


Schritt halten mit den sich entwickelnden Best Practices für die Bereitstellung von Webanwendungen
In der Tech-Welt wird oft über "Best Practices" gesprochen, aber selten wird anerkannt, dass sie sich im Laufe der Zeit ändern können und dies auch tun. Alle "Best Practices" sind nichts anderes als eine Destillation der Herausforderungen einer bestimmten Situation zu einer normalerweise optimalen Reihe von Kompromissen.
Im Zuge des technologischen Fortschritts ändern sich diese Kompromisse jedoch. Was früher schwierig und teuer war, kann heute einfacher und billiger werden. (Und manchmal kann das, was einst einfach und billig war, schwer und teuer werden.) Das bedeutet, dass sich die "besten Praktiken" mit ihnen weiterentwickeln müssen. Was einst führend war, ist heute eine Verliererstrategie.
Das 3-Schichten-Modell für die Bereitstellung von Webanwendungen
Ein Beispiel für eine solche Entwicklung sind die Entwicklungsabläufe. Früher waren Serverumgebungen teuer und zeitaufwändig in der Erstellung und Wartung. Sie erforderten physische Hardware, die manuelle Installation von Software und die manuelle Wartung, um sie auf dem neuesten Stand zu halten.
Früher war das eine Rechtfertigung dafür, nur einen Produktionsserver zu haben und sonst nichts. Das führte zu einem gängigen Entwicklungsmodell mit "meinem Desktop und der Produktion" (oder "nur der Produktion", wenn man Pech hatte). Alles, was robuster war, war zu teuer und arbeitsintensiv für alle außer den größten Installationen.
Mit der Zeit wurde uns als Branche klar, dass dies ein schlechter Kompromiss war. "Hack it on production" wurde durch das berühmte 3-Schichten-Modell ersetzt (oder manchmal ein 4-Schichten-Modell, wenn man das Budget dafür hatte):

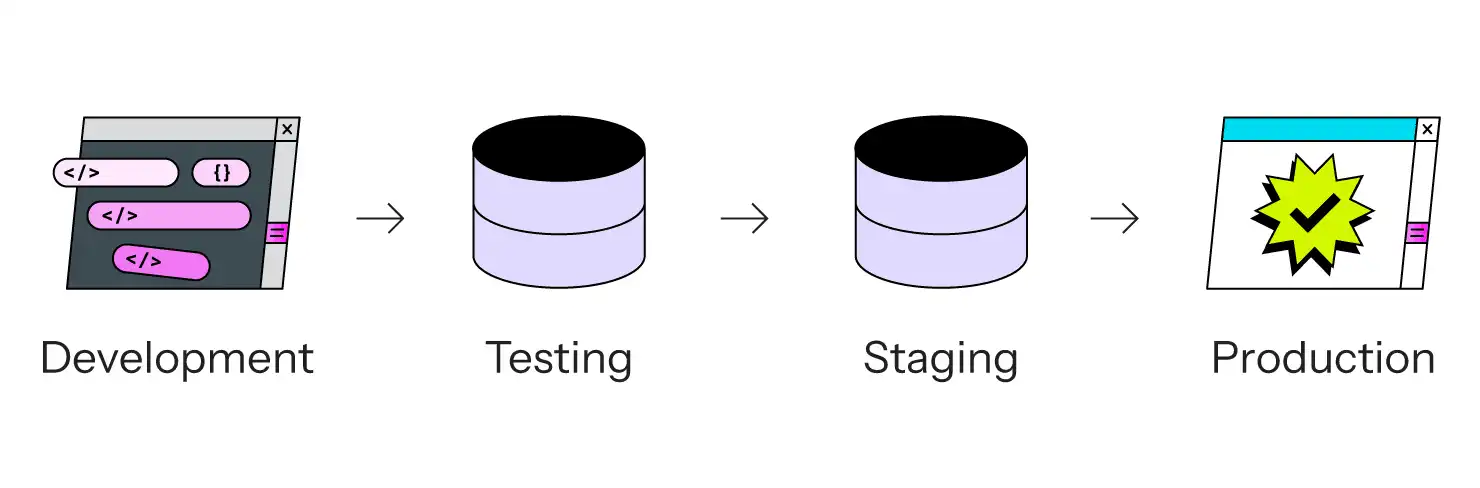
- Bei der Entwicklung wird der Code bearbeitet, in der Regel auf dem lokalen Laptop eines jeden Entwicklers.
- Das Testen ist das erste Mal, dass der Code mehrerer Entwickler miteinander in Kontakt kommt. Hier finden Integrationstests, Benutzerakzeptanztests und andere QA statt. Manchmal wird diese Phase mit Staging zusammengelegt.
- Staging ist ein Bereich vor der Veröffentlichung, in dem der Code in einer produktionsähnlichen Umgebung getestet wird.
- Die Produktion ist, nun ja, die Produktion. Die Live-Site.
Der Vorteil des 3- oder 4-stufigen Modells besteht darin, dass der Code von mehreren Personen geprüft und getestet werden kann, bevor er die Live-Site erreicht. (Wie der Witz besagt, hat jeder einen Testserver; einige haben das Glück, auch einen separaten Produktionsserver zu haben). Das ist ein Fortschritt gegenüber dem Hacken auf der Produktionsseite, das ist klar. Es bedeutet auch, dass es einen diskreten Schritt gibt, in dem bestimmte Aktivitäten stattfinden: Das Schreiben von Code geschieht in der Entwicklungsabteilung; das Zusammenführen von Code geschieht in der Testphase; die Qualitätssicherung geschieht in der Testphase; die abschließende Überprüfung geschieht in der Staging-Phase, manchmal mit einem Schnappschuss der Produktionsdaten; und die Produktion ist der Ort, an dem die Kunden die Website tatsächlich sehen.
Der Haken am 3-Tier-Modell bei der Bereitstellung von Webanwendungen in der Praxis
Das 3-Tier-Modell hat jedoch auch eine Reihe von Nachteilen. Insbesondere ist es für die lokale Entwicklungsehr leicht , der Testinstanz weit hinterherzuhinken, was dazu führt, dass die Testinstanz zu einer Masse von Merge-Konflikten wird. Je länger man mit der Zusammenführung von Code nach Testing wartet, desto schwieriger wird es. Andererseits wird das Testen umso schwieriger, je häufiger Sie den Code zu Testing zusammenführen. Die zu testende Sache kann sich jedes Mal ändern, wenn ein neuer Code zusammengeführt wird, was zu einem beweglichen Ziel führt. Das wird zu einer noch größeren Herausforderung, wenn Sie mehrere Tester haben, da sich ihre Bemühungen gegenseitig behindern können. (Das gilt besonders für Tests mit Endbenutzern oder für Tests, bei denen Daten geändert werden).
Der andere große Nachteil dieses Modells ist, dass es linear ist. Damit der Code in die Produktion gelangen kann, muss er die Test- und/oder Staging-Phase durchlaufen, von denen es jeweils nur eine gibt. Das mag in Ordnung sein, wenn alles funktioniert, aber natürlich geht immer etwas schief. Wenn Sie in der Produktion einen Fehler entdecken, ist es keine gute Idee, die Test-/Stage-Pipeline zu umgehen und den Code direkt in die Produktion zu überführen, ohne zu überprüfen, ob die Korrektur nicht noch etwas anderes beschädigt. Wenn Sie jedoch die korrekten Test-/Stage-Phasen durchlaufen, könnte Ihre einfache Notfallkorrektur durch eine andere, noch nicht fertige Funktion blockiert werden, die bereits in Testing oder Staging zusammengeführt, aber noch nicht zur Veröffentlichung freigegeben wurde.
Das führte zu der Idee eines "Hotfix", was in der Sprache der Entwickler bedeutet: "Der Prozess steht der Behebung des Fehlers im Weg, also werde ich den Prozess aufgeben." Das mag manchmal die richtige Vorgehensweise sein, aber es zeigt auch, wo der Prozess fehlerhaft ist.
Ein weiteres Problem sind die Daten. Während der Code durch die Pipeline nach oben fließt, möchten Sie in der Lage sein, neuen Code mit aktuellen Produktionsdaten zu testen. Je nach Konfiguration kann es schwierig und zeitaufwändig sein, einen Snapshot der Produktionsdaten nach Staging zu übertragen. Wenn dies der Fall ist, wird die Replikation in die Test- oder Entwicklungsumgebung noch schwieriger sein. Das bedeutet, dass Sie möglicherweise erst in letzter Minute herausfinden, wie der neue Code mit den realen Daten interagiert, was in der Regel mehrere Wochen später ist, als Sie es sich wünschen.
CI/CD für einen schnelleren Prozess
Die Standardlösung für die Herausforderungen eines dreistufigen Modells besteht darin, Änderungen schneller durchzusetzen. Dies führte zu zwei Konzepten:
- Continuous Integration (CI), was so viel heißt wie "Code so schnell wie möglich in die Tests integrieren ".
- Continuous Deployment (CD), was so viel bedeutet wie "Code so schnell wie möglich durch die Pipeline bringen und in der Produktion bereitstellen ".
CI/CD, wie es bekannt wurde, versucht, die Herausforderungen des dreistufigen Modells mit Automatisierung anzugehen, um den Code schneller durch den Prozess zu bringen. Dies kann eine Reihe verschiedener Optionen beinhalten.
- Automatisches Ausführen von Tests auf Code-Ebene für neuen Code, bevor er überhaupt irgendwo bereitgestellt wird.
- Automatisches Ausführen einiger QA- oder UAT-Tests in der Testphase, wodurch der Bedarf an langsamen und überlasteten Menschen verringert wird.
- Automatisches Weiterleiten von Code durch die Pipeline, wenn bestimmte Kriterien erfüllt sind (z. B. wenn Tests bestanden wurden).
Dies trägt dazu bei, die Zeit zu verkürzen, die benötigt wird, um den Code durch die Pipeline zu schieben, aber es beseitigt nicht das Kernproblem: Das 3-Schichten-Modell ist linear, aber die Codeentwicklung ist es nicht. Es bringt auch seine eigenen Herausforderungen mit sich, nämlich mehr bewegliche Teile, die eingerichtet, verwaltet und am Laufen gehalten werden müssen. Es gibt sogar spezielle Stellen für CI/CD-Ingenieure, "DevOps-Ingenieure" oder verschiedene andere Bezeichnungen, die im Wesentlichen "Pflege und Fütterung all dieser Automatisierung" bedeuten. Das scheint nicht sehr automatisch zu sein, und es kann teuer werden.
Git und Container: CI/CD-Automatisierung im Umbruch
Zwei technologische Fortschritte haben die CI/CD-Automatisierung erträglich gemacht.
Der erste war die weite Verbreitung von Git als Versionskontrollsystem. Git zeichnet sich in vielen Bereichen aus, aber insbesondere die extrem kostengünstige und schnelle Möglichkeit, Code zu verzweigen und Zweige zusammenzuführen, verbessert den "Integrations"-Teil der Gleichung erheblich. Neuere Entwickler erinnern sich vielleicht nicht mehr an die Zeiten von Subversion oder CVS, aber vor den modernen verteilten VCS war das "Erstellen einer Verzweigung" eine schwierige, zeitraubende und daher seltene Aufgabe. Git löste diese Aufgabe mit Leichtigkeit, und eine einfache API machte es für Skripte und Automatisierung sehr geeignet.
Der zweite Grund war das Aufkommen der Virtualisierung, zunächst durch virtuelle Maschinen und dann, was noch besser war, durch Container. Mit Containern kann man die Idee eines Computer-"Systems" von der physischen Hardware abstrahieren. Das bedeutete, dass für den Aufbau neuer Umgebungen keine neue Hardware benötigt wurde, sondern lediglich eine ausreichende Codierung.
Lange Zeit wurden Container hauptsächlich für billige Testumgebungen verwendet. Es entstanden CI-Dienste, die Container zur Erstellung temporärer Minisysteme verwendeten, in denen Tests auf Code-Ebene oder manchmal auch vollständige UAT-Tests durchgeführt wurden. In Kombination mit Git-basierter Automatisierung wurde die Testphase der traditionellen Pipeline dadurch wesentlich einfacher und produktiver. Im Idealfall werden für jeden Git-Zweig beim Push alle verfügbaren automatisierten Tests ausgeführt. Wenn sie fehlschlagen, weiß der Entwickler sofort Bescheid. Wenn sie bestanden werden, können menschliche Prüfer die automatisierbaren Teile überspringen und nur die qualitativen Aspekte des neuen Codes bewerten.
Solche Dienste haben jedoch das Kernproblem des dreistufigen Modells nicht gelöst: seine lineare Natur. Sie haben es lediglich schneller gemacht.
Außerdem war das Produktionssystem in den meisten Fällen immer noch nicht mit der Entwicklung oder den Tests synchronisiert, und manchmal auch nicht mit dem Staging. Je näher das Test- und Staging-System an der Produktion ist, desto mehr Fehler können frühzeitig erkannt werden und desto weniger Variablen gibt es, die schief gehen können. Unterschiedliche Versionen des Betriebssystems, Abhängigkeiten, Ressourcenprofile, Zusatzbibliotheken, Sprachlaufzeiten und so weiter haben alle ihre eigenen subtilen Fehler, die in jeder Kombination lauern. Wenn die Kombination in der Produktion nicht dieselbe ist wie in der Test- und Staging-Phase, dann sind diese Validierungsschritte nur gut begründete Vermutungen.
Das Zeitalter des Cloud Computing
Was Virtualisierung und insbesondere Container wirklich ermöglichen, ist die Fähigkeit, überhaupt nicht mehr über Hardware nachzudenken. Ein Computer-"System" ist nicht länger ein handwerklich hergestelltes Ding, das man warten und verwalten muss. Es ist eine logische, flüchtige, wegwerfbare Schöpfung in Software.
Bei einem Upgrade wird nicht mehr die Software an Ort und Stelle geändert, sondern ein völlig neues "System" (Container) erstellt und das alte ersetzt, ein Prozess, den ein gutes Orchestrierungssystem völlig transparent macht.
Im Idealfall ist das Dateisystem in jedem Container schreibgeschützt, möglicherweise mit einigen Ausnahmen für Benutzerdaten auf der weißen Liste. Dies verhindert sowohl versehentliche Anpassungen als auch böswillige Sicherheitsangriffe. Anstatt das Dateisystem zu modifizieren, um eine Änderung vorzunehmen, erstellt man ein neues Dateisystem-Image, wirft das alte weg und aktiviert das neue.
Die Möglichkeit, Systeme auf rein softwaretechnische Weise zu betrachten, wird heute als "Cloud Computing" bezeichnet, eine Anspielung auf den Marketingbegriff "The Cloud", der sich allgemein auf gehostete Lösungen bezieht. Obwohl sie nicht dasselbe sind, gehen sie doch Hand in Hand. Und da sich Cloud Computing-Umgebungen von älteren, hardwarebasierten Systemen unterscheiden, gibt es eine Reihe neuer, anderer Best Practices.
Containerisierung: die beste Praxis von Anfang bis Ende
Mit jedem Schritt auf diesem Weg haben sich die konventionellen Best Practices" verändert. Mit dem Aufkommen der weit verbreiteten Containerisierung basieren die führenden "Best Practices" heute auf der Containerisierung des gesamten Prozesses von Anfang bis Ende. Das wiederum sprengt das traditionelle 3-Schichten-Modell.
Stattdessen sieht die heutige Best-Practice-Strategie für die Webbereitstellung wie folgt aus:

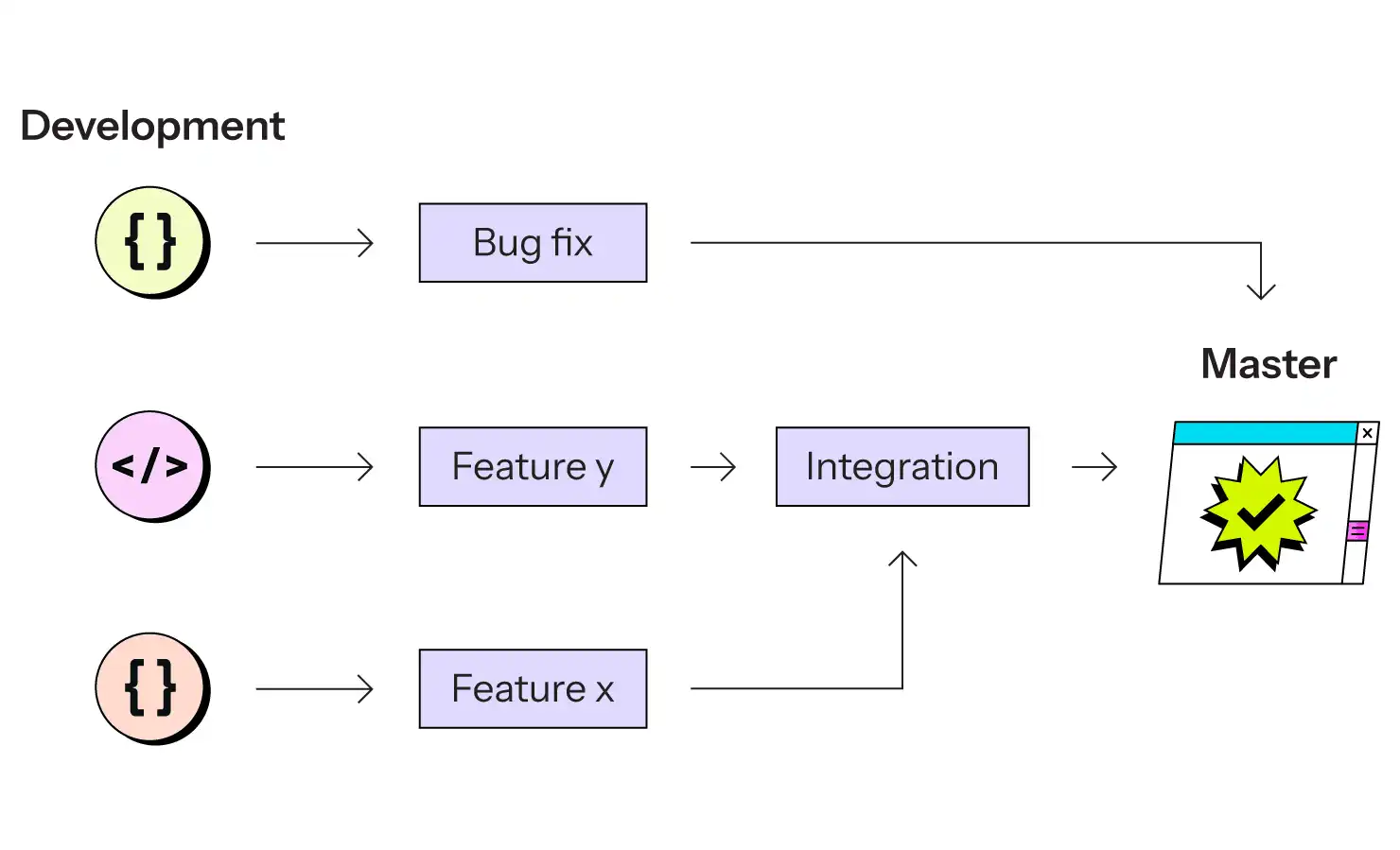
Jeder Schritt von der Entwicklung bis zur Produktion wird mit Containern erstellt und über Git verwaltet. Jeder Zweig entspricht einer Container-basierten Umgebung.
Während die Entwicklung immer noch auf dem lokalen Computer eines Entwicklers stattfindet, der möglicherweise die gleichen Container-Images verwendet, sind bei jedem anderen Schritt bitweise identische Container im Einsatz. Die Version von PHP, Node.js oder Java, die verwendet wird, ist garantiert dieselbe, bis hin zu den Patch-Release- und Kompilierungseinstellungen. Die Version Ihrer SQL-Datenbank ist identisch. Die Version Ihres Such-Servers ist identisch. Die Drittanbieter-Abhängigkeiten Ihres eigenen Codes sind identisch.
Und wenn sie es nicht sind, dann nur, weil Sie sie absichtlich geändert haben. Die Konfiguration der Umgebung ist selbst Code, der in Git gespeichert ist, so dass das Testen von Änderungen an der Infrastruktur (Aktualisierung einer Abhängigkeit oder einer Datenbank oder Ihrer Sprachlaufzeit) dasselbe ist wie das Testen von Codeänderungen.
Sie stellen keine neuen Versionen Ihres Codes bereit, sondern neue Versionen Ihres gesamten Systems, von dem Ihr Code nur ein Teil ist.
Alle neuen Aktualisierungen eines Git-Zweigs können und sollten dazu führen, dass die entsprechende Umgebung von Grund auf neu erstellt wird, so dass die Frage nach dem "Update in Place" nicht zu stellen ist.
Skalierbarkeit der App-Bereitstellung mit Git-and-Cloud
Dieses Git-and-Cloud-Modell hat eine Reihe von Vorteilen gegenüber dem 3-Schichten-Modell.
- Es ist nicht-linear. Eine Änderung kann eine andere nicht blockieren, da alle Änderungen ihre eigene unabhängige Pipeline haben. Ein Feature-Release, eine kritische Fehlerkorrektur, eine Routineaktualisierung - sie alle können parallel und unabhängig voneinander durchgeführt werden, wann immer sie fertig sind.
- Die Anzahl der parallelen Arbeitsabläufe ist nur durch die Anzahl der Container begrenzt, die Sie erstellen können. Wenn Sie eine virtualisierte Cloud-Umgebung verwenden, bedeutet dies, dass die zusätzlichen Kosten für weitere Umgebungen gering sind und ungefähr linear skalieren.
- Da jede Umgebung ein Einwegprodukt ist und im laufenden Betrieb nach wiederholbaren Anweisungen erstellt wird, könnenIhre Vorabversionsumgebungen wirklich identisch mit der Produktionsumgebung sein.
- "Integration" ist dann nur noch eine Frage der Verwendung Ihrer Git-Zweige. Wenn eine neue Änderung in die Produktionsumgebung übernommen wird, kann jeder andere Zweig problemlos Aktualisierungen aus der Produktionsumgebung übernehmen, denn Git macht das ganz einfach. Wenn es einen Konflikt gibt, wird dieser sofort erkannt.
- Alternativ können Sie auch einen Git-Zweig für Tests vor der Veröffentlichung einrichten, in den Sie andere Zweige einbinden, um dort Integrationstests durchzuführen. Mit diesem Modell können Sie also das ältere 3-Schichten-Modell simulieren, falls gewünscht. Das ist normalerweise nicht notwendig, aber möglich, wenn es Sinn macht. Die möglichen Arbeitsabläufe werden nur durch die Fähigkeiten Ihres Teams im Umgang mit Git begrenzt.
- Da das Dateisystem schreibgeschützt ist, haben Sie die Garantie, dass keine Änderungen vorgenommen werden können, ohne Git zu durchlaufen, und eine zusätzliche Sicherheitsebene zum Schutz vor Eindringlingen.
Es gibt viele mögliche Tools, um einen Git- und Cloud-Hosting- und Bereitstellungs-Workflow für eine moderne Anwendungaufzubauen . Einige werden selbst gehostet, während andere ein gehosteter Dienst sind. In den meisten Fällen bietet ein gehosteter Dienst, wie z. B. Upsun.com, auf lange Sicht bessere Kosteneinsparungen. Der größte Nachteil des Git-and-Cloud-Modells ist die Komplexität der zugrundeliegenden Tools, die es ermöglichen. Diese Komplexität wird am besten von engagierten Teams gehandhabt, die diese Tools in ihrer Gesamtheit verwalten können.
Neue Teststandards mit Upsun.com
Das i-Tüpfelchen, das nur von wenigen Anbietern wie Upsun.com angeboten wird, ist die Datenreplikation. Damit ein Git-and-Cloud-Modell wirklich glänzen kann, braucht es nicht nur günstige Umgebungen und einen einfachen Vorwärtsfluss von Code, sondern auch einen günstigen Rückwärtsfluss von Daten. Je näher die Daten in Ihren Testumgebungen an der Produktion sind, desto genauer sind Ihre Validierungs- und Testbemühungen. Upsun.com ermöglicht es Ihnen, mit einem Mausklick einen Copy-on-Write-Klon beliebiger Daten von einer Umgebung in eine andere durchzuführen - kein langsames SQL-Dump und Restore, das Dutzende von Minuten oder Stunden dauern kann und möglicherweise die Produktionsinstanz während des Prozesses blockiert. Die Zeit, die dafür benötigt wird, ist annähernd konstant und liegt im Durchschnitt zwischen einer und drei Minuten.
Dies ermöglicht das Testen einer neuen Änderung - sei es eine kleine Fehlerbehebung, eine große neue Funktion oder ein Abhängigkeits-Upgrade - mit den Produktionsdaten und der Produktionskonfiguration für ein paar Minuten oder ein paar Tage. Es bietet die präziseste "Staging-ist-wie-Produktion"-Erfahrung, die möglich ist, während das Konzept eines "Staging"-Servers vollständig vermieden wird.
Das ist der modernste Webbereitstellungsprozess von heute.
Zukunftssicherer Prozess für die Bereitstellung von Webanwendungen
Mit der Verbesserung der Technologie ändert sich auch der optimale Einsatz der Technologie. Vor 10 oder 15 Jahren war eine 3- oder 4-stufige Architektur der Standardprozess in der Branche und das, was die meisten Unternehmen hätten tun sollen. Damals war das der "richtige Weg".
Die Tools haben sich geändert und damit auch die "Best Practices". Heute, wo Git und Cloud-Computing-Umgebungen weit verbreitet sind, bedeutet Continuous Deployment etwas anderes als in den Tagen der handwerklichen Build-Prozesse. Es bedeutet eine beliebige Anzahl paralleler Umgebungen, nicht-lineare Arbeitsabläufe und billige Einweg-Container, die bei Bedarf von Grund auf neu erstellt werden können.
Was wird in weiteren 10 Jahren die beste Praxis sein? Das werden wir herausfinden, wenn es soweit ist.