18:00:01", "levelname": "INFO", "name": "__main__", "message": "Bestellung erfolgreich verarbeitet", "order_id": "ORD-12345", "status": "success", "event_type": "order_completion"}
Wenn Sie eine strukturierte Protokollierung in anderen Programmiersprachen benötigen, finden Sie hier einige solide Optionen:
- Winston für Node.js formatiert Protokolle und leitet sie durch mehrere Ziele
- Serilog für .NET bietet stark typisierte Protokollierung mit guter Leistung
- Logrus in Go hebt die strukturierte Protokollierung mit umfangreichen Feldern und Hooks auf ein höheres Niveau
Jede dieser Bibliotheken bietet einen konsistenten Weg, um zu erfassen, was Ihr Code tut, während er läuft.
Verteiltes Tracing: Verbinden Sie Ihren Stack Ende-zu-Ende
Wenn Anfragen durch mehrere Dienste fließen, brauchen Sie einen klaren Einblick in das, was wo passiert. OpenTelemetry macht dies einfach, indem es Ihre Komponenten miteinander verknüpft, damit Sie Probleme schnell finden und beheben können.
from opentelemetry import trace from opentelemetry.trace import Status tracer = trace.get_tracer(__name__) @tracer.start_as_current_span("process_order") def process_order(order_id): with tracer.start_span("validate_order") as span: # Geschäftskontext hinzufügen span.set_attribute("order_id", order_id) if not is_valid(order_id): span.set_status(Status.ERROR) return False return True
Traces zeigen Ihnen genau, was passiert, wenn in Ihrem System etwas schief läuft, damit Sie Probleme schneller finden und beheben können.
Wählen Sie die richtigen Überwachungstools
Die Wahl der Überwachungswerkzeuge hat direkten Einfluss darauf, wie gut Sie in der Lage sind, Probleme zu erkennen und zu beheben. Hier finden Sie einen klaren und praktischen Leitfaden für die Auswahl von Tools, die für Ihren Stack geeignet sind.
1. Checkliste zur Tool-Auswahl
- Wie gut sind Sie mit der Technik vertraut? Befehlszeilentools vs. einfachere Schnittstelle
- Wo wird Ihre Anwendung ausgeführt? Cloud- oder Hybrid-Konfiguration
- Was können Sie ausgeben? Open Source bis Unternehmen
- Was wird benötigt? Grundlegende Verfolgung oder tiefe Einblicke
2. APM-Werkzeuge
Schnelle Einrichtung, volle Transparenz
- ✓ Keine Kopfschmerzen bei der Einrichtung
- ✓ Sofort einsatzbereite Überwachungstools
- ✓ Verfolgung in wenigen Minuten
- ✓ Entwickelt für Produktionslasten
- ✗ Zahlen Sie mehr, wenn Sie wachsen
- ✗ Schwer an spezifische Anforderungen anzupassen
- ✗ Sie sind an die Arbeitsweise eines bestimmten Anbieters gebunden
3. DIY-Überwachung
Für die Kontroll-Enthusiasten
- ✓ Bauen Sie es genau so, wie Sie es wollen
- ✓ Unterstützt von der Open-Source-Community
- ✓ Minimieren Sie die Kosten, indem Sie die Infrastruktur niedrig halten
- ✓ Tauschen und ersetzen Sie Tools ohne Reibung
- ✗ Erfordert tiefes technisches Know-how
- ✗ Sie sind Eigentümer der Überwachungslösung
- ✗ Skalieren Sie es selbst
4. Cloud-native Überwachung
Ideal, wenn Sie sich ganz auf eine Cloud konzentrieren
- ✓ Funktioniert mit Ihrer Plattform
- ✓ Schnell einzurichten
- ✓ Oft in den Plattformkosten enthalten
- ✓ Ein Dashboard für alles
- ✗ Gebunden an Ihre Plattform
- ��✗ Begrenzte Anpassungsmöglichkeiten
- ✗ Funktionen variieren je nach Plattform
Schneller Vergleich
| Funktion | SaaS APM | Quelloffen | Plattform-nativ |
|---|---|---|---|
| Einrichtung | Schnell (Datadog, Sentry) | Komplex (Prometheus + Grafana) | Eingebaut (AWS CloudWatch) |
| Steuerung | Begrenzt | Vollständig | Plattformbasiert |
| Skalieren | Automatisch | Manuell | Plattformgekoppelt |
| Kosten | Nutzungsabhängig | Infrastruktur + Wartung | Plattform inbegriffen |
| Wartung | Verwaltet | Selbstverwaltet | Plattform-verwaltet |
| Integration | Vorgefertigte Konnektoren | Kundenspezifische Implementierung | Eigene Tools |
| Am besten geeignet für | Schnelle Bereitstellung | Vollständige Flexibilität | Plattform-Anpassung |
Tipp: Mischen Sie Tools je nach Überwachungsbedarf. Verwenden Sie SaaS APM für die wichtigsten Metriken und spezialisierte Tools für bestimmte Anforderungen.
Wählen Sie Ihr Überwachungspaket nach den wichtigsten Aspekten aus:
- DIY-Route: Wenn Sie granulare Kontrolle und benutzerdefinierte Compliance-Funktionen benötigen
- SaaS APM-Tools: Wenn Sie eine Überwachung wünschen, die einfach funktioniert und mit Ihnen skaliert
- Cloud-native Tools: Wenn Ihre Anwendungen in einer Cloud laufen und Sie alles integriert haben möchten
Handlungsfähige Überwachung: Daten in Entscheidungen umwandeln
Nachdem wir uns nun mit den Überwachungstools befasst haben, sollten wir diese Daten auch nutzen. Hier erfahren Sie, wie Sie Metriken in automatisierte Aktionen umwandeln:
1. Intelligente Warnungen, die zum Handeln anregen
Konfigurieren Sie intelligente Warnmeldungen, die Daten in Aktionen umwandeln:
- Folgenbewusst: Konzentrieren Sie sich auf benutzer- und geschäftskritische Metriken
- Zielgenauigkeit: Sofortige Weiterleitung von Warnungen an Serviceverantwortliche
- Reichhaltiger Kontext: Einschließlich verwertbarer Daten zur Fehlerbehebung
- Dynamische Schwellenwerte: Verwenden Sie dynamische Basislinien, um Störungen zu reduzieren
Warnmeldungen und Runbook-Vorlagen:
Reaktionszeit > 500ms (5min)
Aktionen:
- check_cache_hit_ratio
- verify_db_connections
- skalieren_dienst_pods
Fehlerrate > 1% (1min)
Aktionen:
- inspect_error_logs
- verify_dependencies
- rollback_if_needed
CPU-Auslastung > 80% (3min)
Aktionen:
- analysiere_Ressourcenauslastung
- optimierte_Abfragen
- Kapazität hinzufügen
Fehler bei der Gesundheitsprüfung
Aktionen:
- verify_endpoints
- prüf_zertifikate
- restart_if_unresponsive
2. Automatisierung
Lassen Sie uns automatisierte Überwachungsabläufe implementieren:
- Alert-Routing:
- Durch intelligentes Routing werden kritische Probleme über PagerDuty/Slack direkt an die richtigen Teams weitergeleitet.
- Automatische Eskalation von Alarmen basierend auf Schweregrad und Reaktionszeit
- Leiten Sie Alarmtypen über benutzerdefinierte Pfade weiter
- Problemverfolgung:
- Automatische Erstellung von Tickets mit vollständigem Kontext und Stacktrace in nur 2 Sekunden
- Überwachen Sie Metriken und Verhaltenstelemetrie, um aufkommende Muster zu erkennen (Reaktionszeit unter 100 ms)
- Skalierung der Ressourcen:
- Automatische Skalierung auf der Grundlage echter Leistungsdaten
- Release-Kontrolle:
- Rollback von Implementierungen und Canary-Releases, wenn die Metrik in die falsche Richtung läuft.
# Beispiel für eine Alarmkonfiguration: - Name: "Hohe API-Antwortzeit" Metrik: "http_request_duration_seconds_p95" Schwellenwert: 500ms Dauer: "5m" severity: "warning" route_to: "dev-team-channel" notification_type: "slack" - name: "Critical Service Down" metric: "service_health_check_failed" service: "payment-service"
severity: "critical" route_to: "on-call-pager" notification_type: "pagerduty" actions: - "auto_restart_service" - "create_jira_ticket"
3. Dashboards, die das Rauschen unterdrücken
Mit der Automatisierung und den intelligenten Warnmeldungen können wir nun Dashboards erstellen, die wichtige Erkenntnisse liefern. Wir arbeiten mit folgendem Material:
- Kernmetriken: Verfolgung des Systemzustands und der Leistungsmetriken in Echtzeit
- Leistungsdaten: Erkennen und beheben Sie Leistungsprobleme, bevor sie sich auf Ihre Benutzer auswirken.
- Debug-Toolkit: Drilldown in Metriken, wenn etwas schief läuft
- Rollenbasierte Ansichten: Rollenbasierte Ansichten: Erstellen Sie maßgeschneiderte Dashboards, die auf die Bedürfnisse des jeweiligen Teams zugeschnitten sind
Mit einer effektiven Überwachung können Sie technische Probleme erkennen und beheben, bevor sie sich auf Ihre Benutzer auswirken.
Kostenkontrolle
- Problem: Die Überwachung wird teurer, wenn Sie wachsen
- Die Lösung: Verfolgen Sie die Kosten und optimieren Sie die Ausgaben durch die Überwachung von Datenspeicherung und Nutzungsmetriken.
Verfolgen Sie die wichtigsten Metriken:
Monatliche Kosten = (Datenpunkte × Speicherzeit) + (Protokollvolumen × Rate) + (Abfragenutzung × Preis)
- Budget-Warnungen, die frühzeitig anschlagen
- Rücksichtslose Aufbewahrungsrichtlinien
Entwickeln Sie Ihre Überwachung weiter
Wie die Anwendungen, die sie überwachen, müssen auch die Überwachungssysteme mit der Zeit wachsen und sich anpassen. Statische Überwachungs-Setups sind schnell veraltet, wenn sich Ihre Architektur weiterentwickelt, neue Dienste hinzukommen und sich die geschäftlichen Prioritäten verschieben. Eine herausragende Überwachung ist keine einmalige Implementierung, sondern eine fortlaufende Praxis, die kontinuierlich einen steigenden Wert liefert.
Legen Sie einen vierteljährlichen Rhythmus fest, um Ihren gesamten Überwachungsansatz zu evaluieren und zu prüfen, welche Metriken verwertbare Erkenntnisse liefern und welche Rauschen erzeugen. Dieser konsequente Überprüfungszyklus stellt sicher, dass Ihre Überwachungstools die Probleme erkennen, die für Ihre aktuelle Architektur und Ihre Geschäftsziele am wichtigsten sind, anstatt die Probleme von gestern zu lösen.
Die ausgereiftesten technischen Organisationen behandeln ihre Überwachungskonfigurationen mit der gleichen Sorgfalt wie den Anwendungscode - sie werden versioniert, getestet und kontinuierlich verbessert. Wenn Sie die Überwachung als lebendiges System und nicht als statische Einrichtung betrachten, können Sie eine Beobachtungsfähigkeit aufbauen, die auch dann noch relevant und wertvoll bleibt, wenn sich Ihre technische Einrichtung verändert.
Ihre Überwachungs-Checkliste: ein praktischer Startpunkt
Lassen Sie uns Ihre Überwachungsstrategie auf der Grundlage der Anforderungen Ihrer Anwendung aufbauen. Beginnen Sie mit diesen grundlegenden Schritten:
- Zeichnen Sie die wichtigsten Benutzerströme auf. Dokumentieren Sie Ihre kritischen Geschäftstransaktionen und Benutzerpfade.
- Überwachen Sie die wichtigsten Metriken: Verfolgen Sie Antwortzeiten, CPU-Speicher und Fehler
- Fügen Sie eine strukturierte Protokollierung hinzu: Verwenden Sie JSON mit Anfrage-IDs für die Nachverfolgung
- Grundlegende Überwachung einrichten: Konfigurieren Sie Uptime-Checks und User Journey-Tests
- Erstellen Sie gezielte Dashboards: Erstellen Sie Ansichten, die wichtige Metriken hervorheben
- Konfigurieren Sie Warnungen: Richten Sie Benachrichtigungen ein, die zum Handeln anregen
- Überprüfen und verbessern: Planen Sie regelmäßige Überprüfungen, um Ihre Einrichtung zu verfeinern.
Entwicklungspfad der Beobachtungsfähigkeit
Sehen wir uns an, wie sich die Überwachung entwickelt, um Ihre Anforderungen zu erfüllen:
| Ebene | Überwachungskapazität | Geschäftliche Auswirkungen |
|---|---|---|
| 1 | Grundlegende Metriken und Protokolle | Schnellere Reaktion auf Vorfälle |
| 2 | Strukturierte Überwachung | Proaktive Problemvermeidung |
| 3 | Automatische Problembehebung | 99,99% Betriebszeit |
| 4 | Prädiktive Analytik | Änderungen ohne Auswirkung |
Wie die Überwachung abläuft

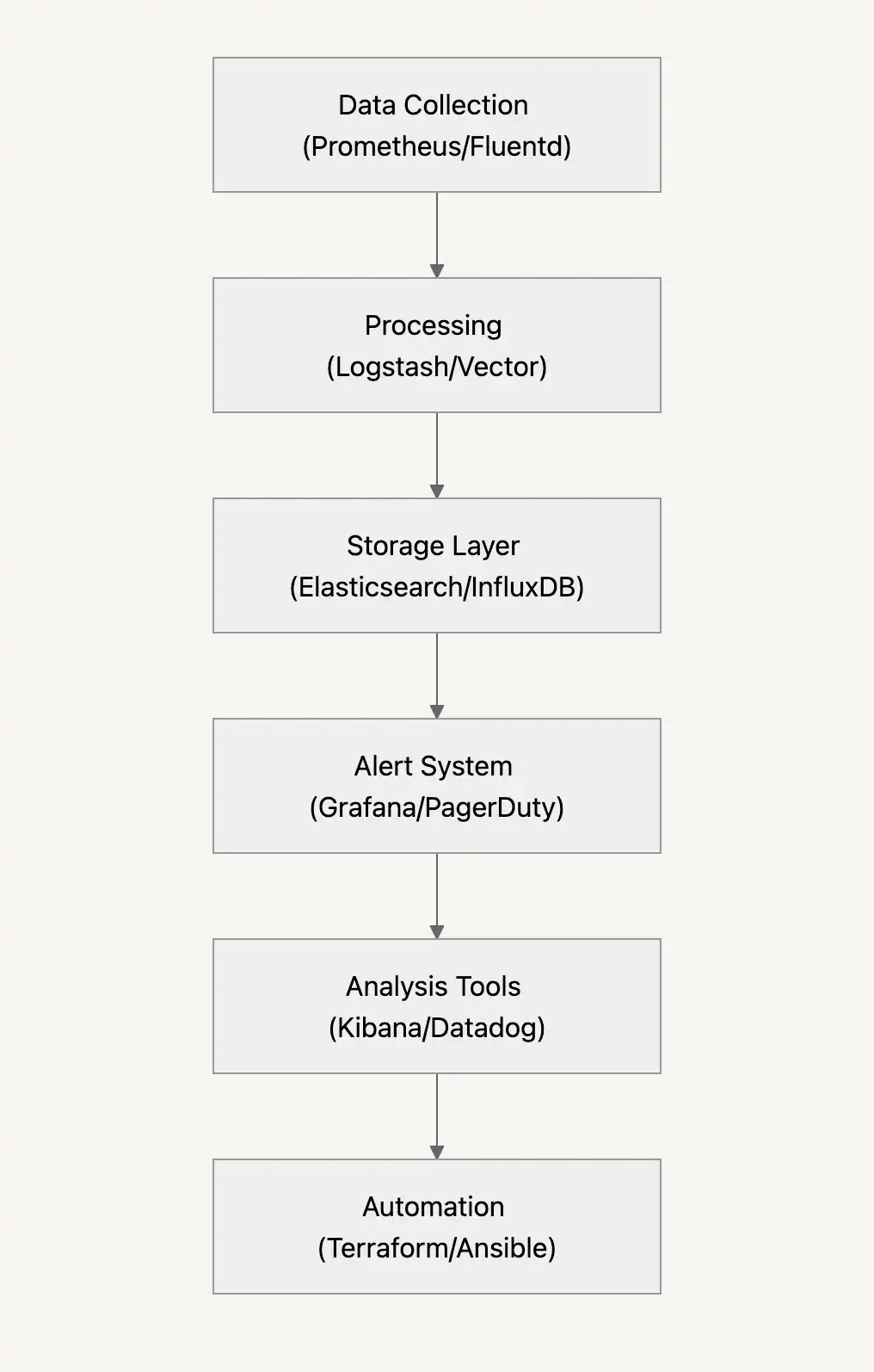
Optimieren Sie Ihre Überwachungspipeline
Zuverlässige Überwachungssysteme benötigen ein paar Schlüsselelemente:
- Verwenden Sie intelligente Stichproben, um Daten sauber zu halten, ohne wichtige Signale zu verlieren.
- Ausgewogene Verkehrslasten zur Erfassung aller kritischen Metriken
- Indizierung der Daten für eine schnelle Problemerkennung
- Logische Strukturierung der Daten zur Vereinfachung der Fehlerbehebung
Sicherheit
Woran Sie bei der Überwachung von Daten denken sollten:
- Filtern sensibler Daten bei der Erfassung
- Implementieren Sie Aufbewahrungsrichtlinien, die der Compliance entsprechen
- Überwachung der Zugriffsmuster im gesamten System
Wichtige Metriken
Hier erfahren Sie, worauf Sie achten sollten, um Ihre Systeme gut skalieren zu können:
- Mittlere Zeit bis zur Wiederherstellung (MTTR): Wie schnell Sie sich von Zwischenfällen erholen
- Mittlere Zeit zwischen Ausfällen (MTBF): Zeit zwischen Systemproblemen - länger ist besser
- Service Level Objectives (SLO): Ihre Zuverlässigkeitsziele und Verpflichtungen
- Fehlerbudget und Verbrauchsrate: Akzeptable Fehlerschwelle und Verbrauchsrate
Jede kleine Verbesserung bringt Sie einem Überwachungssystem näher, das Probleme verhindert, anstatt nur auf sie zu reagieren. Bauen Sie es Schritt für Schritt auf und sehen Sie zu, wie die nächtlichen Alarme der Vergangenheit angehören.
Ihr größtes Werk
steht vor der Tür
CompareVercel-AlternativeAmazee-AlternativeHeroku-AlternativePantheon-AlternativeManaged-Hosting-AlternativeFly.io-AlternativeRender-AlternativeAWS-AlternativeAcquia-AlternativeDigitalOcean-Alternative
ProduktÜberblickSupport and servicesPreview environmentsMulti-cloud and edgeGit-driven automationObservability and profilingSecurity and complianceScaling and performanceBackups and data recoveryTeam and access managementCLI, console, and APIIntegrations and webhooksPricingPricing calculator
Use casesBackend-LösungenAnwendungsmodernisierungE-Commerce-HostingCMS-HostingVerwaltung mehrerer StandorteSaaS-Erweiterungen
Join our monthly newsletter
Compliant and validated