


Funktionen




Diese Seite wurde von unseren Experten auf Englisch verfasst und mithilfe einer KI übersetzt, um einen schnellen Zugriff zu ermöglichen! Die Originalversion findest du hier.
(Dieser Artikel wurde ursprünglich in der Zeitschrift php[architect] in zwei Teilen veröffentlicht ).
Im Allgemeinen ist es keine gute Idee, Menschen anzulügen. Menschen mögen keine Unwahrheiten. Es ist beleidigend, jemanden anzulügen und neigt dazu, Beziehungen zu zerstören, sowohl persönliche als auch berufliche.
Aber Computersoftware ist kein Mensch (Gott sei Dank). Praktisch alle Software basiert heute auf Lügen, sehr gut organisierten und effektiven Lügen. Lügen machen moderne Computersysteme erst möglich.
Die neueste Generation der Software-Täuschung sind "Container". Container sind heutzutage der letzte Schrei: Sie machen das Hosting flexibler und zuverlässiger; sie erleichtern die Einrichtung von Entwicklungsumgebungen; sie sind "wie leichtgewichtige VMs"; und dem Marketing nach zu urteilen, schmecken sie auch gut und machen weniger satt. Aber... was sind sie?
Hier ist das schmutzige kleine Geheimnis: Es gibt sie nicht. In Linux gibt es so etwas wie einen "Container" nicht. Das ist alles eine Lüge. Die Technologie, die dem Hosting von Upsun zugrunde liegt, ist einfach eine sorgfältige Kombination von Lügen, bis hin zum Mikrochip. Genau das ist der springende Punkt!
Um die Wahrheit über Container zu erfahren, müssen wir diese Lügen auspacken und sehen, wie ein modernes Linux-basiertes Betriebssystem tatsächlich funktioniert. Bevor wir über Container sprechen können, müssen wir zunächst über die allererste Lüge der modernen Computertechnik sprechen: Multitasking.
Was ist ein Prozess?
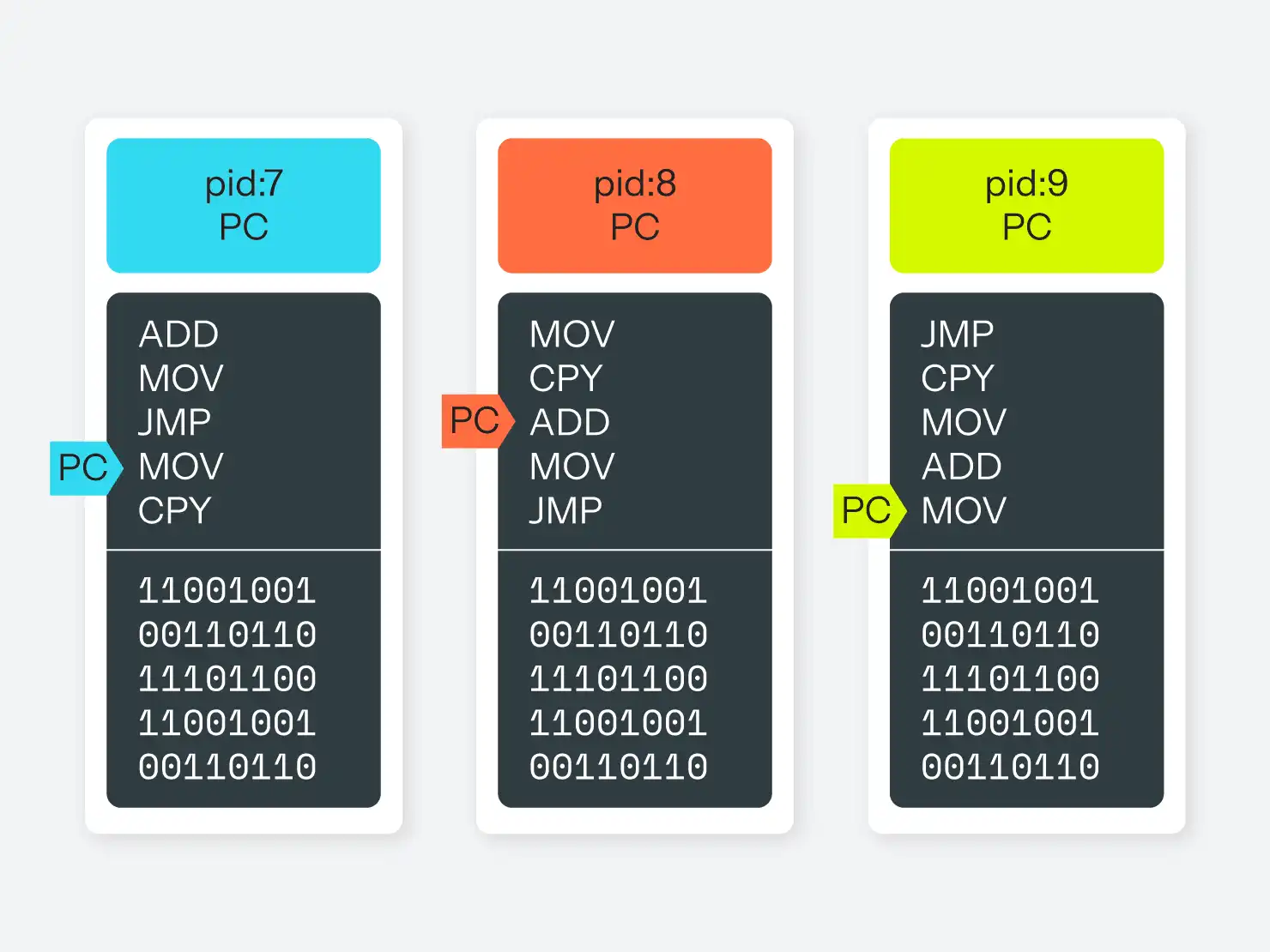
Auf der grundlegendsten Ebene ist jeder moderne Computer ein Stein (die CPU), der davon überzeugt wurde, Elektronen auf eine bestimmte Art und Weise auf der Grundlage einer langen Reihe von Anweisungen zu bewegen. Diese Anweisungen sind alle sehr einfache Operationen, aber eine lange Reihe solcher Anweisungen bildet ein Programm. Und die aktuell ausgeführte Anweisung wird in einem speziellen Speicherplatz, dem "Programmzähler" (PC), gespeichert.
Sehr oft muss ein Programm warten, wenn es versucht, mit einem anderen Teil des Computers zu kommunizieren, z. B. mit einem Netzwerkanschluss oder einem Festplattenlaufwerk. In dieser Zeit ist es hilfreich, wenn die CPU in der Lage ist, während des Wartens andere Anweisungen zu bearbeiten. So kann der Computer vorgeben (lügen!), dass er zwei Programme "gleichzeitig" ausführt.
Die Hardware der CPU hat eine besondere Beziehung zu einem bestimmten Programm, dem Betriebssystem. Dieses spezielle Programm wird immer als erstes gestartet und ist unter anderem für die "Kontextumschaltung" zuständig. In regelmäßigen Abständen "tickt" die CPU und registriert einen so genannten Timer-Interrupt. Dies veranlasst die CPU, ihre Arbeit zu unterbrechen und einen bestimmten Satz von Anweisungen aus dem Betriebssystem in den Arbeitsspeicher zu laden und dann fortzufahren. Dieser spezielle Satz von Anweisungen wird als "Timer-Interrupt-Handler" bezeichnet. Es gibt auch noch andere Arten von Unterbrechungen und Handlern, die für uns im Moment nicht relevant sind. Der Timer-Interrupt-Handler wählt dann ein anderes Programm aus, das in den Speicher der CPU geladen wird, und lässt es weiterlaufen. Dieser ganze Vorgang kann Tausende von Malen pro Sekunde stattfinden, was die Illusion (Lüge!) erweckt, dass der Computer mehrere Programme auf einmal ausführt.
Der Teil des Betriebssystems, der für das Ein- und Auslagern verschiedener laufender Programme zuständig ist, wird Scheduler genannt. Und technisch gesehen wird jedes der laufenden Programme als Prozess bezeichnet. In einem System mit mehreren CPUs oder mehreren Kernen läuft die gleiche Grundroutine ab, aber der Scheduler muss mehrere aktive Befehlslisten mit jeweils eigenem Programmzähler im Auge behalten.
Nebenbei bemerkt, ist ein Multithreading-Programm ein einzelner Prozess, der mehr als einen Programmzähler hat, der auf verschiedene Anweisungen in demselben Programm/Prozess zeigt. Wenn das Betriebssystem den Kontext wechselt, kann es den einen oder anderen Programmzähler innerhalb eines bestimmten Prozesses aktivieren.
Was ist virtueller Speicher?
Natürlich wissen die Programme nicht, dass sie sich alle dieselbe CPU zeitlich teilen. Und sie wissen auch nicht, dass sie sich alle denselben Systemspeicher teilen. Das Programm sagt, es solle in den Speicher an Adresse 12345 schreiben, aber es hat nicht wirklich die Adresse 12345. Das Betriebssystem ist dort!
Stattdessen verschwören sich CPUs und Betriebssysteme gegen Prozesse und belügen sie, indem sie sie glauben lassen, dass sie eine lange Liste zusammenhängender Speicheradressen haben, die bei 0 beginnen. Jedes Programm denkt, dass es das hat, aber in Wirklichkeit hat es eine Reihe kleiner, meist zusammenhängender Speicherabschnitte im gesamten physischen Speicher des Computers. Die CPU übersetzt die Adresse des prozesslokalen Speichers in die Adresse des physischen Speichers und wieder zurück, ohne dass das Programm davon etwas mitbekommt. Dieses Konzept wird als "virtueller Speicher" bezeichnet.
Diese Speicherlüge hat zwei entscheidende Vorteile: Einfachheit und Sicherheit. Aus der Sicht des Programms ist es viel zu komplex und schwierig, den Überblick darüber zu behalten, welcher Speicher zu ihm und welcher zu einem anderen Programm gehört. Der von anderen Programmen verwendete Speicher kann sich jederzeit ändern, und kein normalsterblicher Programmierer wird in der Lage sein, dies manuell zu berücksichtigen. Durch die Abstraktion dieses Problems wird der Programmierer von dem Versuch befreit, unvermeidliche Fehler bei der Speicherverwaltung zu vermeiden.
Diese Zuordnung bietet auch eine Sicherheitsebene. In den meisten Fällen ist ein Programm, das den Speicher eines anderen Programms liest, eine Sicherheitslücke, und die Möglichkeit, in den Speicher eines anderen Programms zu schreiben, ist es mit Sicherheit auch. Indem man den Programmen keine Möglichkeit gibt, den Speicher des jeweils anderen zu adressieren, wird es für ein laufendes Programm viel schwieriger, ein anderes zu beschädigen. (Schwerer, aber nicht unmöglich. In Sprachen mit manueller Speicherverwaltung ist es immer noch möglich, dies mit schlampiger Programmierung zu tun, was eine der Hauptquellen für Sicherheitsprobleme in diesen Sprachen ist).
Prozessverwaltung
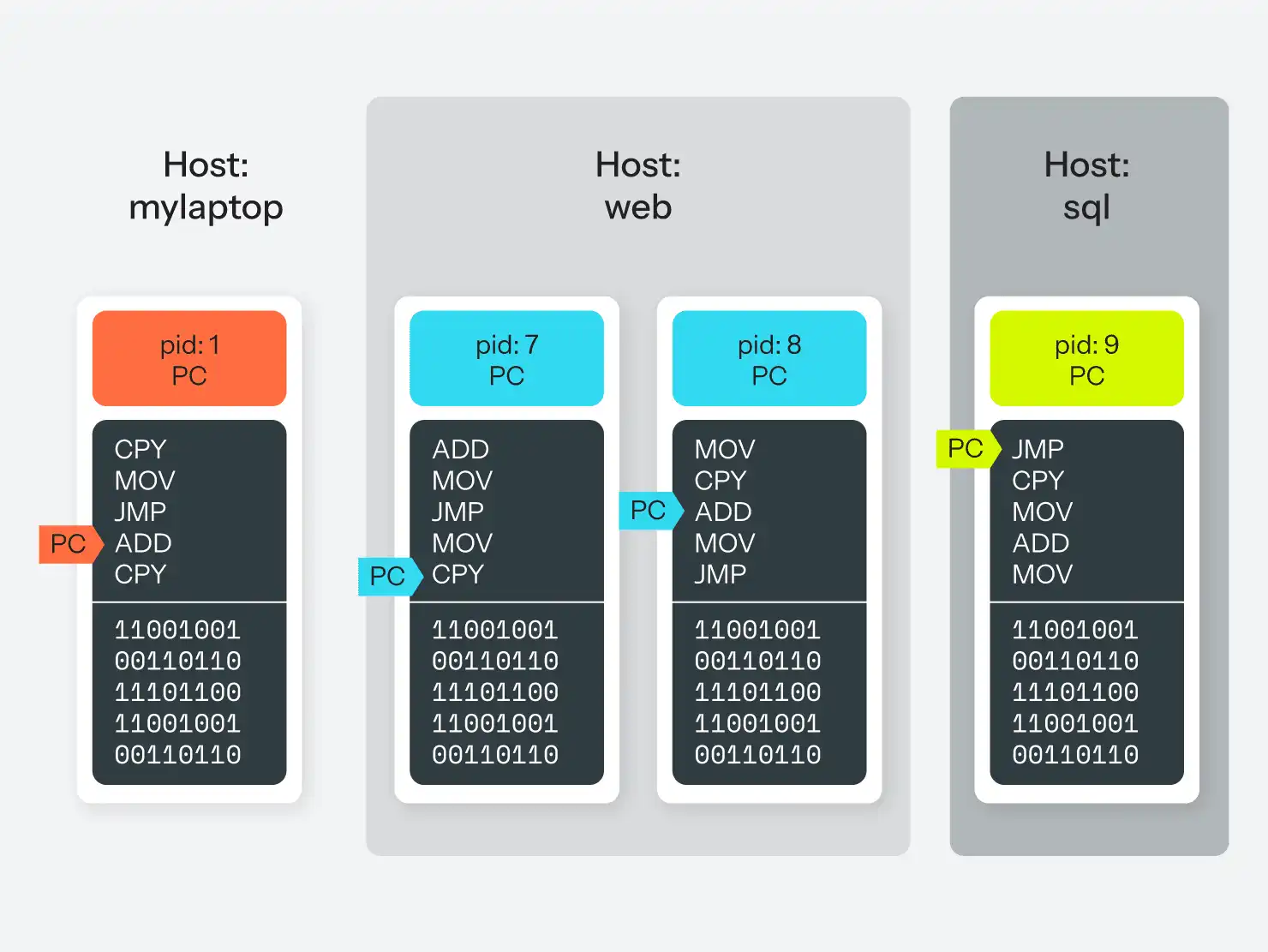
Auf einem Betriebssystem der Unix-Familie werden die Prozesse in einer Hierarchie danach verfolgt, welcher andere Prozess sie gestartet hat. Jeder Prozess kann das Betriebssystem auffordern, einen anderen Prozess zu starten oder den laufenden Prozess in zwei Prozesse zu "teilen", die dann "parallel" weiterlaufen können. Das Betriebssystem selbst hat keinen Prozess an sich, sondern kann als Prozess-ID 0 (oder PID 0) betrachtet werden. In Linux ist PID 1 ein spezieller Prozess namens init, der für die Verwaltung aller anderen Prozesse unter ihm verantwortlich ist. Im Laufe der Jahre sind verschiedene init-Programme aufgetaucht und wieder verschwunden, vom altehrwürdigen sysvinit bis zu runit, upstart und systemd.
Vom Konzept her sieht der Speicherbereich eines modernen Linux-Systems in etwa so aus wie in Abbildung 1.

Jeder Prozess hat seinen eigenen Speicherbereich und kann nicht direkt auf den Speicherbereich eines anderen Prozesses zugreifen. Er kann jedoch das Betriebssystem bitten, für ihn eine Nachricht an einen anderen Prozess zu übermitteln, wodurch die Prozesse miteinander kommunizieren können. Dafür gibt es verschiedene Mechanismen, aber der gebräuchlichste ist die Pipe-Datei, d. h. eine Scheindatei (Lüge!), die das Betriebssystem zur Verfügung stellt und in die ein Prozess in einem Datenstrom schreiben und aus der ein anderer Prozess in einem Datenstrom lesen kann. Diese Abstraktion ermöglicht es einem Programm, nicht zu wissen, ob sich der Prozess, mit dem es spricht, auf demselben Computer oder auf einem anderen Computer im Netzwerk befindet.
Wichtig ist hier, dass jeder Prozess über jeden anderen Prozess Bescheid wissen kann. Sie alle können das Betriebssystem nach Informationen über den Computer, auf dem sie laufen, fragen, z.B. welche Dateisysteme verfügbar sind, welche Benutzer auf dem System sind und welche Berechtigungen sie haben, wie der Hostname des Computers lautet, welche lokalen oder Netzwerkgeräte verfügbar sind, und so weiter. Und das Betriebssystem wird jedem Prozess, der danach fragt, die gleiche Antwort geben.
Einführung in die Linux-Namespaces
Alles, was wir bis jetzt gesagt haben, gilt mehr oder weniger für jedes halbwegs moderne Betriebssystem, abgesehen von ein paar Implementierungsdetails. Der Rest dieses Artikels ist sehr spezifisch für Linux (d.h. speziell für den Linux-Kernel, nicht für die gesamte GNU/Linux-Plattform), da von hier an vieles zwischen den verschiedenen Systemen variiert.
Seit Mitte bis Ende der 2000er Jahre hat der Linux-Kernel neue und lustige Wege gefunden, die Prozesse, die er verwaltet, zu belügen. Die letzten Teile funktionierten erst 2014 oder sogar 2015 vollständig, aber inzwischen sind sie ziemlich robust. Außerdem ist Linux insofern einzigartig, als es diese Funktionen stückweise implementiert hat, so dass Programme sie bei Bedarf einzeln nutzen können.
Die meisten dieser Funktionen fallen unter den Oberbegriff "Namespaces". Ähnlich wie Namespaces in gängigen Programmiersprachen bieten Linux-Namespaces eine Möglichkeit, Gruppen von Prozessen voneinander abzugrenzen. Genauer gesagt, ermöglichen Linux-Namespaces dem Betriebssystem, verschiedene Gruppen von Prozessen auf unterschiedliche Weise über verschiedene Dinge zu informieren. Und da Prozesse in einer Hierarchie stehen, bedeutet das Belügen eines Prozesses automatisch auch, dass alle seine Child-Prozesse auf dieselbe Weise belogen werden (es sei denn, diese wurden explizit in einen anderen Namespace verschoben).
Insgesamt gibt es sechs Arten von Namespaces, die der Linux-Kernel unterstützt.
Der UTS-Namespace
Der einfachste Namespace ist derjenige, der den Hostnamen des Computers steuert. Es gibt drei Systemaufrufe, die ein Prozess an das Betriebssystem richten kann, um seinen Namen zu erhalten und zu setzen: sethostname(), setdomainname() und uname(). Eigentlich wird damit nur eine globale String gesetzt, aber wenn man einen oder mehrere Prozesse in einen UTS-Namespace stellt, haben diese Prozesse ihre eigene "lokale globale String" zum Setzen und Lesen.
In der Praxis kann Ihre /etc/hostname-Datei den Computernamen "Homesystem" enthalten, aber indem Sie Ihren MySQL-Prozess in einen Namespace setzen, können Sie den MySQL-Prozess glauben lassen, der Hostname sei "Datenbank", während der Rest des Computers immer noch glaubt, er heiße "Homesystem". Das ist richtig, es ist einfach, ein Programm über seine eigene Identität zu belügen!
(Spaßfakt: Der Name UTS kommt von dem Namen der Struktur im Quellcode, die uname() benutzt, utsname, was wiederum ein Akronym für "Unix Time-sharing System" ist).

Der Mount-Namespace
Der mit Abstand älteste Namespace ist der Mount-Namespace, der bis ins Jahr 2002 zurückreicht. Der Mount-Namespace ermöglicht es dem Betriebssystem, ein anderes Dateisystem für eine andere Gruppe von Prozessen bereitzustellen.
Der chroot() -Befehl, den es unter Linux praktisch schon immer gab, ermöglicht es einem ausgewählten Prozess (und seinen Childs), eine bestimmte Teilmenge des Dateisystems so zu sehen, als wäre es das gesamte Dateisystem. Diese "chroot jails" wurden oft verwendet, um zu versuchen, ein System zu segmentieren, so dass bestimmte Prozesse nicht wussten, was sich sonst noch auf demselben Computer befand. Es gibt jedoch immer noch einen großen Dateisystembaum. Mit einem Mount-Namespace ist es möglich, dass es völlig unterschiedliche Dateisystembäume gibt, die sich überhaupt nicht überschneiden und gleichzeitig laufen; jeder Mount-Namespace sieht nur einen dieser Bäume und kann ihn verändern.
Es wird sogar noch seltsamer! Das bedeutet nicht nur, dass für zwei gegebene Prozesse die Wurzel des Dateisystems zwei völlig unterschiedliche Festplattenpartitionen sein könnten, sondern es bedeutet auch, dass sie zwei völlig unterschiedliche Festplattenpartitionen sein könnten, aber auch beide dann eine dritte Partition an unterschiedlichen Stellen in den beiden Bäumen mounten. In etwa wie in Abbildung 3.

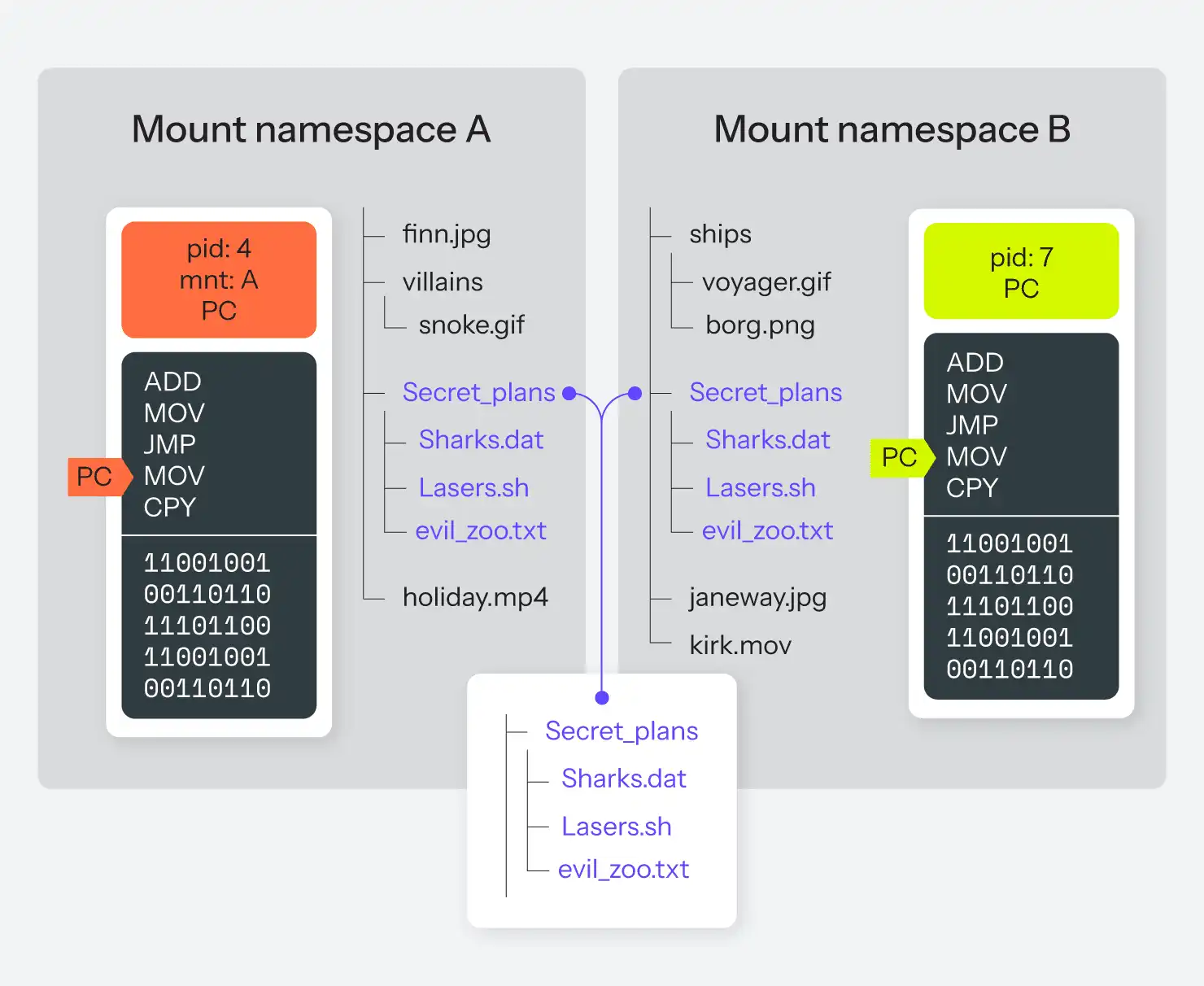
Denken Sie auch daran, dass jedes Block- oder Pseudo-Block-Gerät in ein Dateisystem eingebunden werden kann. Dabei kann es sich um eine Partition auf einer Festplatte handeln, aber genauso gut auch um ein Netzlaufwerk auf einem anderen Computer, ein lokales Wechselmedium wie eine DVD oder ein USB-Stick oder eine Dateisystem-Image-Datei, die sich auf einem anderen Dateisystem befindet.
Das Potenzial für Lügen und Täuschungen ist hier verblüffend.
IPC-Namespace
Dieser Bereich ist ein wenig undurchsichtig; wir haben bereits erwähnt, dass Prozesse über das Betriebssystem auf verschiedene Weise miteinander kommunizieren können. Zusammengefasst ist dies als Inter-Prozess-Kommunikation (IPC) bekannt, und es gibt Standardwege, dies zu tun. Die meisten davon sind eigentlich nur die Weitergabe von Nachrichten über Warteschlangen, und tatsächlich gibt es dafür Standard-APIs in POSIX (dem offiziellen Standard, aus dem jedes Low-Level-*nix-System besteht). IPC-Namensräume ermöglichen es dem Kernel, auch diese zu trennen und bestimmten Prozessen den Zugriff auf einige dieser IPC-Kanäle zu verweigern, je nach ihrem Namespace.
Prozess-Namespace
Jetzt kommen wir zum interessanten Teil. Wir sagten bereits, dass der Prozess mit der PID 1 immer init ist, und alle anderen Prozesse sind Childs von init, oder Childs von Childs von init, usw. Jeder Prozess erhält eine eindeutige numerische PID, um ihn im Auge zu behalten.
Sie können sich die auf Ihrem System laufenden Prozesse mit dem Befehl ps ansehen. Es gibt viele mögliche Schalter und Umschaltungen, aber wir werden hier nur einige besprechen.
Führen Sie ps -A aus, um eine Liste aller auf dem System laufenden Prozesse zu erhalten. Es sollte eine ziemlich lange Ausgabe sein, aber wenn Sie an den Anfang der Liste blättern, sehen Sie eine PID 1 mit einer CMD-Spalte, die angibt, welches Init-Programm Ihr System verwendet. Der Anfang der ps-Ausgabe für mein Ubuntu-System lautet zum Beispiel:
$ ps -A
PID TTY TIME CMD
1 ? 00:00:14 systemd
2 ? 00:00:00 kthreadd
4 ? 00:00:00 kworker/0:0H
6 ? 00:00:03 ksoftirqd/0
7 ? 00:05:36 rcu_sched
8 ? 00:00:00 rcu_bh
9 ? 00:00:00 migration/0
10 ? 00:00:00 lru-add-drain
11 ? 00:00:00 watchdog/0
12 ? 00:00:00 cpuhp/0
13 ? 00:00:00 cpuhp/1
14 ? 00:00:00 watchdog/1
15 ? 00:00:00 migration/1Obwohl es insgesamt über 300 Prozesse gibt. Wenn Sie ps xf ausführen, werden alle Prozesse für Ihren Benutzer angezeigt und die Hierarchie, welcher Prozess ein Child eines anderen Prozesses ist. In ähnlicher Weise zeigt ps axf alle Prozesse für alle Benutzer auf dem System an, einschließlich ihrer Hierarchie.
Das sind sehr nützliche Informationen, aber es gibt hier ein potenzielles Problem: Sie können genau sehen, welche Prozesse jeder andere Benutzer auf dem System ausführt! Ist das ein Sicherheitsproblem? Auf Ihrem Laptop wahrscheinlich nicht, aber auf jedem echten Mehrbenutzersystem könnte es das sein. Jeder böswillige Benutzer (oder ein Programm eines böswilligen Benutzers) kann ganz einfach sehen, was läuft und welche ID es hat, was einen Angriff erleichtert, wenn der Angreifer eine andere Schwachstelle kennt, die er nutzen kann.
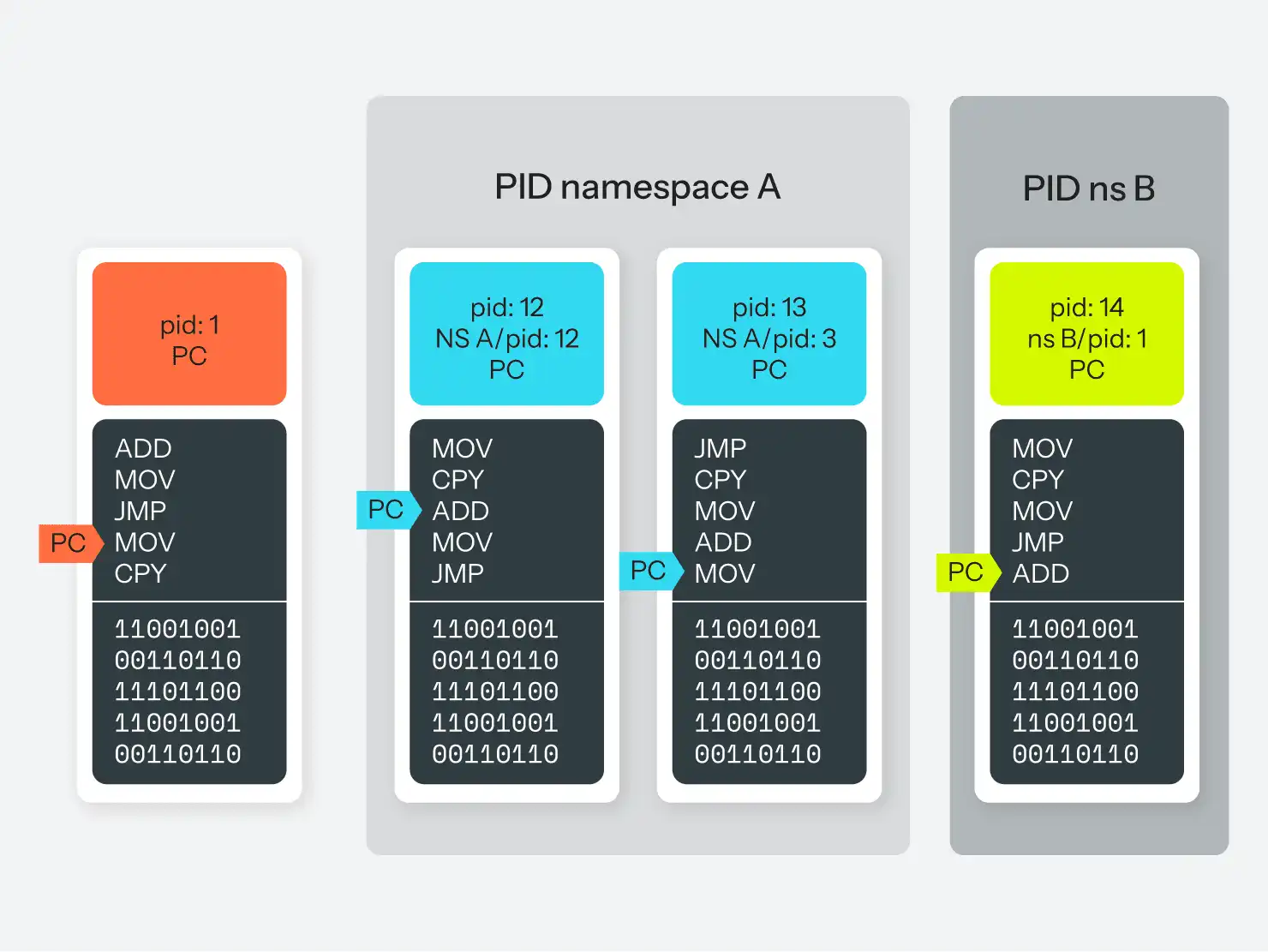
PID-Namensräume werden eingeführt. PID-Namespaces sind im Wesentlichen das, was der Name schon sagt: Sie sind ein separater Namespace für Prozess-IDs. Wenn Sie einen neuen PID-Namespace erstellen, geben Sie einen Prozess an, der PID 1 in diesem Namespace sein wird. Das könnte eine weitere Instanz Ihres Init-Programms sein (systemd im obigen Beispiel), oder ein beliebiger Prozess. Dieser Prozess mag als PID 345 im "globalen" Namespace bekannt sein, aber er ist auch als PID 1 in seinem "scoped" Namespace bekannt. Wenn er sich dann von einem anderen Prozess abspaltet, erhält dieser Prozess ebenfalls zwei PIDs: 346 im übergeordneten Namespace und 2 in seinem "scoped" Namespace.
Allerdings, und das ist der wirklich wichtige Teil, wird dieser Prozess nicht über beide PIDs Bescheid wissen. Er läuft in einem Namespace, in dem es nur 2 Prozesse gibt, und er kennt sich selbst als PID 2. Das ist die einzige PID, die er kennt, und wenn er das Betriebssystem um eine Liste aller Prozesse auf dem System bittet, wird er nur diese 2 in seinem Namespace sehen (Lüge!). Er kann keine Kommunikation mit einem Prozess außerhalb seines Namespace aufnehmen. Er weiß nicht einmal, dass sie existieren. Ein Prozess aus dem Parent-Namespace kann jedoch einen Prozess im Child-Namespace sehen und eine Kommunikation mit ihm einleiten.
Wenn Sie sich das nur schwer vorstellen können, finden Sie in Abbildung 4 eine visuelle Version.
Da ein Großteil der Prozessverwaltung über das /proc-Pseudodateisystem verwaltet wird, kann es natürlich zu Problemen kommen, wenn der Prozess-Namespac nicht mit dem Mount-Namespace übereinstimmt. Ob das gut oder schlecht ist, hängt davon ab, wie Sie es einrichten.
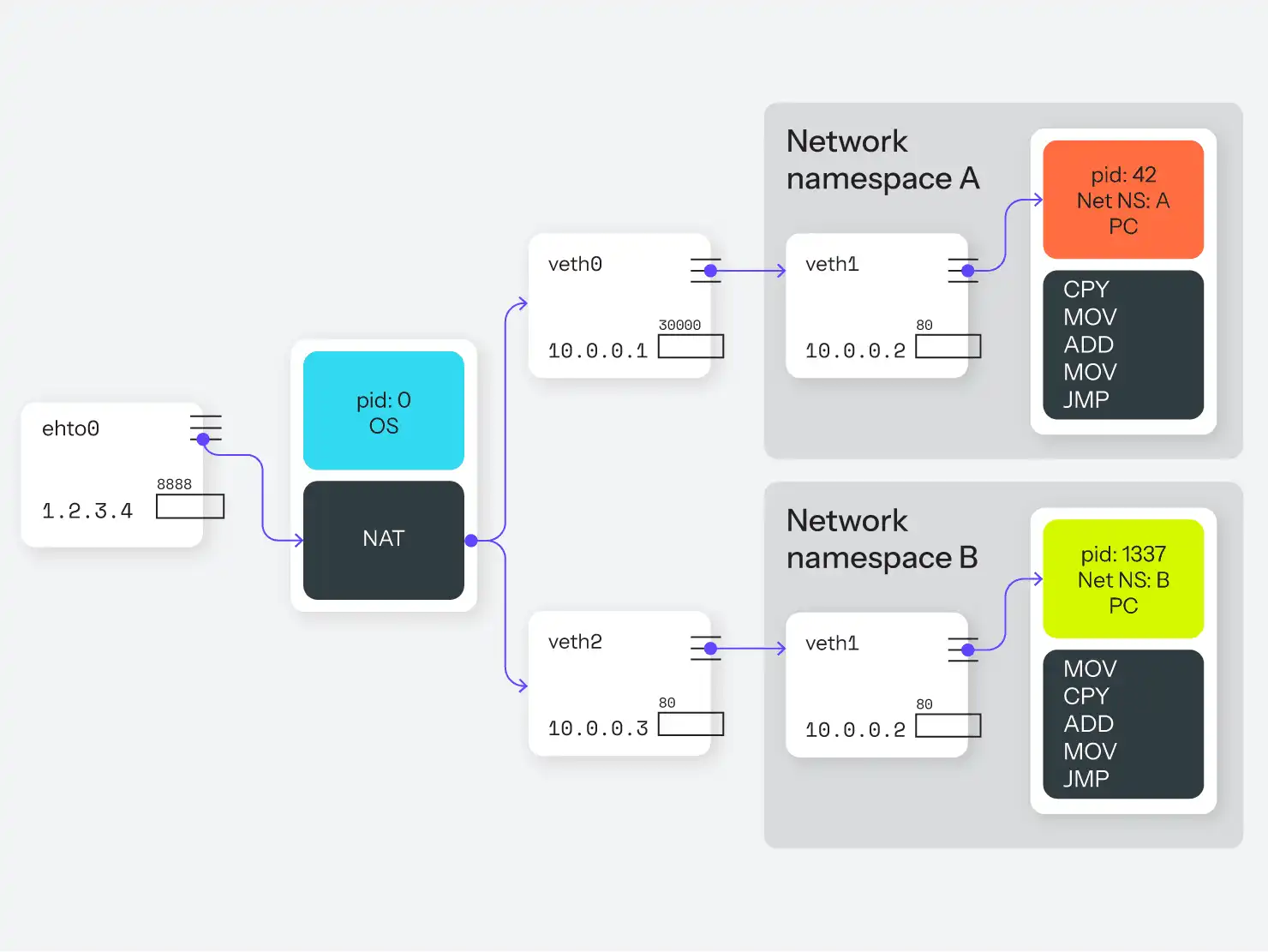
Netzwerk-Namespace
Ein Netzwerk-Namespace ist dem Mount-Namespace insofern ähnlich, als er die Erstellung einer völlig separaten Sammlung von Ressourcen ermöglicht. In diesem Fall handelt es sich bei den Ressourcen um Netzwerkgeräte und nicht um einen Dateibaum. Im Gegensatz zu den Mount-Namensräumen können diese Ressourcen jedoch nicht gemeinsam genutzt werden; ein Netzwerkgerät kann sich immer nur in einem einzigen Namespace befinden. Darüber hinaus können physische Netzwerkgeräte (die einer physischen Ethernet-Karte oder einem WiFi-Adapter entsprechen) nur im Root-Namespace verbleiben, und so beginnt ein neuer Netzwerk-Namespace mit keinerlei Geräten und somit auch keiner Verbindung zu irgendetwas. (Technisch gesehen verfügt er über ein Loopback-Gerät, aber auch das ist standardmäßig deaktiviert).
Linux kann jedoch eine beliebige Anzahl von virtuellen Netzwerkgeräten (Lügen!) erstellen, die in einem Netzwerk-Namespace platziert werden können. Virtuelle Netzwerkgeräte können auch in Paaren erstellt werden, die im Wesentlichen von einem zum anderen führen, sogar über eine Namespace-Grenze hinweg.
Das ermöglicht diese clevere Täuschung:
- Erstellen Sie einen neuen Netzwerk-Namespace, A.
- Erstellen Sie ein Paar virtueller Netzwerkgeräte, die zusammengeschaltet sind. Wir nennen sie
veth0undveth1. - Behalten Sie
veth0im Root-Namespace, und verschieben Sieveth1in den neuen Netzwerk-Namespace. - Weisen Sie
veth0die IP-Adresse 10.0.0.1 undveth1die Adresse 10.0.0.2 zu. Diese beiden Netzwerkgeräte können nun eine Verbindung zueinander herstellen, da sie vom Kernel zusammen gepeert werden. - Weisen Sie diesem neuen Netzwerk-Namespace einen oder mehrere Prozesse zu, zum Beispiel einen nginx-Prozess.
Dieser nginx-Prozess beginnt nun, den Port 80 auf veth1, Adresse 10.0.0.2, zu überwachen. Zurück im globalen Namespace richten wir Routing- und Firewall-Regeln ein (z.B. NAT), um Anfragen an Port 8888 an 10.0.0.2:80 weiterzuleiten. Das führt dazu, dass eingehende Anfragen an Port 8888 über veth0 an veth1 an Port 80 weitergeleitet werden, genau dorthin, wo nginx darauf wartet.
Siehe Abbildung 5 für die grafische Version.
Benutzer-Namespace
Schließlich der Namespace, der das i-Tüpfelchen auf dem Ganzen darstellt. Alle Prozesse haben zusätzlich zu ihrer PID einen zugehörigen Benutzer und eine Gruppe. Diese Benutzer- und Gruppenkennzeichnungen wirken sich wiederum auf die Zugriffskontrolle aus; ein Prozess kann z. B. den Prozess eines anderen Benutzers nicht zwangsbeenden, es sei denn, er ist im Besitz von root.
Mit Benutzer-Namensräumen kann nun jeder Prozess einen neuen Benutzer-Namespace erstellen, innerhalb dessen dieser Prozess einem beliebigen Benutzer gehört, einschließlich root. Das bedeutet, so wie ein Prozess eine PID innerhalb und eine PID außerhalb des Namespace haben kann, kann ein Prozess einen Benutzer innerhalb des Namespace haben, der sich von seinem Benutzer außerhalb des Namespace unterscheidet. Und sein In-Namespace-Benutzer kann root sein, was ihm root-Zugriff auf alle anderen Prozesse im Namespace gibt, selbst wenn er nur ein gewöhnlicher Benutzerprozess im Parent-Namespace ist. Wenn ein Prozess im Parent-Namespace Root-Besitzer ist, kann er darüber hinaus eine Zuordnung von Benutzern im Parent-Namespace zu Benutzern im Child-Namespace definieren.
Wenn dieser Absatz Ihr Gehirn zum Umkippen gebracht hat, sind Sie nicht allein. Abbildung 6 macht es Ihnen vielleicht leichter zu folgen.

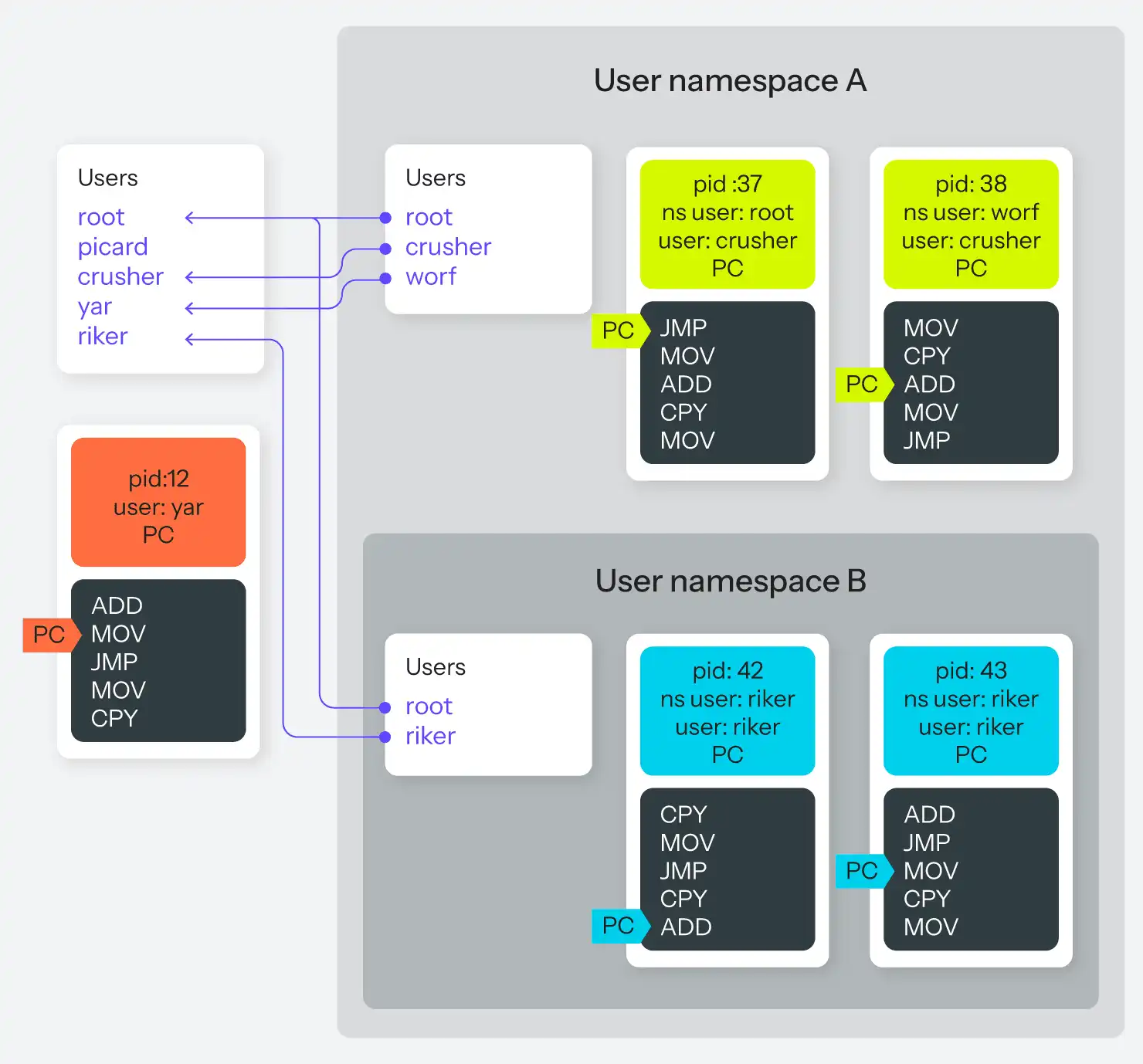
Das Wichtigste dabei ist, dass es jetzt für einen Prozess möglich ist, die oberste Root-Macht über eine ausgewählte Gruppe anderer Prozesse zu haben, anstatt alles oder nichts über das gesamte System. Es gibt noch viele andere Möglichkeiten, Prozesse mit internen und externen Benutzern auszustatten, aber die selektive Wurzel ist die wirklich lustige Variante.
Kontrollgruppen
Bei dem anderen Teil des Puzzles geht es nicht so sehr um Täuschung, sondern darum, den Scheduler zu optimieren. Wie bereits erwähnt, schaltet der Kernel über den Scheduler von Zeit zu Zeit verschiedene Prozesse in und aus der CPU, um Multitasking zu simulieren. Wie entscheidet er, welche Prozesse mehr oder weniger Zeit auf ihrem CPU-Timeshare verbringen dürfen? Es gibt viele automatisierte Möglichkeiten, die Zeit mehr oder weniger gerecht zu verteilen, aber sie alle gehen davon aus, dass kein bestimmter Prozess besonders gierig sein wird. Schließlich kann sich ein Programm auf triviale Weise in mehrere Prozesse aufteilen und so zusätzliche Stücke des CPU-Kuchens abbekommen.
Das Gleiche gilt für die Speichernutzung. Der Computer verfügt über eine festgelegte Menge an physischem Speicher, und wenn Programme diesen mit Code und Daten füllen, beginnt das Betriebssystem damit, scheinbar weniger genutzte Teile des Speichers auf einen Speicherplatz auf der Festplatte auszulagern (je nach Implementierung "swap device" oder "swap file" genannt). Aber das bedeutet immer noch, dass ein gieriges oder ineffizientes Programm andere Prozesse verdrängen kann, indem es einfach viel Speicher auf einmal anfordert.
Kontrollgruppen sind die Linux-Antwort auf dieses Problem. Kontrollgruppen schaffen eine parallele Hierarchie von Prozessen, unabhängig von der Erstellungshierarchie, die von Namespaces verwendet wird. Prozesse können dann mit einem einzigen Blatt in dieser Hierarchie verbunden werden.
Jeder Knoten in dieser Hierarchie kann mit einem oder mehreren "Controllern" verbunden sein. Derzeit sind etwa ein Dutzend Controller implementiert, von denen einige nur die Ressourcennutzung verfolgen, andere sie begrenzen und wieder andere beides tun. Die beiden wichtigsten Controller für unsere Zwecke sind CPU und Speicher, die die gesamte CPU-Nutzung oder die Speichernutzung eines Prozessbaums begrenzen können.
So können wir zum Beispiel eine Kontrollgruppe von Prozessen erstellen, ihr alle nginx-Prozesse zuweisen und ihr einen Controller zuweisen, der ihre CPU-Nutzung auf 25 % begrenzt und sie auf zwei der vier CPU-Kerne des Computers beschränkt. Dann können wir eine weitere Kontrollgruppe erstellen, ihr den MariaDB-Prozess zuweisen und ihn auf 100% einer der verbleibenden CPUs beschränken. Jetzt ist es zwar immer noch möglich, dass eine fehlerhafte Abfrage MariaDB dazu bringt, die gesamte verfügbare CPU-Zeit zu verbrauchen, aber die laufenden nginx-Prozesse werden davon nicht beeinträchtigt. Sie sind verschiedenen CPUs und Nutzungsbeschränkungen zugeordnet, so dass MariaDB zwar langsamer wird, nginx aber weiterläuft, ebenso wie alle anderen Prozesse in der Top-Level-Steuerungsgruppe. (Siehe Abbildung 7.)

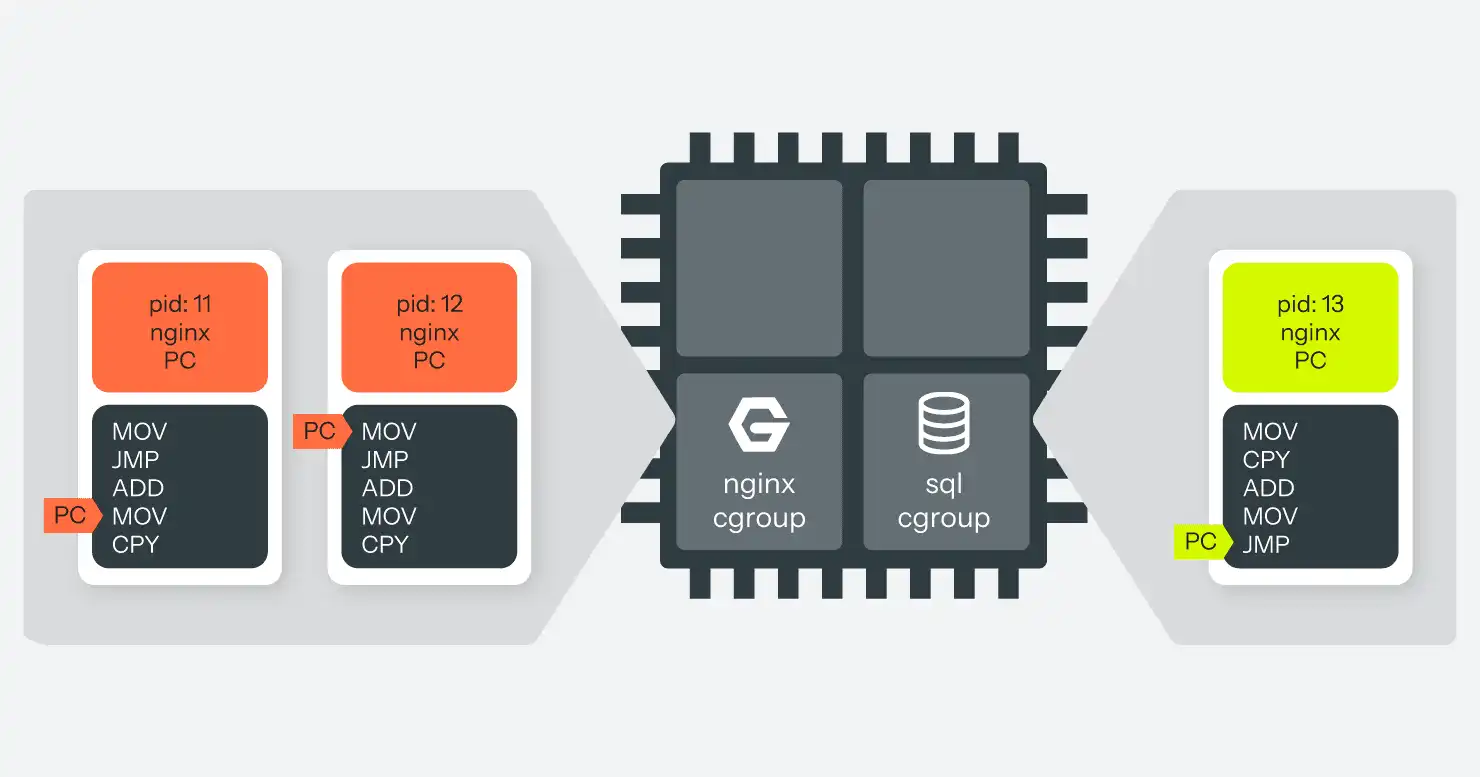
Ein Prozess in einer Kontrollgruppe weiß immer noch, dass er in einer Kontrollgruppe ist und dass er nur einen Teil der gesamten Systemressourcen erhält. Solange der Prozess jedoch nicht im Besitz von root ist, kann er diese Konfiguration nicht ändern.
Überlappende Namespaces
Ein wichtiger Punkt ist, dass unter Linux, im Gegensatz zu den meisten älteren Unixen, jeder dieser Namensräume und Kontrollgruppen getrennt ist. Es ist durchaus möglich, dass sich die Prozesse 2, 3 und 4 einen Mount-Namespace teilen, während sich Prozess 3 auch in einem User-Namespace und Prozess 4 in einem UTS-Namespace befindet. Und dann können Sie die Prozesse 2 und 4 zusammen in eine sehr CPU-begrenzte cgroup setzen, während Prozess 3 so viel CPU-Zeit bekommt, wie er will.
Eine solche Konfiguration ist zwar möglich, aber auch recht komplex. Es könnte zwar eine faszinierende Funktionalität entstehen, aber auch ein völlig unbrauchbares Durcheinander. In der Regel werden nur einige wenige Namespacefunktionen verwendet, um sehr spezifische Segmentierungsziele zu erreichen.
Die praktischste und am besten anwendbare Kombination ist jedoch "all of the above!", wie in Abbildung 8 zu sehen ist. Nehmen wir an, wir können nun eine Gruppe von Prozessen erstellen, die:
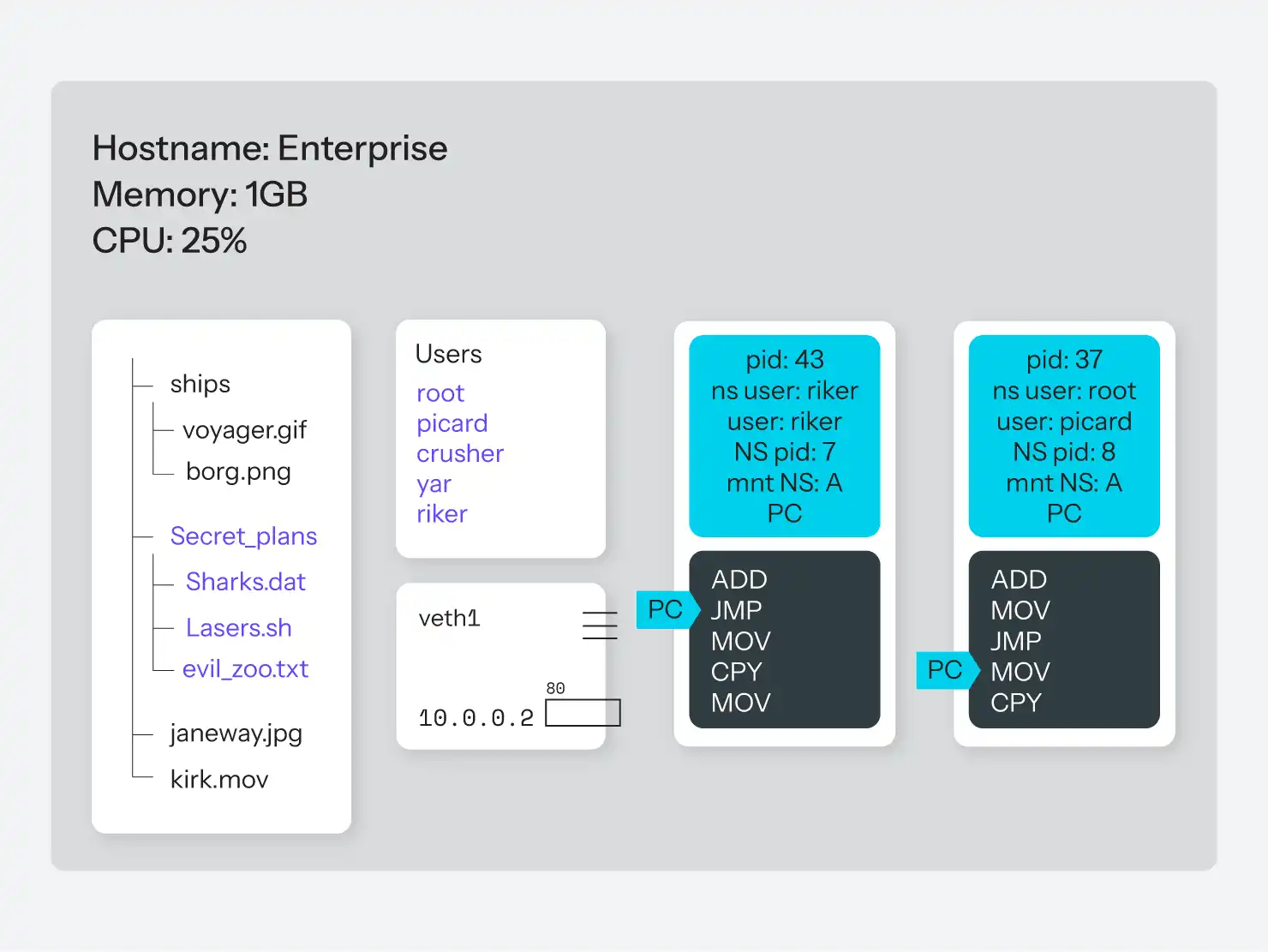
- nur voneinander wissen, nicht aber von anderen Prozessen auf dem System.
- Einen Prozess haben, der denkt, er habe Root-Zugriff, und die anderen Prozesse denken, er sei Root, aber er hat nicht Root auf dem ganzen System.
- ihren eigenen Dateibaum haben, von/bis unten, und keine Möglichkeit haben, auf andere Dateisysteme zuzugreifen.
- Sie haben ihren Hostnamen.
- Sie haben ihre IP-Adresse, von der sie glauben, dass sie auf ihr läuft, mit ihren eigenen Ports und sogar ihren eigenen IP-Routing-Regeln für den Netzwerkzugang.
- Sie haben keine Möglichkeit, auf Prozesse außerhalb dieser Gruppe zuzugreifen oder überhaupt zu wissen, dass es Prozesse außerhalb dieser Gruppe gibt.
- Sie verbrauchen zusammen nicht mehr als 25 % der CPU-Zeit und nicht mehr als 256 MB des Arbeitsspeichers.
Was ist der Unterschied zwischen einem Prozess in dieser Gruppe und einem Prozess, der auf seinem gesamten Computer läuft? In der Praxis sehr wenig. Es bietet fast alle Isolationsmöglichkeiten virtueller Maschinen, aber mit nur einem winzigen Bruchteil des Overheads; der einzige Overhead sind Nachschlagetabellen für den Kernel, um zu wissen, welche Lügen er welchem Prozess mitteilt. Die einzige Einschränkung ist, dass immer noch nur eine einzige Kernel-Instanz läuft und alles kontrolliert.
Diese Kombination von Lügen ist so häufig gewünscht, dass sie sogar einen gemeinsamen Namen hat: Container.
Letztendlich ist das alles, was ein "Container" ist: Es ist eine Kurzbezeichnung für "alle Namespaces gleichzeitig verwenden, um Prozesse so zu täuschen, dass sie denken, sie würden auf ihrem eigenen Computer laufen, obwohl sie es nicht tun." Und das ist im Endeffekt extrem mächtig.
Container-Abstraktionen
Während der Kernel alle möglichen APIs anbietet, um Namespaces und Prozesse auf einer feinkörnigen Ebene zu manipulieren, ist das oft nicht besonders hilfreich, wenn man versucht, ein System auf einer grobkörnigeren Ebene zu bauen, wie etwa einen Makro-"Container". Wie in der Programmierung üblich, sind daher verschiedene andere Werkzeuge entstanden, die diese Low-Level-APIs in einfacher zu verwendende Higher-Level-APIs abstrahieren. Es gibt viele solcher Systeme, die in einer Vielzahl verschiedener Sprachen geschrieben wurden. Jede Sprache, die in der Lage ist, libc-Befehle auszugeben, kann funktionieren.
Es gibt viele solcher Abstraktionswerkzeuge, die alle mehr oder weniger das Gleiche tun. Einige, von denen Sie vielleicht schon gehört haben, sind unten aufgeführt.
- LXC (für LinuX Containers, geschrieben in C): https: //linuxcontainers.org/
- Docker (geschrieben in Go): https: //www.docker.com/
- lmctfy (kurz für Let Me Contain That For You): https: //github.com/google/lmctfy/
- Rocket / CoreOS: https: //github.com/coreos/rocket
- Vagga (geschrieben in Rust): https: //github.com/tailhook/vagga
- Bocker (geschrieben in Bash): https: //github.com/p8952/bocker
Eine noch umfangreichere Liste findet sich auf https://dogger.io/, und zumindest Bocker ist einen Blick wert, allein um zu sehen, wie einfach ein solches System sein kann.
Docker ist bei weitem das populärste dieser Container-Verwaltungstools, obwohl es weder das erste noch das neueste ist. Es war einfach die neue und coole Option, als der Markt beschloss, dass er "bereit" für Container war. Ursprünglich wurde es als zusätzliche Schicht über LXC gebaut, obwohl es inzwischen seine LXC-Abhängigkeit durch seine Bibliothek namens runC ersetzt hat.
Obwohl LXC etwas weniger anspruchsvoll ist, als die meisten Endbenutzer und Systemadministratoren es wünschen, ist es eine der leistungsfähigsten Optionen. Es gibt auch Bindungen, um seine Fähigkeiten mit einer Vielzahl von Sprachen, darunter C, Python, Go und Haskell, weiter zu automatisieren.
Unabhängig vom Tool handelt es sich bei allen lediglich um Abstraktionen, die besagen: "Starte einen Prozess, erstelle eine Reihe von Namespaces auf diesem Prozess und hänge dieses Dateisystem in ihn ein." Diese Routine wird im Allgemeinen als "Starten" eines Containers bezeichnet.
Orchestrierung
Eine weitere Abstraktionsebene, die häufig verwendet wird, ist die "Orchestrierung". Die Orchestrierung ist eine weitere Abstraktionsschicht über der Container-Software. Im Allgemeinen handelt es sich dabei einfach um Code, der das Kopieren von Dateisystem-Images zwischen mehreren Computern koordiniert, die Container-Software auf jedem Computer aufruft und ihr mitteilt, einen Container zu starten, und dann die Container-Software anweist, wie dieser Container zu konfigurieren ist (nämlich welche Details für die verschiedenen Namespaces und cgroups eingerichtet werden sollen).
In der Praxis ist es üblich, mehrere Container im Tandem zu verwenden, die so kommunizieren, als ob sie über ein Netzwerk laufen würden, obwohl sie in Wirklichkeit nur verschiedene Prozesse auf demselben Computer sind. Dies manuell einzurichten ist meist einfach, aber sehr mühsam. Orchestrierungssysteme automatisieren die Aufgabe, mehrere Container zu erstellen und sie mit einer schöneren Syntax zu verbinden. Kubernetes ist im Moment der große Name in diesem Bereich, aber es gibt noch viele andere Beispiele, darunter auch Upsun selbst.
Read-Only-Container
Es ist sehr üblich, dass Container-Implementierungen die Verwendung von schreibgeschützten Dateisystemen fördern oder erfordern. Dafür gibt es eine Reihe von Gründen. Zum einen ist es einfach sehr effizient. Linux ist durchaus in der Lage, einen Schnappschuss eines Dateisystems zu machen und eine einzelne Dateidarstellung davon zu erzeugen, die dann auf einem anderen Dateisystem leben kann. (Denken Sie an "ISO"-Dateisystemabbilder für CDs und DVDs. Viele andere ähnliche Formate sind verfügbar.) Bei der Erstellung eines Containers ist es daher sehr einfach, seine Prozesse in einen Mount-Namespace zu legen und dann diese Dateisystem-Image-Datei als Root innerhalb des Mount-Namespace einzuhängen. Nun wird jeder Prozess im Container, d.h. in diesem Mount-Namespace , dieses Dateisystem als das gesamte Universum sehen.
Nützlich ist es jedoch, mehrere Kopien dieses Containers zu erstellen. Zwei verschiedene Container (d.h. Mount-Namensräume) können das gleiche Dateisystem-Image als Root-Mountpunkt verwenden. Wenn es jedoch beschreibbar ist, wirft das alle möglichen Fragen darüber auf, wie man Schreibvorgänge zwischen ihnen synchronisiert. Was passiert, wenn ein Prozess in einem Container eine Änderung vornimmt, die für einen Prozess im anderen Container wichtig ist? Die Antwort lautet: "Es ist chaotisch."
Wenn das Dateisystem jedoch schreibgeschützt ist, werden nicht nur solche Synchronisationsprobleme vermieden, sondern es bedeutet auch, dass das Betriebssystem nur eine einzige Kopie davon benötigt. Zwei, drei oder 30 Mount-Namespaces (Container) können dasselbe 10-GB-Dateisystem-Image in ihr Root-Verzeichnis mounten, wobei das Betriebssystem die Daten nur einmal lesen muss. Und da es nicht das gesamte Dateisystem in den Speicher laden muss, bedeutet das, dass der Speicher-Overhead für das Starten von 30 Containern mit demselben 10-GB-Dateisystem... ein paar KB an Buchhaltungsdaten innerhalb des Betriebssystems ist, um seine Lügen gerade zu halten.
Nehmt das, virtuelle Maschinen!
Portabilität von Containern
Das Marketing rund um Container verweist oft auf die Schiffscontainer, die die Frachtindustrie revolutionierten, indem sie Kisten in Standardgröße schufen, in die klobigere Gegenstände hineingepackt werden konnten, die dann auf Schiffen, Lastwagen und in Flugzeugen ordentlich gestapelt werden konnten. In der Werbung wird oft behauptet, dass ein Container ein Standardformat ist, das dann "überall" eingesetzt werden kann, genau wie ein Schiffscontainer.
Dieses Marketing ist leider nicht nur falsch, sondern völlig verkehrt. Es ist eine weitere Lüge.
Im Allgemeinen sind die Dateisystem-Snapshots oder "Images", die wir zuvor besprochen haben, so konfiguriert, dass sie nur korrekt funktionieren, wenn sie von einer bestimmten Container-Abstraktionsbibliothek geladen werden. Sie enthalten oft nicht nur ein Dateisystem, sondern auch Metadaten, die von der Abstraktionsbibliothek verwendet werden, um zu entscheiden, welche Namespaces und C-Gruppen konfiguriert werden sollen. Soll dieser Container einen Netzwerk-Namespace haben, der ausgehenden Zugriff erlaubt? Auf welche Ports? Welche zusätzlichen Dateisysteme sollen eingebunden werden? All diese Metadaten liegen in einem bibliotheksspezifischen Format vor. Ein von Docker erstelltes Image funktioniert nicht auf Vagga oder LXC und umgekehrt.
Wenn sie also nicht portabel sind, was ist dann der Vorteil?
Der Vorteil liegt im Inneren. Fast jedes sinnvolle Programm ist auf Hunderte von anderen Programmen und Bibliotheken angewiesen. Diese werden in der Regel von der Linux-Distribution in bekannten festen Versionen installiert... oder zumindest in weitgehend bekannten und festen Versionen. Sie werden ständig gepatcht, wenn Fehler und Sicherheitslücken behoben (oder eingeführt) werden. Wenn die Leute davon sprechen, dass "die Produktion mit dem Staging übereinstimmen muss", dann meinen sie damit die lange Kombination möglicher Versionen verschiedener Bibliotheken. Selbst ein einfaches Hallo-Welt-PHP-Skript stützt sich auf Apache oder Nginx, PHP-FPM, die PHP-Engine selbst, PHP-Erweiterungen, C-Bibliotheken, die von diesen Erweiterungen verwendet werden, und wahrscheinlich ein Dutzend anderer Dinge. In einer idealen Welt würden die verschiedenen Kombinationen von Bibliotheken gut funktionieren, aber wir alle wissen, dass die Realität selten ideal ist, und es kann wahnsinnig zeitaufwändig sein, Fehler zu finden, die durch unterschiedliche Kombinationen entstehen.
Mit Containern haben Sie die Möglichkeit, all diese Bibliotheken in einem Dateisystem-Snapshot zu bündeln. Fast immer wird ein Programm (Prozess) ein anderes starten, indem es das Betriebssystem fragt: "Starte einen neuen Prozess mit dieser Datei auf der Festplatte." Wenn die "Festplatte", von der es weiß, ein Mount innerhalb eines Mount-Namespace ist, und dieser Mount eine Dateisystem-Image-Datei ist, können Sie nun die genaue Version jeder Abhängigkeit, die Sie in dieses Dateisystem-Image einfügen, genau kontrollieren. Die einzige bemerkenswerte Ausnahme ist der Kernel selbst. Alles andere kann zusammen mit Ihrem Programm ausgeliefert werden.
Es ist, als würde man seinen gesamten Computer statisch verlinken! Das heißt, ja, Sie müssen wieder kompilieren, selbst wenn Sie in einer Skriptsprache wie PHP oder Node schreiben.
Mit Containern haben Sie die Möglichkeit, nicht Ihre Anwendung, sondern Ihre Anwendung und alle ihre Abhängigkeiten in einer bestimmten Version auszuliefern. Wenn Sie diesen Container dann auf einen anderen Computer laden, wird er einen PID-Namespace , einen Mount-Namespace , einen Benutzer-Namespace usw. um die gesamte von Ihnen bereitgestellte Sammlung von Abhängigkeiten herum starten und (möglicherweise) cgroups verwenden, um alle diese Prozesse auf einen Teil der Ressourcen auf der tatsächlichen Hardware zu beschränken. Dieses Dateisystem-Image kann auch relativ klein sein, da Sie wissen, welche Werkzeuge Sie benötigen und nur diese wenigen einbeziehen können. Ihre Anwendung weiß nicht, ob sie in einem Container läuft oder nicht, und es sollte ihr auch egal sein.
Das ist auch der Grund, warum Sprachen, die zu einer einzigen ausführbaren Datei kompiliert werden, wie Go (oder Rust, je nach Ihren Einstellungen), gut für Container-Setups geeignet sind. Sie bündeln bereits alle ihre Abhängigkeiten in einem einzigen Programm, so dass das "Dateisystem voller Abhängigkeiten", das Sie benötigen, trivial klein ist: oft ist es nur das ausführbare Programm selbst.
Da der Overhead eines jeden Containers so gering ist, ist die Ausführung von 50 Kopien eines Containers nicht teurer als die Ausführung von 50 Kopien desselben Programms ohne einen Container. Mit cgroups ist es möglicherweise billiger und auf jeden Fall einfacher, zu verhindern, dass sie aneinander stoßen. Dies steht im Gegensatz zu VMs, bei denen jede Instanz nicht nur ein paar laufende Prozesse und etwas Buchhaltung hinzufügt, sondern komplett duplizierte Kopien des Linux-Kernels, aller User-Space-Tools und des Programms, das Sie ausführen wollen.
Container bei Upsun
Es gibt zahlreiche Möglichkeiten, diese neu gewonnene Flexibilität einzurichten, von denen viele nur in bestimmten Situationen anwendbar sind. Als praktisches Beispiel wollen wir uns ansehen, wie unsere Container-Implementierung hier bei Upsun Container für Kunden verwaltet und wie sie sich von Docker unterscheidet, das weithin für die lokale Entwicklung verwendet wird.
Upsun behandelt Container-Images wie ein Build-Artefakt. Das heißt, dass das, was sich im Git-Repository Ihres Projekts befindet, nicht in der Produktion eingesetzt wird. Vielmehr überprüfen wir, was in Git vorhanden ist und führen dann Ihren "Build-Hook" aus der upsun/config. yaml-Datei in Ihrem Repository aus. Das kann das Herunterladen von Abhängigkeiten mit Composer, npm, Go-Modulen usw. beinhalten, aber auch das Kompilieren von Sass- oder Less-Dateien, das Minimieren von JS-Skripten oder andere Build-Befehle, die Sie wünschen. Das Ergebnis ist lediglich ein "Haufen Dateien auf der Festplatte" auf einem Build-Server.
Dieses "Bündel von Dateien auf der Festplatte" wird dann in eine Squashfs-Datei komprimiert. Squashfs ist ein komprimiertes, schreibgeschütztes Dateisystem, das selbst eine einzelne Datei auf der Festplatte ist, ähnlich wie ein ISO-Image. Dieses "Anwendungsimage" wird dann zusammen mit den aus Ihren Konfigurationsdateien abgeleiteten Metadaten auf eine der vielen VMs hochgeladen, die wir betreiben.
Auf der VM stellen wir dann einen Container zusammen. Upsun verwendet LXC anstelle von Docker, da es mehr Flexibilität auf niedriger Ebene bietet, auf der wir unsere eigene Koordinations- und Orchestrierungssoftware einsetzen. Der erste Schritt besteht darin, einen neuen LXC-Container zu erstellen, der LXC anweist, einen neuen Init-Prozess (wir verwenden runit) mit seinen Mount-, PID-, UTS-, Netzwerk- und Benutzernamensräumen zu erstellen.
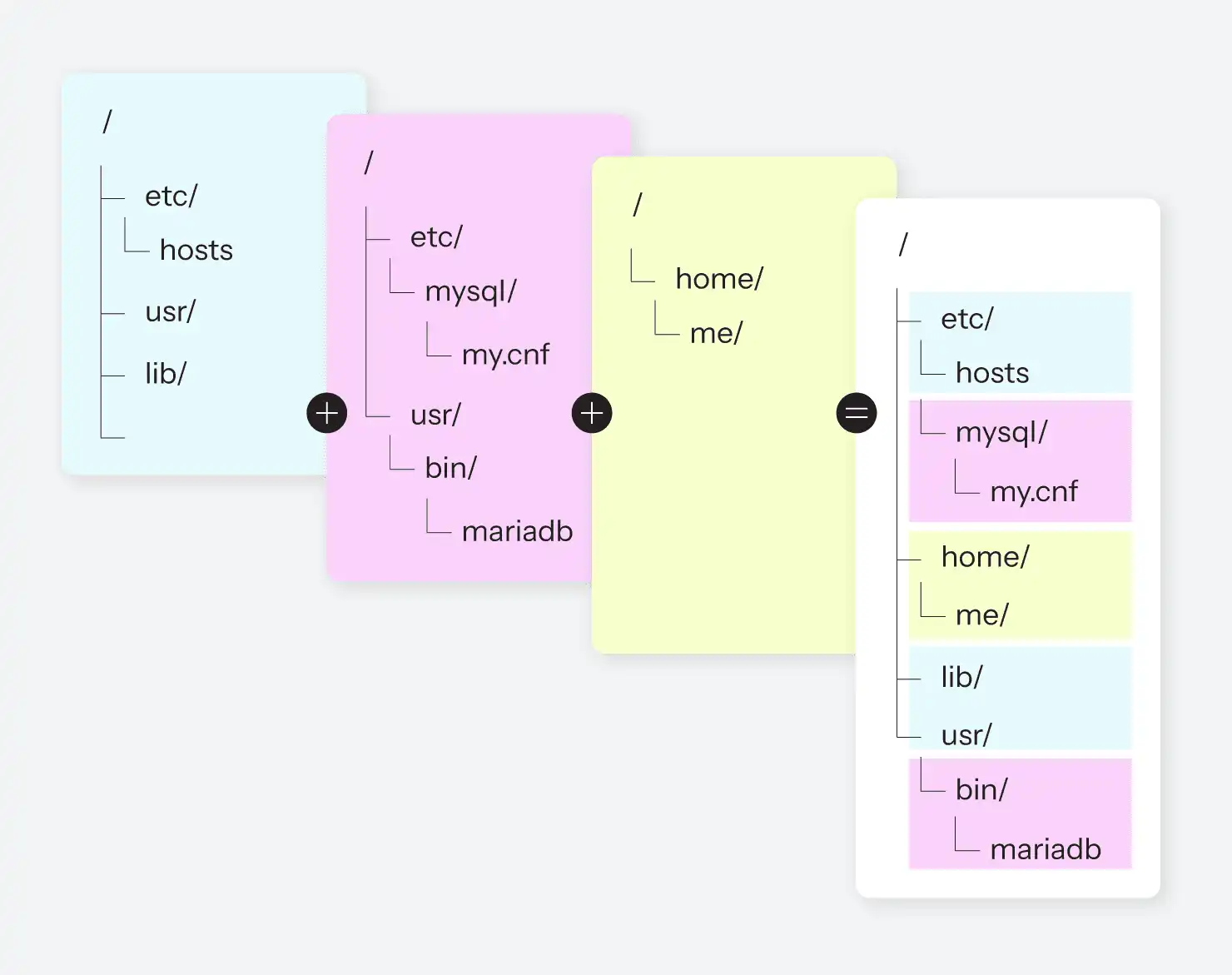
In diesem Mount-Namespace mounten wir dann ein Basis-Image, wie es durch die oben genannten Metadaten definiert ist. Das Basis-Image ist eine squashfs-Datei, die eine minimale Debian-Installation mit einer vom Benutzer ausgewählten Sprachlaufzeit und -version enthält: PHP 8.4, Python 3.12, oder Go 1.18, zum Beispiel. Das ist nun das Dateisystem, das jeder Prozess im Container (d.h. in all diesen Namensräumen) sehen wird. Und da es sich um ein standardmäßiges, gemeinsames Image handelt, können Dutzende von Containern auf derselben VM fast ohne Overhead ausgeführt werden.
Als Nächstes wird das vom Benutzer bereitgestellte Anwendungsimage an einem Standardspeicherort gemountet, nämlich /app. Es enthält den gesamten Anwendercode, der natürlich von Projekt zu Projekt variiert, aber in der Regel viel kleiner ist als der gesamte Rest des gemeinsamen Betriebssystem-Images. Schließlich definieren die Konfigurations-Metadaten auch verschiedene beschreibbare Mountpunkte; diese sind Teil eines beschreibbaren Netzwerk-Dateisystems, das für jeden Container offengelegt und in den Dateibaum des Containers eingehängt wird, wo auch immer die Konfiguration vorgibt, dass sie eingehängt werden sollen. Das Ergebnis ist ein Dateisystem, das aus einem allgemein genutzten squashfs-Image, einem anwendungsspezifischen squashfs-Image und null oder mehr Netzwerk-Dateie-Mounts besteht.
Nachdem das Dateisystem zusammengestellt wurde, ist der nächste Schritt die Einrichtung von Prozessen. Wenn eine Anwendungslaufzeit eine zusätzliche Konfiguration erfordert, werden diese Konfigurationsdateien auf einer kleinen, beschreibbaren Ramdisk erzeugt (wiederum beschränkt auf diesen Mount-Namespace). Bei PHP werden zum Beispiel die Datei php.ini und die PHP-FPM-Konfiguration in dieses Verzeichnis generiert. Bei einem Ruby-Container wären es andere Dateien. Alle Container enthalten auch Nginx, so dass die Datei nginx.conf ebenfalls dort abgelegt wird. Das Basis-Image enthält symbolische Links zu den Verzeichnissen, in denen sich die Konfigurationsdateien befinden, so dass die Laufzeitumgebung sie finden kann. (Siehe Abbildung 9.)

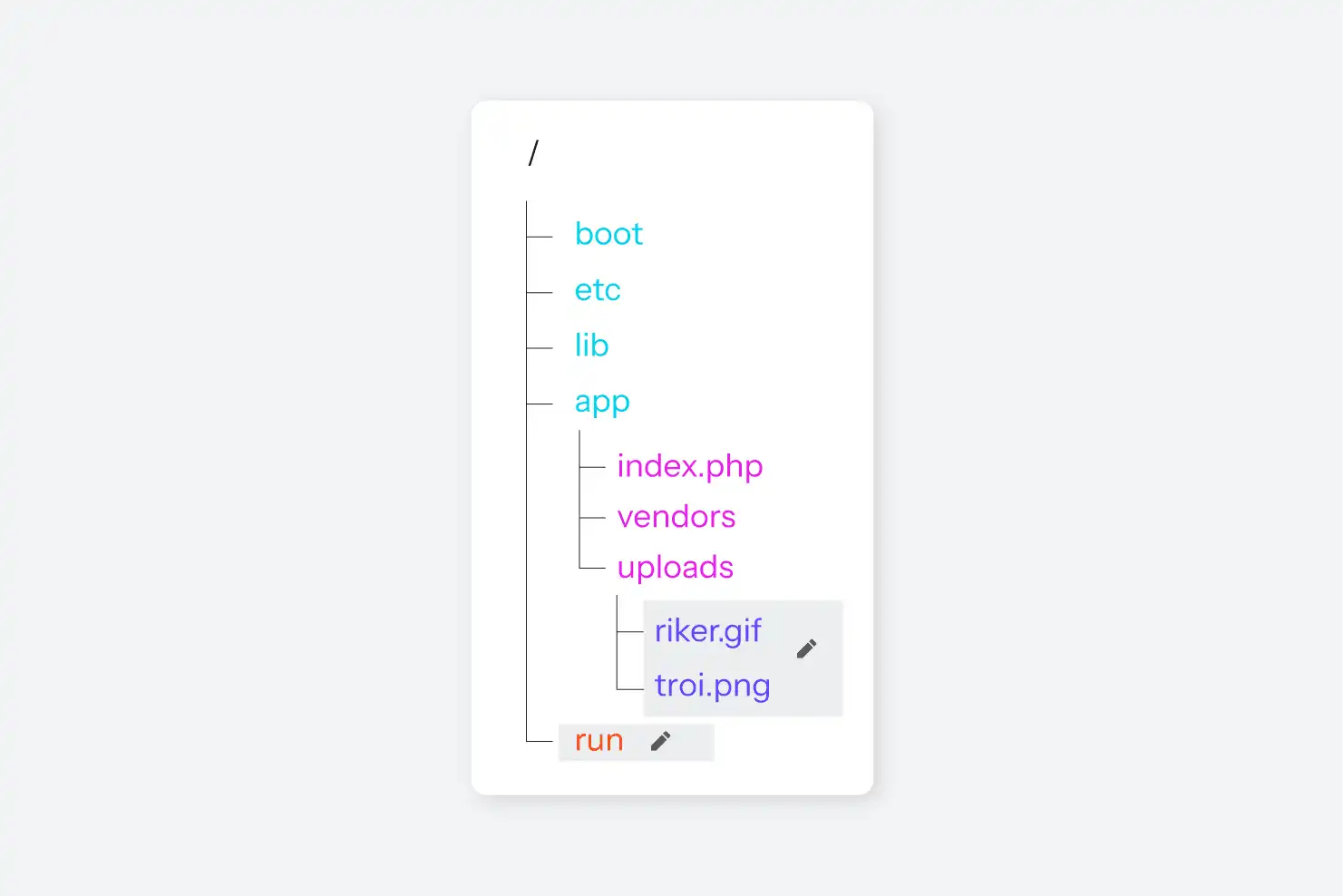
LXC erlaubt es Prozessen aus dem übergeordneten Namespace, einen Container aufzurufen und einen beliebigen Befehl innerhalb des Containers (innerhalb aller entsprechenden Namespaces) auszuführen, wodurch die gesamte Kontrolllogik aufgebaut wird. Der letzte Schritt besteht darin, dem Init-Prozess innerhalb des Containers mitzuteilen, dass er die wenigen Prozesse starten soll, die er benötigt: SSH, nginx und PHP-FPM, wenn es sich um einen PHP-Container handelt. Ein ps axf-Lauf innerhalb eines dieser Container zeigt nur die wenigen Prozesse an, die Teil des PID-Namespace des Containers sind:
$ ps axf
PID TTY STAT TIME COMMAND
1 ? Ss 0:06 init [2]
72 ? Ss 0:06 runsvdir -P /etc/service log: .................................................................
78 ? Ss 0:00 \_ runsv ssh
105 ? S 0:00 | \_ /usr/sbin/sshd -D
20516 ? Ss 0:00 | \_ sshd: web [priv]
20518 ? S 0:00 | \_ sshd: web@pts/0
20519 pts/0 Ss 0:00 | \_ -bash
20605 pts/0 R+ 0:00 | \_ ps axf
79 ? Ss 0:00 \_ runsv nginx
99 ? S 0:00 | \_ nginx: master process /usr/sbin/nginx -g daemon off; error_log /var/log/error.log; -c /
104 ? S 0:00 | \_ nginx: worker process
80 ? Ss 0:00 \_ runsv newrelic
81 ? Ss 0:00 \_ runsv app
89 ? Ss 0:22 \_ php-fpm: master process (/etc/php/7.3/fpm/php-fpm.conf)Das war's. Auf der VM, auf der der Container läuft, werden Tausende von Prozessen laufen, aber innerhalb dieses PID-Namespace gibt es nur ssh, nginx und PHP-FPM für PHP 7.3, plus einige kleine Koordinationsprozesse, die runit verwendet. Der Kernel kennt diese Prozesse sowohl unter den oben genannten PIDs als auch unter einer anderen systemweiten PID, aber von innerhalb des Containers gibt es für uns keine Möglichkeit, herauszufinden, welche das sind, oder überhaupt zu wissen, dass es noch andere Prozesse gibt.
Schließlich weist die Koordinierungssoftware das Betriebssystem an, alle diese Prozesse in eine cgroup einzuteilen, um ihre kollektive CPU- und Speichernutzung zu beschränken. Der Grad der Einschränkung richtet sich nach der Größe des Projekts.
Damit ist die Anwendung selbst erledigt. Eine moderne Webanwendung besteht jedoch aus mehr als nur eigenständigen Skripten. Je nach Anwendung kann sie eine MySQL- oder MariaDB-Datenbank, MongoDB, eine Redis-Datenbank, Memcache, möglicherweise einen Warteschlangenserver und verschiedene andere Dinge enthalten. Dies wird durch die services.yaml-Datei im Repository gesteuert. Wenn in den services.yaml-Dateien steht, dass dieses Projekt einen MariaDB-Server, einen Elasticsearch-Server und einen Redis-Cache-Server benötigt, dann erstellt die Koordinierungssoftware drei weitere Container, einen für jeden dieser Dienste. Der Prozess ist im Wesentlichen derselbe wie für den Anwendungscontainer, außer dass es kein Anwendungsimage zu mounten gibt. Es gibt nur ein Basis-Image für den Dienst (MariaDB, Elasticsearch und Redis) und ein schreibbares Mount für die Datendateien des Dienstes. Ansonsten ist der Prozess identisch.
Da jeder dieser Container einen neuen Netzwerk-Namespace impliziert, ist keiner von ihnen standardmäßig in der Lage, mit der Außenwelt zu kommunizieren. Stattdessen werden virtuelle Netzwerkschnittstellen erstellt, die nur Whitelist-Verbindungen zwischen den Containern auf bestimmten Ports zulassen. Das bedeutet, dass der Anwendungscontainer mit dem virtuellen Port 3306 des MariaDB-Containers kommunizieren kann, aber mit keinem anderen Port. Und der MariaDB-Container hat keine Möglichkeit, mit dem Redis-Container oder einem anderen Container zu kommunizieren, der sich nicht zuerst mit ihm verbunden hat. Und so weiter.
Alles in allem ist der Aufwand für die Erstellung dieser vier Container (d. h. vier UTS-Namensräume, vier PID-Namensräume, vier Benutzernamensräume und vier Netzwerknamensräume) minimal, vielleicht ein oder zwei Sekunden. Verglichen mit der Zeit, die für das Starten der Prozesse selbst, das Kopieren des Anwendungsimages in die VM und die Buchhaltung der Koordinierungssoftware benötigt wird, ist dies ein Rundungsfehler.
Da Container so schnell sind, weil sie nur eine Nachschlagetabelle von Lügen sind, und weil der größte Teil des Dateisystems schreibgeschützt ist, ist es praktisch, neue Bereitstellungen auf dieselbe Weise zu behandeln: Man beendet einfach alle beteiligten Prozesse und startet sie neu. Aber wir können auch intelligenter vorgehen. Wenn sich beispielsweise nur der Anwendungscode geändert hat, muss keiner der Backend-Service-Container komplett beendet und neu gestartet werden. Lediglich die Dateiverbindungen des Anwendungscontainers werden aktualisiert und verweisen auf eine neue Version des Anwendungsimages. Steht eine neuere Version des Basis-Images zur Verfügung (z. B. eine neue Version von Node.js zur Fehlerbehebung) oder hat sich die Konfiguration geändert und erfordert nun eine neue Version (z. B. ein Upgrade von PHP 7.3 auf 7.4), wird der Anwendungscontainer vollständig beendet und mit dem neuen Basis-Image neu gestartet. In beiden Fällen brauchen die Service-Container nichts zu tun, bis sich ihre Konfiguration ebenfalls ändert.
Ein weiterer Vorteil der Nachschlagetabelle ist, dass die Erstellung mehrerer Kopien eines Containers nur minimale zusätzliche Zeit in Anspruch nimmt. Das Erstellen einer neuen Testkopie der gesamten Codebasis, der Dienste und allem anderen, ist einfach eine Frage des Erstellens weiterer Namespaces für den Kernel, über die er lügen kann, und des erneuten mounten der gleichen Dateisystem-Images in den neuen Mount-Namespace.
Upsun handhabt dies so, dass jeder Zweig in Git einer "Umgebung" entspricht, d.h. einer Reihe von Containern für die Anwendung und die zugehörigen Dienste. Jeder Zweig kann ein Anwendungsimage erzeugen, das dann in einen neuen Container (Namespace) mit geringem zusätzlichem Ressourcenverbrauch eingehängt werden kann.
Der knifflige Teil ist das beschreibbare Dateisystem für jeden Container. Das wird durch einen Copy-on-Write-Prozess auf Volume-Ebene gehandhabt, der konzeptionell dem Copy-on-Write-Verfahren von PHP für den Umgang mit Variablen im Speicher sehr ähnlich ist. Dies ermöglicht die Replikation der Daten in einen neuen Container (Mount Namespace) in im Wesentlichen konstanter Zeit, wobei die Daten geforkt werden, wenn sie im Laufe der Zeit verändert werden. Dieser Prozess wird jedoch unabhängig von Linux-Namespaces gehandhabt, so dass wir hier nicht näher darauf eingehen werden.
Bedenken Sie auch, dass der Linux-Kernel sehr, sehr gut darin ist, das Laden von Daten in den Speicher zu vermeiden, die er nicht braucht. Wenn es 100 Container in 100 Sets von Namespaces gibt, die 100 Kopien von nginx auf demselben schreibgeschützten Dateisystem-Image betreiben... Linux wird nicht 100 Kopien der Nginx-Binärdatei in den Speicher laden. Es wird die Teile der Binärdatei, die es braucht, einmal in den Speicher laden, und dann, wenn es jeden Prozess über seinen virtuellen Speicherplatz anlügt, wird es ihn auch darüber anlügen, dass es seine eigene Kopie des Anwendungscodes hat. Das bedeutet, dass 100 Kopien von nginx nicht 100 mal so viel Speicher benötigen, sondern vielleicht 25% mehr Speicher für die Daten jeder Instanz. (Die tatsächliche Menge variiert stark, je nachdem, wie viele Daten die Anwendung tatsächlich zur Laufzeit in Variablen speichert).
Das Ergebnis ist, dass eine einzige leistungsstarke VM, auf der ein einziger Linux-Kernel läuft, Dutzende von benutzerdefinierten Anwendungscontainern, Dutzende von MariaDB-Instanzen, ein Dutzend Apache Solr-Instanzen, ein paar RabbitMQ-Instanzen und ein oder zwei Redis-Indizes gleichzeitig ausführen kann; alle diese Anwendungen denken, wenn sie das Betriebssystem abfragen, dass sie die einzige Anwendung sind, die auf ihrem Computer läuft; und alle können nur auf eine ausgewählte, auf einer Whitelist stehende Gruppe von anderen "Systemen" (Containern) zugreifen, und zwar auf eine Whitelist stehende Weise.
Und das alles nur, weil Linux gut im Lügen geworden ist.
Kontrast zu Docker
Im Gegensatz dazu ist Docker so eingerichtet, dass in jedem Container (einer Reihe von Namensräumen) ein einziger Prozess ausgeführt wird. Dieser einzelne Prozess kann etwas wie PHP-FPM, Nginx oder MariaDB sein oder ein kurzlebiger Prozess wie ein laufender Composer-Befehl. Docker verwendet keinen Init-Prozess. Es ist zwar möglich, mehrere Prozesse manuell in einen einzelnen Container zu zwingen, aber das ist nicht der beabsichtigte Anwendungsfall, und diese Prozesse werden nicht ordnungsgemäß gestartet und heruntergefahren, wenn ein Problem auftritt.
Docker verzichtet auch auf die Konfiguration eines mehrfach verschachtelten Dateisystems zugunsten eines mehrschichtigen Ansatzes. Ein weiterer Trick des Linux-Kernels ist die Möglichkeit, dass sich mehrere Dateisystem-Images gegenseitig "maskieren". Im Wesentlichen können mehrere Dateisysteme unter / gemountet werden, und Dateien in späteren Dateisystemen werden anstelle derjenigen in früheren Dateisystemen verwendet. Dies ermöglicht es, dass die gemeinsamen Basiswerkzeuge eines funktionierenden Debian- oder Red-Hat-Systems nur einmal auf der Festplatte vorhanden sind und dann beim Booten des Containers durch ein installiertes MariaDB- oder PHP-FPM-Overlay "maskiert" werden. Siehe Abbildung 10 zur Veranschaulichung.

Für den Hauptanwendungsfall von Docker, das Ausführen lokaler Anwendungen in einem Container, ist das völlig in Ordnung. Für einmalige Aufgaben, wie das Einbinden eines Kommandozeilentools wie Composer oder NPM in einen Container, ist es sogar besser geeignet als das Modell von Upsun. Das Design von Upsun hingegen vermittelt ein eher "VM-ähnliches" Gefühl und ermöglicht es, dass mehrere verwandte Prozesse (wie Nginx und PHP-FPM) der Einfachheit halber zusammen im selben Container laufen, was bei Docker nicht möglich ist. Keines der beiden Modelle ist von Natur aus "besser" oder "schlechter", sondern nur auf unterschiedliche Anwendungsfälle zugeschnitten.
Der größte Unterschied besteht darin, dass Docker von Natur aus ein Einzelcontainersystem ist; die Verwaltung mehrerer Container im Verbund wird separaten Tools wie Kubernetes, Docker Compose, Docker Swarm usw. überlassen. Im Fall von Upsun wird davon ausgegangen, dass Container immer als Gruppe bereitgestellt werden, selbst wenn es sich um eine Gruppe von 1 handelt. (Erinnern Sie sich an Garfields Gesetz: "Einer ist ein Spezialfall von vielen.")
Es gibt auch andere Containersysteme in freier Wildbahn. FlatPak von Red Hat oder Snaps von Ubuntu sind beides Container-basierte Systeme, die für die Auslieferung von in Containern verpackten Desktop-Anwendungen optimiert sind. Wir werden nicht im Detail darauf eingehen, wie diese Systeme funktionieren, da dieser Artikel bereits lang genug ist, aber seien Sie sich bewusst, dass es auch diese Systeme gibt und dass sie für ihre eigenen Anwendungsfälle besser geeignet sind als die Hosting-Plattform von Upsun oder Docker.
Das Tolle an Containern, wie Linux sie implementiert, ist, dass sie je nach Anwendungsfall auf unterschiedlichste Weise eingesetzt werden können. Wie bei den meisten Dingen in der Technologie sind sie weder gut noch schlecht, sondern nur besser oder schlechter für eine bestimmte Situation geeignet.
Fazit
Auch wenn sie cool sind und eine Vielzahl neuer Funktionen ermöglichen (kein Wortspiel beabsichtigt), sind Container keine Zauberei. Trotz des Marketing-Hypes sind sie überhaupt nicht wie Versandcontainer. Docker ist auch nicht das erste, letzte oder einzige Containersystem auf dem Markt. Es gibt eine Vielzahl von Anwendungen zur Containerkoordinierung, die alle ihre eigenen Vor- und Nachteile haben, genau wie jeder andere Softwaremarkt. Letztendlich sind sie alle einfach organisierte und systematische Wege, um Ihre Programme auf neue und kreative Weise zu nutzen.
Bei Upsun haben wir uns diese "schönen Lügen" zu eigen gemacht, um etwas Mächtiges zu schaffen: eine Plattform, auf der sich Entwickler auf die Entwicklung von fantastischen Anwendungen konzentrieren können, während wir die komplexe Orchestrierung von Namespaces, Containern und Infrastruktur übernehmen. Ganz gleich, ob Sie ein einfaches CMS oder eine komplexe Microservices-Architektur betreiben, unsere Container-Implementierung stellt sicher, dass Ihre Anwendungen genau die Ressourcen und die Isolierung erhalten, die sie benötigen, ohne dass Sie ein Experte für Linux-Kernel-Interna werden müssen.
Willkommen in der Zukunft. Bitte halten Sie Ihre Lügen glaubwürdig.
Testen Sie die Container-Magie von Upsun mit einer kostenlosen Testversion und erleben Sie die Macht der perfekt orchestrierten Täuschung.
Ihr größtes Werk
steht vor der Tür
CompareVercel-AlternativeAmazee-AlternativeHeroku-AlternativePantheon-AlternativeManaged-Hosting-AlternativeFly.io-AlternativeRender-AlternativeAWS-AlternativeAcquia-AlternativeDigitalOcean-Alternative
ProduktÜberblickSupport and servicesPreview environmentsMulti-cloud and edgeGit-driven automationObservability and profilingSecurity and complianceScaling and performanceBackups and data recoveryTeam and access managementCLI, console, and APIIntegrations and webhooksPricingPricing calculator
Use casesBackend-LösungenAnwendungsmodernisierungE-Commerce-HostingCMS-HostingVerwaltung mehrerer StandorteSaaS-Erweiterungen
Join our monthly newsletter
Compliant and validated