


Funktionen


Grundlagen der Indizierung von Datenbanken
MySQLPostgreSQLMariaDBperformanceDatenEntwickler-Workflow
04 August 2025
Diese Seite wurde von unseren Experten auf Englisch verfasst und mithilfe einer KI übersetzt, um einen schnellen Zugriff zu ermöglichen! Die Originalversion findest du hier.
Irgendwann haben wir es alle schon einmal erlebt: Eine perfekt funktionierende Anwendung wird plötzlich langsamer, wenn Ihre Datenbank wächst. Die Anwendung, die zuvor blitzschnelle Abfragen mit 10.000 Datensätzen bewältigte, braucht nun ewig für 10 Millionen Datensätze. Der Schuldige? Fehlende Datenbankindizes.
Datenbankindizes können träge Tabellenscans in blitzschnelle Suchvorgänge verwandeln, indem sie optimierte Datenstrukturen erstellen, die als Abkürzungen zu Ihren Informationen dienen. Stellen Sie sich den Unterschied zwischen dem Blättern durch alle Seiten eines Telefonbuchs und dem direkten Springen zum richtigen Abschnitt mit Hilfe der alphabetischen Registerkarten vor, nur dass der Leistungsunterschied in Millisekunden statt in Minuten gemessen werden kann.
Wenn Sie die Grundlagen der Datenbankindizierung und ihrer verschiedenen Arten verstehen, können Sie die Abfrageleistung für große Datenbanken erheblich verbessern.
In diesem Artikel führen wir in die Datenbankindizierung ein, untersuchen die verschiedenen Arten von Indizierungstechniken und zeigen praktische Implementierungen, die Ihre Abfrageleistung erheblich verbessern können.
Was ist Datenbankindizierung und wie funktioniert sie?
Ein Datenbankindex ist eine zusätzliche Datenstruktur, die einen schnellen Verweis auf bestimmte Spalten bietet und es der Datenbank ermöglicht, Daten zu finden, ohne die gesamte Tabelle zu durchsuchen.
Der Index ist als eine sortierte Liste von Werten aus den indizierten Spalten strukturiert, wobei jeder Wert mit einem Zeiger verknüpft ist, der auf die entsprechende Zeile in der Haupttabelle verweist. Bei der Abfrage der Datenbank wird zunächst dieser sortierte Index durchsucht, um die gewünschten Werte zu finden, und dann werden die gespeicherten Zeiger verwendet, um direkt auf die entsprechenden Zeilen in der Tabelle zuzugreifen.
Die meisten Indizes verwenden eine "B-Tree"-Struktur, die die Daten in Schichten organisiert, so dass die Datenbank ihre Suche schnell eingrenzen kann, indem sie Verzweigungen folgt. Einige Indizes, insbesondere für eindeutige Werte, verwenden eine Hashtabelle, die Werte in eindeutige Codes umwandelt, die direkt auf Zeilen verweisen.
Da es sich bei dem Index jedoch um eine separate Struktur handelt, wird zusätzlicher Speicherplatz in der Datenbank benötigt, und er muss auch aktualisiert werden, wenn sich die Daten in den indizierten Spalten ändern. Verschiedene Datenbanksysteme können diese Speicher- und Aktualisierungsmechanismen unterschiedlich implementieren.
Warum brauchen wir eine Datenbankindizierung?
Indizes verbessern die Leistung der Datenbanksuche, da keine vollständigen Tabellendurchsuchungen mehr erforderlich sind. Ohne einen Index muss bei einer Datenbankabfrage jede Zeile sequentiell überprüft werden, bis die gesuchten Daten gefunden werden. Ein Index ermöglicht es der Datenbank, Datensätze schnell zu finden, indem sie auf die sortierte Struktur verweist, was besonders nützlich ist, um WHERE-Klauseln effizient zu handhaben, ohne jede Zeile zu überprüfen. Dies verbessert die Abfrageleistung erheblich, insbesondere bei großen Datensätzen, bei denen ein sequenzielles Scannen unpraktisch wäre.
Wenn Sie z. B. in einer Datenbank mit Millionen von Datensätzen nach einem Kunden anhand seiner Telefonnummer suchen, kann die Datenbank mit einem Index auf der Telefonnummernspalte die passenden Datensätze sofort ausfindig machen.
Indizes verbessern zwar die Leseleistung erheblich, haben aber auch ihre Tücken. Immer wenn Sie Daten in einer indizierten Spalte einfügen, aktualisieren oder löschen, muss die Datenbank auch die zugehörigen Indexstrukturen aktualisieren. Dies führt zu zusätzlichen I/O- und Verarbeitungskosten auf der Festplatte, was Schreibvorgänge verlangsamen kann. Bei der Entscheidung, welche Spalten indiziert werden sollen, ist es daher wichtig, diese Nachteile sorgfältig abzuwägen.
Arten von Indizes
In diesem Abschnitt werden drei Indexarten behandelt, die die Leistung von SQL-Abfragen verbessern können.
B-Tree-Indizes
B-Trees sind ein weit verbreiteter Indextyp in Datenbanken, um Daten in einer sortierten, geschichteten Struktur zu organisieren. Diese sich selbst ausgleichende Baumstruktur ermöglicht es Datenbanken, bestimmte Zeilen schnell zu finden, so dass nicht die gesamte Tabelle durchsucht werden muss.

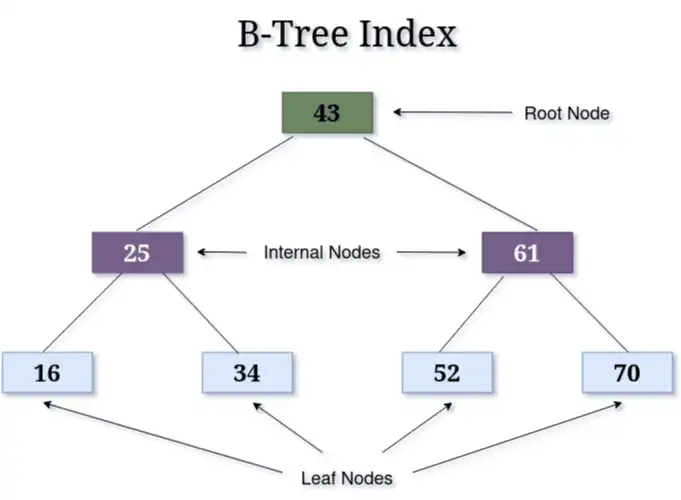
Wie im Diagramm dargestellt, organisieren B-Trees die Daten in kleinere, sortierte Abschnitte über verschiedene Zweige hinweg. Die Werte sind vom niedrigsten (links) bis zum höchsten (rechts) Wert angeordnet. Durch diese Struktur eignen sie sich gut für effiziente Bereichsabfragen und schnelle Suchvorgänge. Wenn Daten hinzugefügt werden, passt der B-Tree seine Verzweigungen und Knoten an, um seine sortierte, ausgewogene Form beizubehalten, wodurch auch sichergestellt wird, dass die Suchvorgänge effizient bleiben, selbst wenn die Datenbank wächst.
Die Datenbank verwendet den indizierten Wert als B-Tree-Schlüssel und speichert einen Zeiger auf den Datensatz als B-Tree-Wert. Wenn Sie nach einem Datensatz mit einem bestimmten Wert suchen, findet die Datenbank den passenden Schlüssel, ruft den Zeiger ab und holt dann den Datensatz.
Der B+ Tree ist eine Variante, die speziell für Datenbankspeichersysteme entwickelt wurde. Im Gegensatz zu normalen B-Trees speichern B+ Trees alle Daten nur in Blattknoten und verknüpfen diese Blätter miteinander. Diese Struktur macht B+ Trees ideal für Bereichsabfragen und Tabellenscans, weshalb die meisten Datenbank-Engines (z. B. InnoDB von MySQL) B+ Trees anstelle von Standard-B Trees für ihre Indizes verwenden.
Wussten Sie das schon? Viele gängige Datenbanken wie MySQL, PostgreSQL und Oracle verwenden B-Tree - oder B+ Tree-Indizes als Standard-Indexierungsmethode, auch für Primärschlüssel.
Hash-Indizes
Hash-Indizes unterscheiden sich von B-Trees durch ihren zugrunde liegenden Mechanismus. Sie verwenden eine Hash-Funktion, einen mathematischen Algorithmus, der Eingabedaten in einen eindeutigen Code oder Hash umwandelt, der diese Daten repräsentiert.
Die Hash-Indizierung erfolgt in zwei Schritten:
- Der indizierte Spaltenwert wird durch die Hash-Funktion geleitet, um einen eindeutigen Hash-Code zu erzeugen.
- Dieser Hash-Code dient als Zeiger auf die Position der Zeile in der Datenbanktabelle.
Das folgende Diagramm veranschaulicht, wie Hash-Indizes Hash-Werte auf Datenbankpositionen abbilden.

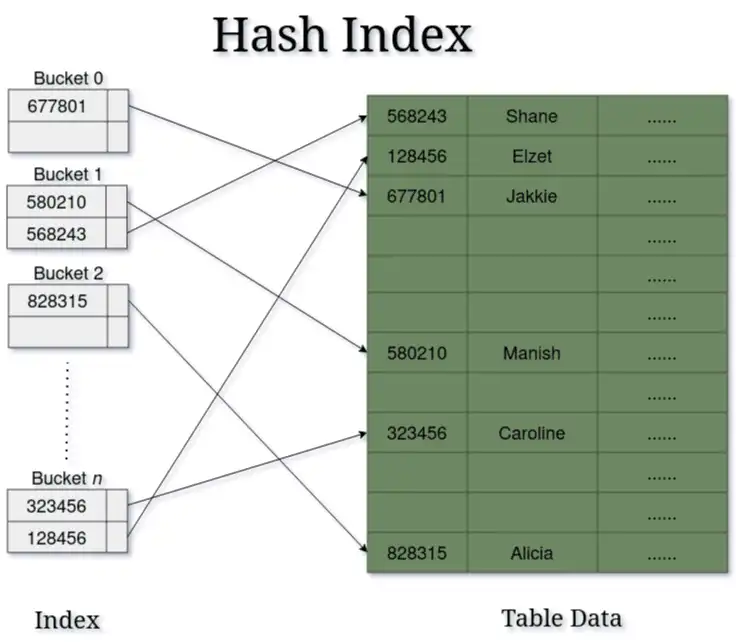
Dieser Ansatz der direkten Zuordnung ermöglicht Suchvorgänge mit konstanter O(1) -Zeit, wodurch Hash-Indizes besonders effizient für Abfragen mit exakter Übereinstimmung sind, z. B. für die Suche nach einer bestimmten Kunden-ID oder Bestellnummer mit WHERE column = "Wert"-Klauseln.
Hash-Indizes haben jedoch eine entscheidende Einschränkung: Sie funktionieren nur bei exakten Übereinstimmungen. Da Hash-Funktionen die natürliche Reihenfolge der Daten durcheinander bringen, können Sie Hash-Indizes nicht für Bereichsabfragen (wie WHERE age > 25), Sortiervorgänge oder Mustervergleicheverwenden . Das macht sie für die meisten realen Szenarien, in denen Sie flexible Abfragen benötigen, ungeeignet.
Volltext-Indizes
Volltextindizes sind spezialisierte Indizes, die die Suche in großen Textfeldern erheblich beschleunigen, indem sie einzelne Wörter (Begriffe) innerhalb einer Textspalte indizieren. Anstatt einen Text als einzelne Einheit für eine exakte Übereinstimmung zu behandeln, unterteilt ein Volltextindex ihn in durchsuchbare Begriffe, was die Geschwindigkeit der Datenbank bei der Bearbeitung komplexer Textsuchen verbessert, z. B. bei der Suche nach allen Datensätzen, die ein bestimmtes Wort oder eine bestimmte Phrase enthalten.
Eine häufig verwendete Struktur für die Volltextindizierung ist der invertierte Index, der im Wesentlichen Wörter (oder Begriffe) den Dokumenten zuordnet, die diese Wörter enthalten. Wenn wir zum Beispiel drei Dokumente haben und das erste und das zweite das Wort Erdbeere enthalten, dann würde die Zuordnung zeigen, dass Erdbeere auf die Dokumente 1 und 2 verweist.
Hier ist eine einfache Illustration dieses Konzepts:

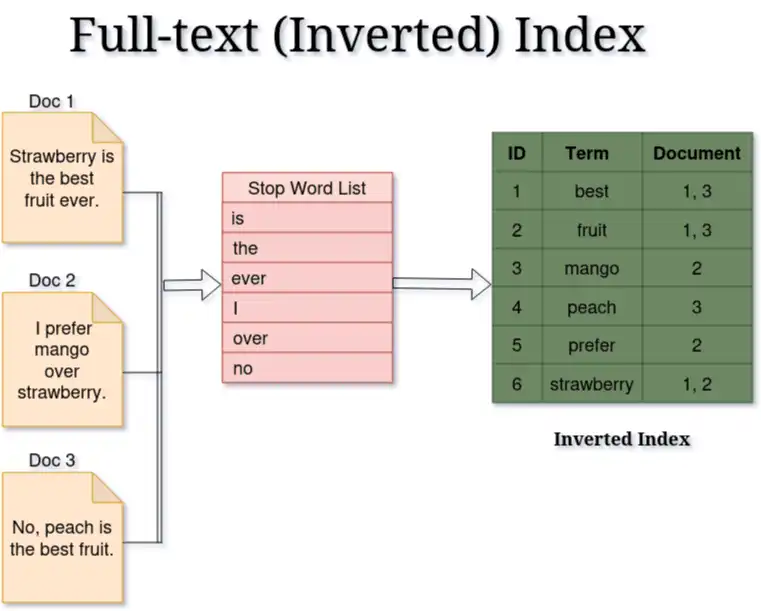
Hinweis: Volltextindizes ignorieren in der Regel häufige Wörter wie "der", "ist" und "und" (sogenannte Stoppwörter), um Platz zu sparen und die Suchleistung zu verbessern. Durch das Ignorieren dieser häufigen, unwichtigen Wörter kann der Index Platz sparen und die Suchleistung erhöhen.
Volltextindizes sind besonders nützlich für Anwendungen, die erweiterte Suchfunktionen erfordern. Sie sind ideal für die Suche in großen Textmengen, z. B. für die Suche nach bestimmten Schlüsselwörtern in Artikeln, die Identifizierung von Merkmalen in Produktbeschreibungen oder das Auffinden von Sätzen in Benutzernachrichten. Ziehen Sie in Erwägung, einen Volltextindex für ein großes Textfeld zu erstellen, wenn eine Anwendung innerhalb ihres Inhalts suchen muss. Sie könnten z. B. einen Volltextindex zum Feld product_description hinzufügen, wenn Benutzer häufig nach Produktmerkmalen wie bluetooth oder wireless suchen.
Volltextindizes beanspruchen jedoch wesentlich mehr Speicherplatz und müssen laufend gepflegt werden, wenn Textdaten hinzugefügt oder aktualisiert werden. Außerdem sind sie bei einfachen Abfragen mit exakter Übereinstimmung langsamer als andere Indextypen, weshalb sie sich am besten für Textsuchvorgänge eignen.
Geclusterte und nicht geclusterte Indizes
Indizes können auch in geclusterte und nicht geclusterte (sekundäre) Indizes unterteilt werden. Ein geclusterter Index definiert die physische Reihenfolge der Daten in einer Tabelle, und eine Tabelle kann nur einen geclusterten Index haben. Nicht geclusterte Indizes werden separat gespeichert, mit Zeigern auf die relevanten Zeilen, und eine Tabelle kann mehrere nicht geclusterte Indizes haben. Stellen Sie sich einen geclusterten Index als das gesamte Buch in einer bestimmten Reihenfolge vor (wie ein alphabetisch sortiertes Telefonbuch), während nicht geclusterte Indizes wie Lesezeichen sind, die auf die relevanten Seiten verweisen.
Wußten Sie schon? In MySQL (InnoDB) dient der Primärschlüssel standardmäßig als geclusterter Index. In PostgreSQL gibt es keine echten geclusterten Indizes; jeder Index, einschließlich des Primärschlüssels, ist technisch gesehen ein Sekundärindex.
Wann sollte man Indizes verwenden und wann sollte man sie vermeiden?
Indizes sind am effektivsten für Spalten, die häufig durchsucht, sortiert oder in JOIN-Operationen verwendet werden, wie Primärschlüssel, Fremdschlüssel oder Felder in WHERE-Klauseln. Eine bewährte Methode ist die Erstellung von Indizes für Spalten, die zum Filtern großer Datensätze verwendet werden (z. B. Alter und Erfahrungsstufe) und die Abfrageleistung verbessern. Ziehen Sie außerdem die Indizierung von Spalten in Betracht, die an der Sortierung (ORDER BY) oder Aggregation (GROUP BY) beteiligt sind, da diese Operationen von einem schnelleren Datenzugriff durch Indizes profitieren. Indizes können auch für Spalten nützlich sein, die an Aggregationen beteiligt sind (SQL-Funktionen wie SUM(...) und AVG(...)), wo die Zusammenfassung von Daten ohne schnelle Zugriffspfade zu einem Engpass werden könnte.
Indizes verursachen jedoch zusätzlichen Speicher- und Wartungsaufwand, weshalb sie bei häufig aktualisierten Tabellen mit Vorsicht zu verwenden sind. Wenn eine Tabelle ständig eingefügt oder aktualisiert wird, muss bei jeder Änderung der Index geändert werden, was Schreibvorgänge verlangsamen kann. Vermeiden Sie es, Indizes für Spalten mit geringer Selektivität zu erstellen, wie z. B. boolesche oder binäre Felder, da sie nur wenige eindeutige Werte haben, die wenig Leistungsvorteile bieten und gleichzeitig unnötigen Overhead verursachen. Bei sehr kleinen Tabellen schließlich ist eine Indexierung oft überflüssig, da die Datenbank die gesamte Tabelle schnell und ohne spürbare Leistungseinbußen durchsuchen kann.
Beispiele aus der Praxis für die Indizierung von Datenbanken
Werfen wir einen Blick auf einige praktische Beispiele für die Datenbankindizierung. In den folgenden Abschnitten wird anhand einer einfachen SQL-Tabelle gezeigt, wie die Indizierung die Abfrageleistung verbessern kann. Diese Beispiele verwenden die Standard-SQL-Syntax, sofern nicht anders angegeben.
Hier ist eine einfache Tabelle "users" mit Spalten für name,email, age, bio und id als Primärschlüssel:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100) UNIQUE,
age INT,
bio TEXT
);
Beispiel für einen B-Baum-Index
Angenommen, Sie fragen häufig die Spalte age ab, um Benutzer in einem bestimmten Altersbereich zu finden, z. B. zwischen fünfundzwanzig und fünfunddreißig Jahren. Eine typische Abfrage hierfür wäre wie folgt:
SELECT * FROM users WHERE age BETWEEN 25 AND 35;
Ohne einen Index führt die Datenbank einen vollständigen Tabellenscan durch, bei dem jede Zeile daraufhin überprüft wird, ob das Alter in den angegebenen Bereich fällt. Dieser Ansatz kann sehr langsam sein, wenn die Tabelle größer wird.
Um solche Abfragen zu optimieren, können Sie einen B-Baum-Index für die Spalte age erstellen:
CREATE INDEX idx_age ON users(age);
Hinweis: B-Tree ist sowohl in MySQL als auch in PostgreSQL der Standard-Indextyp. Wenn Sie also einen Standard-Index erstellen, handelt es sich normalerweise um einen B-Tree-Index.
Mit diesem Index kann die Datenbank in der sortierten age-Spalte mit Hilfe der B-Baum-Struktur navigieren. Auf diese Weise können irrelevante Zeilen übersprungen und nur die Zeilen angezeigt werden, die den Abfragebedingungen entsprechen. Für Bereichsabfragen wie BETWEEN sind B-Baum-Indizes besonders effektiv, da sie für den geordneten Datenzugriff konzipiert sind.
Wenn Sie also dieselbe Abfrage mit dem Index ausführen, wird die Arbeitslast der Datenbank erheblich reduziert, was zu einer schnelleren Ausführung der Abfrage führt. Dieser Leistungsgewinn wird immer wichtiger, je größer die Tabelle wird.
Beispiel für einen Hash-Index
Ein weiterer gängiger Anwendungsfall ist die Suche nach Benutzern anhand ihrer E-Mail, z. B. während eines Anmeldevorgangs. Da E-Mail-Adressen eindeutig sind und genau nachgeschlagen werden, kann die Hash-Indizierung eine effektive Lösung für Abfragen mit exakter Übereinstimmung sein.
Hier ist eine Abfrage, die einen Benutzer anhand seiner E-Mail-Adresse findet:
SELECT * FROM users WHERE email = 'jane.doe@example.com';
Ohne einen Index muss die Datenbank das email-Feld jeder Zeile auf den exakten Wert überprüfen, was bei großen Tabellen sehr langsam sein kann.
Um eine gute Leistung bei dieser wichtigen Abfrage zu gewährleisten, können Sie einen Hash-Index mit dem folgenden SQL erstellen:
CREATE INDEX idx_email_hash ON users USING hash(email);
Wenn Sie nun dieselbe Abfrage mit dem erstellten Index erneut ausführen, springt die Datenbank direkt zur passenden E-Mail-Zeile (oder prüft den spezifischen Hash), was die exakten Übereinstimmungen erheblich beschleunigt.
Auch hier muss die Datenbank nicht mehr jede Zeile durchsuchen; stattdessen verwendet sie den Hash-Index, um die passende Zeile direkt zu finden, was exakte Suchvorgänge extrem effizient macht, insbesondere bei großen Datensätzen.
Alle Anwendungen mit einer großen Anzahl von Benutzern, die sich mit ihren E-Mail-Adressen anmelden, würden also sehr von einem Hash-Index für das E-Mail-Feld profitieren.
Hinweis: Hash-Indizes werden in PostgreSQL nativ unterstützt, aber MySQL hat keine nativen Hash-Indizes. Selbst wenn Sie eine InnoDB-Tabelle auffordern, einen Hash-Index zu erstellen, wird sie in einen B-Baum umgewandelt.
Beispiel für einen Volltextindex
Stellen Sie sich vor, Sie haben eine Benutzerdatenbank mit ansprechenden Biografien und wollen Benutzer finden, die sich für Filme interessieren.
Eine übliche Abfrage hierfür wäre wie folgt:
SELECT * FROM users WHERE bio LIKE '%movies%';
Ohne einen Volltextindex muss bei dieser Abfrage das bio-Feld jeder Zeile gescannt und überprüft werden, ob es den angegebenen Text enthält (unter Verwendung des "%keyword%" -Musters), was bei großen Textfeldern extrem langsam sein kann.
Wenn Sie häufig nach bestimmten Schlüsselwörtern in großen Textfeldern in einer Datenbank suchen müssen, kann die Erstellung eines Volltextindexes die Leistung erheblich verbessern.
Die Syntax für die Erstellung eines Volltextindexes unterscheidet sich von Datenbank zu Datenbank. Im Folgenden wird beschrieben, wie Sie einen solchen in PostgreSQL und MySQL erstellen:
-- PostgreSQL
CREATE INDEX idx_bio_fulltext ON users USING GIN (to_tsvector('english', bio));
-- MySQL
CREATE FULLTEXT INDEX idx_bio_fulltext ON users(bio);
MySQL hat eine eingebaute Unterstützung für Volltextindizes auf VARCHAR- und TEXT-Spalten. In PostgreSQL erstellen Sie einen Volltextindex, indem Sie den Generalized Inverted Index (GIN) auf das Ergebnis der Funktion to_tsvector anwenden.
Mit dem erstellten Volltextindex können Sie nun Volltextsuchabfragen durchführen, um Benutzer zu finden, die sich für Filme interessieren:
-- PostgreSQL
SELECT * FROM users WHERE to_tsvector('english', bio) @@ to_tsquery('movies');
-- MySQL
SELECT * FROM users WHERE MATCH(bio) AGAINST ('movies' IN NATURAL LANGUAGE MODE);
Mit einem Volltextindex kann die Datenbank nach Schlüsselwörtern in großen Textfeldern suchen, ohne dass jede Zeile gescannt werden muss. Dadurch wird die Suche nach Schlüsselwörtern viel schneller, insbesondere bei großen textlastigen Spalten.
Fazit
Die Indizierung von Datenbanken ist nicht nur eine Leistungsoptimierung; sie ist oft der Unterschied zwischen einer Anwendung, die skalierbar ist, und einer, die unter Last abstürzt. Die Techniken, die wir heute behandelt haben, können Ihre langsamsten Abfragen in blitzschnelle Operationen verwandeln, aber nur, wenn Sie sie strategisch einsetzen.
Was ist also der nächste Schritt? Beginnen Sie damit, die häufigsten Abfragen und die am stärksten belasteten Muster Ihrer Anwendung zu ermitteln. Konzentrieren Sie sich auf die Indizierung von Spalten, die in WHERE-Klauseln, JOIN-Bedingungen und ORDER BY-Anweisungenvorkommen . Denken Sie daran, dass jeder Index einen Kompromiss zwischen Lesegeschwindigkeit und Schreibleistung darstellt; wählen Sie mit Bedacht.
Die Realität sieht jedoch so aus, dass die Optimierung der Datenbankleistung in verschiedenen Umgebungen, die Überwachung von Abfragemustern und die Pflege von Indizes bei der Weiterentwicklung Ihrer Anwendung schnell überfordernd werden kann. Sie brauchen mehr als nur Indizierungswissen; Sie brauchen eine Plattform, die eine nahtlose Leistungsoptimierung ermöglicht.
An dieser Stelle verändert Upsun Ihren Entwicklungsworkflow. Anstatt mit Datenbankkonfigurationen in Staging und Produktion zu jonglieren, bietet Upsun sofortiges Klonen von Umgebungen mit echten Daten, so dass Sie Ihre Indizierungsstrategien anhand tatsächlicher Abfragemuster testen können, bevor sie in Betrieb gehen. Mit dem integrierten Observability-Profiling erkennen Sie Leistungsengpässe sofort und erhalten umsetzbare Empfehlungen zur Optimierung.
Sind Sie bereit, bei der Datenbankleistung nicht länger zu raten? Starten Sie Ihre kostenlose Upsun-Testversion und erleben Sie, wie es ist, mit Zuversicht zu optimieren, komplett mit den Tools und Erkenntnissen, die das Management der Datenbankleistung mühelos machen.
Ihr größtes Werk
steht vor der Tür
CompareVercel-AlternativeAmazee-AlternativeHeroku-AlternativePantheon-AlternativeManaged-Hosting-AlternativeFly.io-AlternativeRender-AlternativeAWS-AlternativeAcquia-AlternativeDigitalOcean-Alternative
ProduktÜberblickSupport and servicesPreview environmentsMulti-cloud and edgeGit-driven automationObservability and profilingSecurity and complianceScaling and performanceBackups and data recoveryTeam and access managementCLI, console, and APIIntegrations and webhooksPricingPricing calculator
Use casesBackend-LösungenAnwendungsmodernisierungE-Commerce-HostingCMS-HostingVerwaltung mehrerer StandorteSaaS-Erweiterungen
Join our monthly newsletter
Compliant and validated