


Fonctionnalités




Cette page a été rédigée en anglais par nos experts, puis traduite par une IA pour vous y donner accès rapidement! Pour la version originale, c’est par ici.
(Cet article a été publié à l'origine dans le magazine php[architect] , en deux parties).
En règle générale, mentir aux gens est une mauvaise idée. Les gens n'aiment pas la malhonnêteté. Il est insultant de mentir à une personne et cela tend à détruire les relations, tant personnelles que professionnelles.
Mais les logiciels informatiques ne sont pas des personnes (Dieu merci). Pratiquement tous les logiciels d'aujourd'hui sont basés sur des mensonges, des mensonges très bien organisés et efficaces. Les mensonges rendent les systèmes informatiques modernes possibles.
La dernière génération de logiciels mensongers est celle des "conteneurs". Les conteneurs font fureur ces temps-ci : Ils rendent l'hébergement plus flexible et plus fiable ; ils facilitent la mise en place d'environnements de développement ; ils sont "comme des VM légères" ; et d'après le marketing, ils ont également bon goût et sont moins rassasiants. Mais... qu'est-ce que c'est ?
Voici le petit secret : ils n'existent pas. Sous Linux, il n'existe pas de "conteneur". C'est un mensonge. La technologie qui sous-tend l'hébergement d'Upsun est simplement une combinaison minutieuse de mensonges, jusqu'à la puce électronique. C'est là tout l'intérêt !
Pour connaître la vérité sur les conteneurs, nous devons commencer à déballer ces mensonges et voir comment un système d'exploitation moderne basé sur Linux fonctionne réellement. Avant de parler des conteneurs, nous devons d'abord parler du tout premier mensonge de l'informatique moderne : le multitâche.
Qu'est-ce qu'un processus ?
Au niveau le plus fondamental, tout ordinateur moderne est un caillou (l'unité centrale) qui a été convaincu de déplacer des électrons d'une manière spécifique sur la base d'une longue série d'instructions. Ces instructions sont toutes des opérations de très bas niveau, mais une longue série d'instructions de ce type constitue un programme. L'instruction en cours d'exécution est enregistrée dans un emplacement spécial appelé "compteur de programme" (PC).
Très souvent, un programme doit attendre s'il essaie de communiquer avec une autre partie de l'ordinateur, comme un port réseau ou une unité de disque. Pendant ce temps, il est utile que l'unité centrale puisse travailler sur d'autres instructions. Cela permet à l'ordinateur de prétendre (mentir !) qu'il exécute deux programmes "en même temps".
Le matériel de l'unité centrale a une relation spéciale avec un programme particulier, appelé système d'exploitation. Ce programme spécial est toujours le premier à démarrer et est, entre autres, responsable du "changement de contexte". À intervalles réguliers, l'unité centrale fait "tic-tac" et enregistre ce que l'on appelle une interruption de temporisation. L'unité centrale arrête alors ce qu'elle est en train de faire et charge un ensemble spécifique d'instructions du système d'exploitation dans sa mémoire active, puis continue. Cet ensemble spécifique d'instructions est connu sous le nom de "timer interruptherehandler". Il existe d'autres types d'interruptions et de gestionnaires qui ne nous intéressent pas pour l'instant. Le gestionnaire d'interruption de la minuterie choisit alors un autre programme à charger dans la mémoire de l'unité centrale et le laisse continuer. Tout ce processus peut se produire des milliers de fois par seconde, ce qui donne l'illusion (mensonge !) que l'ordinateur exécute plusieurs programmes à la fois.
La partie du système d'exploitation responsable de la permutation des différents programmes en cours d'exécution s'appelle le planificateur. Techniquement, chacun des programmes en cours d'exécution est appelé processus. Dans un système doté de plusieurs CPU ou de plusieurs cœurs, la même routine de base se produit, mais l'ordonnanceur doit garder la trace de plusieurs listes d'instructions actives, chacune avec son propre compteur de programme.
Soit dit en passant, un programme multithread est un processus unique qui peut être considéré comme ayant plus d'un compteur de programme pointant vers différentes instructions dans le même programme/processus. Lorsque le système d'exploitation change de contexte, il peut activer un compteur de programme ou un autre au sein d'un processus donné.
Qu'est-ce que la mémoire virtuelle ?
Bien sûr, les programmes ne savent pas qu'ils partagent tous le temps de la même unité centrale. Ils ne savent pas non plus qu'ils partagent tous la même mémoire système. Le programme dit d'écrire dans la mémoire à l'adresse 12345, mais il n'a pas vraiment l'adresse 12345. Le système d'exploitation s'y trouve !
Au lieu de cela, les unités centrales et les systèmes d'exploitation conspirent contre les processus et leur mentent, en leur faisant croire qu'ils disposent tous d'une longue liste d'adresses mémoire contiguës commençant à 0. Chaque programme pense qu'il dispose de cette adresse, mais il dispose en réalité d'une série de petits morceaux de mémoire, pour la plupart contigus, répartis dans tout l'espace mémoire physique de l'ordinateur. L'unité centrale traduit l'adresse de la mémoire locale du processus en adresse de la mémoire physique et vice-versa, sans que le programme s'en aperçoive. Ce concept est connu sous le nom de "mémoire virtuelle".
Cette cartographie de la mémoire présente deux avantages majeurs : la simplicité et la sécurité. Du point de vue du programme, il est beaucoup trop complexe et difficile de savoir quelle mémoire lui appartient et quelle mémoire appartient à un autre programme. La mémoire utilisée par d'autres programmes peut changer à tout moment, et aucun programmeur mortel ne sera capable d'en tenir compte manuellement. En faisant abstraction de ce problème, le programmeur n'a plus à essayer d'éviter les inévitables erreurs de gestion de la mémoire.
Ce mappage fournit également une couche de sécurité. La plupart du temps, un programme qui lit la mémoire d'un autre programme est une faille de sécurité, et la possibilité d'écrire dans la mémoire d'un autre programme l'est certainement. En ne donnant aux programmes aucun moyen de s'adresser à la mémoire des autres, il est beaucoup plus difficile pour un programme en cours d'exécution d'en corrompre un autre (plus difficile, mais pas impossible). (Plus difficile, mais pas impossible. Dans les langages où la gestion de la mémoire est manuelle, il est toujours possible de le faire en codant mal, ce qui est l'une des principales sources de problèmes de sécurité dans ces langages).
Gestion des processus
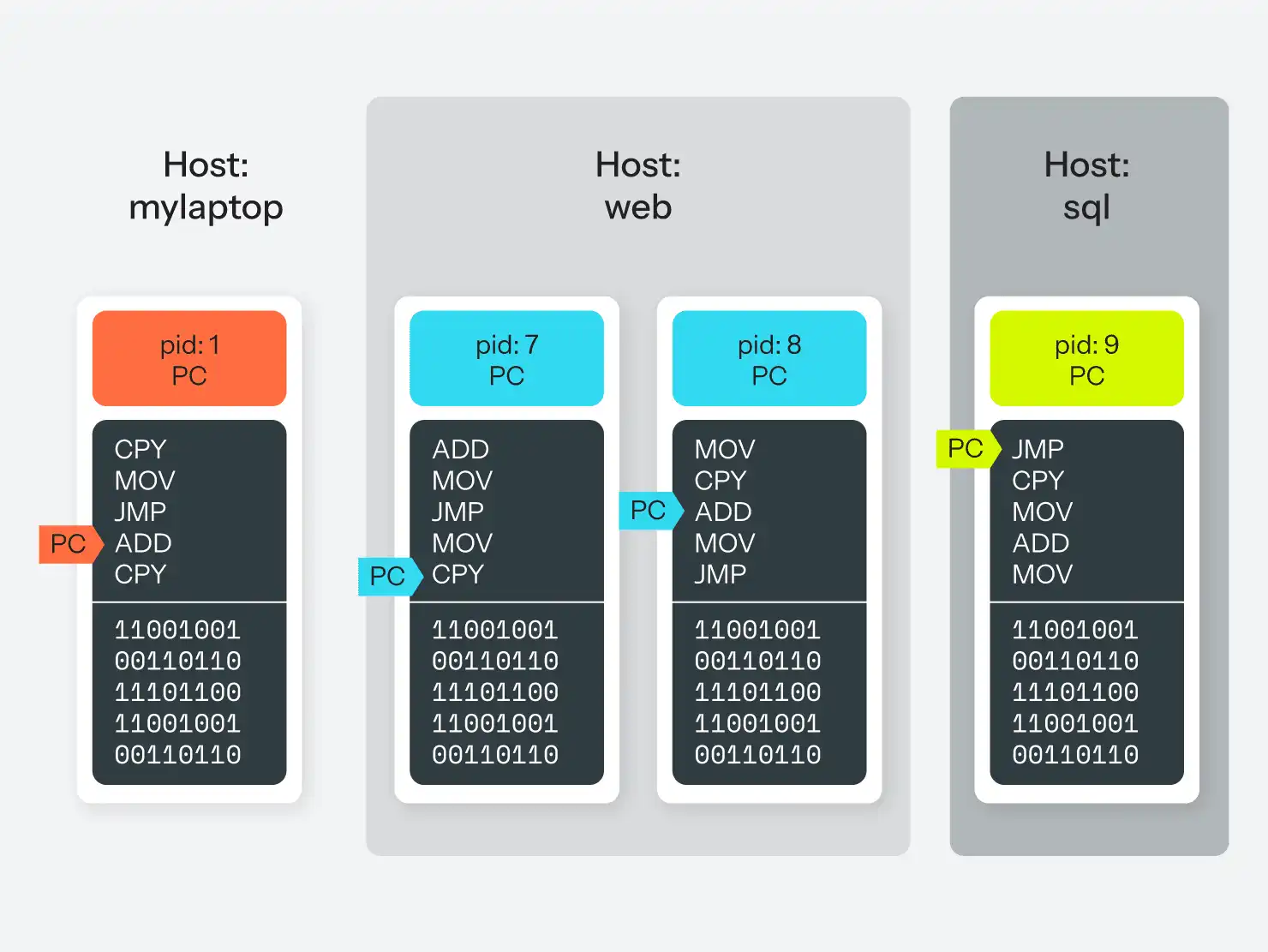
Sur un système d'exploitation de la famille Unix, les processus sont suivis dans une hiérarchie en fonction du processus qui les a lancés. Tout processus peut demander au système d'exploitation de démarrer un autre processus ou de "forker" le processus en cours en deux processus qui peuvent alors se dérouler "en parallèle". Le système d'exploitation lui-même n'a pas de processus en tant que tel, mais peut être considéré comme le processus ID 0 (ou PID 0). Dans Linux, le PID 1 est un processus spécial appelé init, qui est responsable de la gestion de tous les autres processus situés en dessous de lui. Divers programmes init ont vu le jour et ont disparu au fil des ans, du vénérable sysvinit à runit, upstart et systemd.
D'un point de vue conceptuel, l'espace mémoire d'un système Linux moderne ressemble à la figure 1.

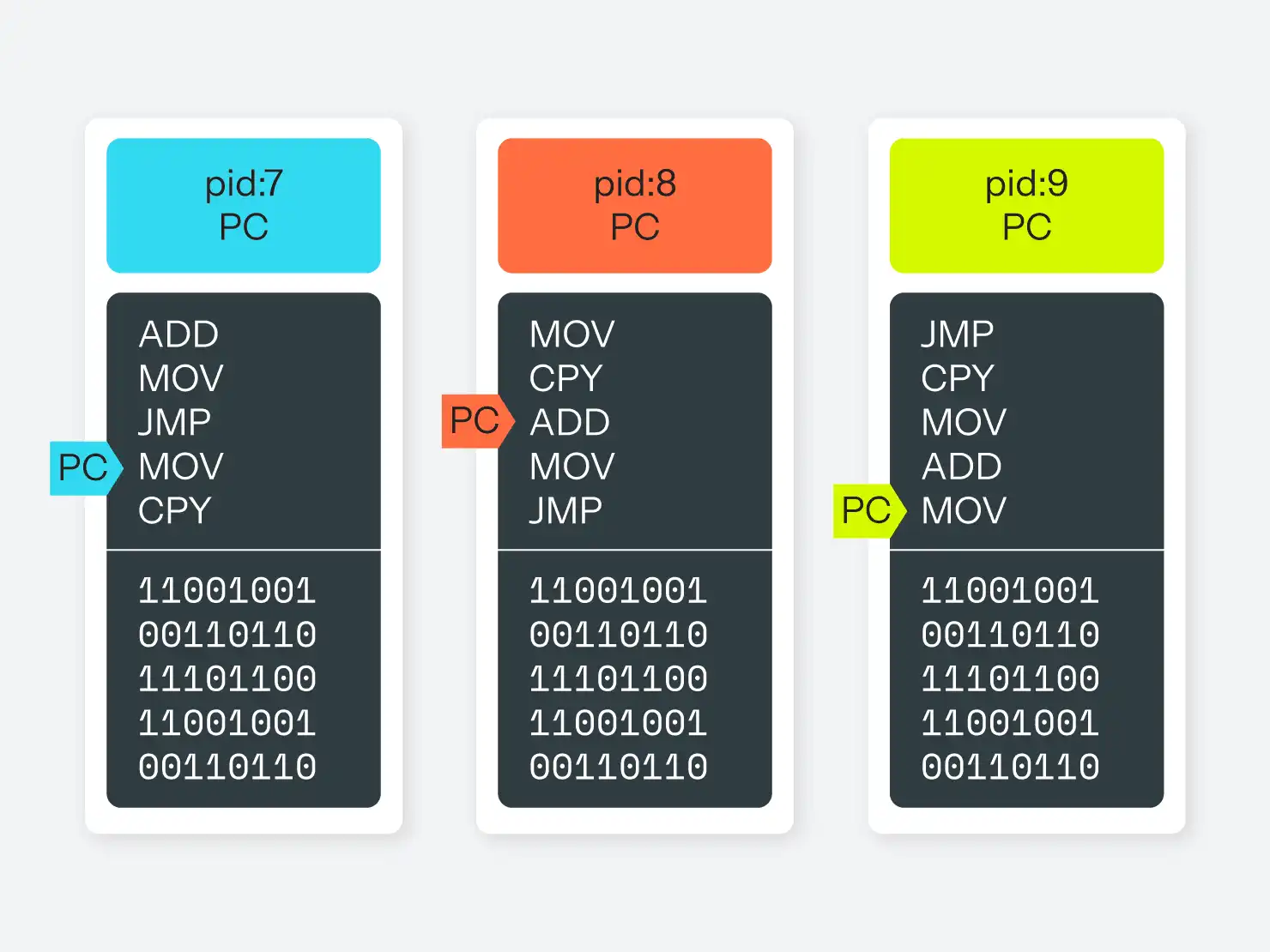
Chaque processus possède son propre espace mémoire et ne peut pas toucher directement l'espace mémoire d'un autre processus. Il peut toutefois demander au système d'exploitation de transmettre un message à un autre processus pour lui, ce qui permet aux processus de communiquer entre eux. Il existe plusieurs mécanismes pour cela, mais le plus courant est le fichier pipe, c'est-à-dire un faux fichier (mensonge !) que le système d'exploitation expose et dans lequel un processus peut écrire dans un flux et un autre processus peut lire dans un flux. Cette abstraction permet à un programme de ne pas savoir si le processus auquel il s'adresse se trouve sur le même ordinateur ou sur un autre ordinateur du réseau.
Ce qu'il est important de noter ici, c'est que chaque processus peut connaître tous les autres processus. Ils peuvent tous demander au système d'exploitation des informations sur l'ordinateur sur lequel ils s'exécutent, comme les systèmes de fichiers disponibles, les utilisateurs présents sur le système et les autorisations dont ils disposent, le nom d'hôte de l'ordinateur, les périphériques locaux ou réseau disponibles, etc. Et le système d'exploitation donnera la même réponse à chaque processus qui pose la question.
Présentation des espaces de noms Linux
Tout ce que nous avons dit jusqu'à présent s'applique plus ou moins de la même manière à tout système d'exploitation raisonnablement moderne, à quelques détails d'implémentation près. Le reste de cet article est très spécifique à Linux (c'est-à-dire au noyau Linux en particulier, et non à la plateforme GNU/Linux dans son ensemble), car à partir d'ici, beaucoup de choses varient entre les différents systèmes.
Entre le milieu et la fin des années 2000, le noyau Linux a commencé à trouver de nouvelles façons amusantes de mentir aux processus qu'il gère. Les derniers éléments n'ont pleinement fonctionné qu'en 2014 ou même 2015, mais ils sont désormais assez robustes. De plus, Linux est quelque peu unique en ce sens qu'il a mis en œuvre ces fonctionnalités de manière fragmentaire, ce qui permet aux programmes de les exploiter individuellement si nécessaire.
La plupart de ces fonctionnalités sont regroupées sous le terme générique d'"espaces de noms". Semblables aux espaces de noms des langages de programmation courants, les espaces de noms Linux permettent de segmenter les groupes de processus les uns par rapport aux autres. Plus précisément, les espaces de noms Linux permettent au système d'exploitation de s'adresser à différents groupes de processus de différentes manières à propos de différentes choses. Et comme les processus sont hiérarchisés, mentir à un processus signifie aussi mentir à tous ses processus enfants de la même manière automatiquement (à moins que ceux-ci n'aient été déplacés vers un espace de noms différent de manière explicite).
Globalement, le noyau Linux prend en charge six types d'espaces de noms.
L'espace de noms UTS
Le type d'espace de noms le plus simple est celui qui contrôle le nom d'hôte de l'ordinateur. Il existe trois appels système qu'un processus peut adresser au système d'exploitation pour obtenir et définir son nom : sethostname(), setdomainname() et uname(). En principe, il s'agit simplement de définir une chaîne globale, mais en plaçant un ou plusieurs processus dans un espace de noms UTS, ces processus disposent de leur propre "chaîne globale locale" à définir et à lire.
En pratique, votre fichier /etc/hostname peut indiquer que le nom de l'ordinateur est "homesystem", mais en plaçant votre processus MySQL dans un espace de noms, vous pouvez faire en sorte que le processus MySQL pense que le nom d'hôte est "database", alors que le reste de l'ordinateur pense toujours qu'il s'agit de "homesystem". C'est vrai, il est facile de mentir à un programme sur son identité même !
(Fait amusant : le nom UTS provient du nom de la structure du code source utilisé par uname(), utsname, qui est à son tour un acronyme pour "Unix Time-sharing System").

L'espace de noms mount
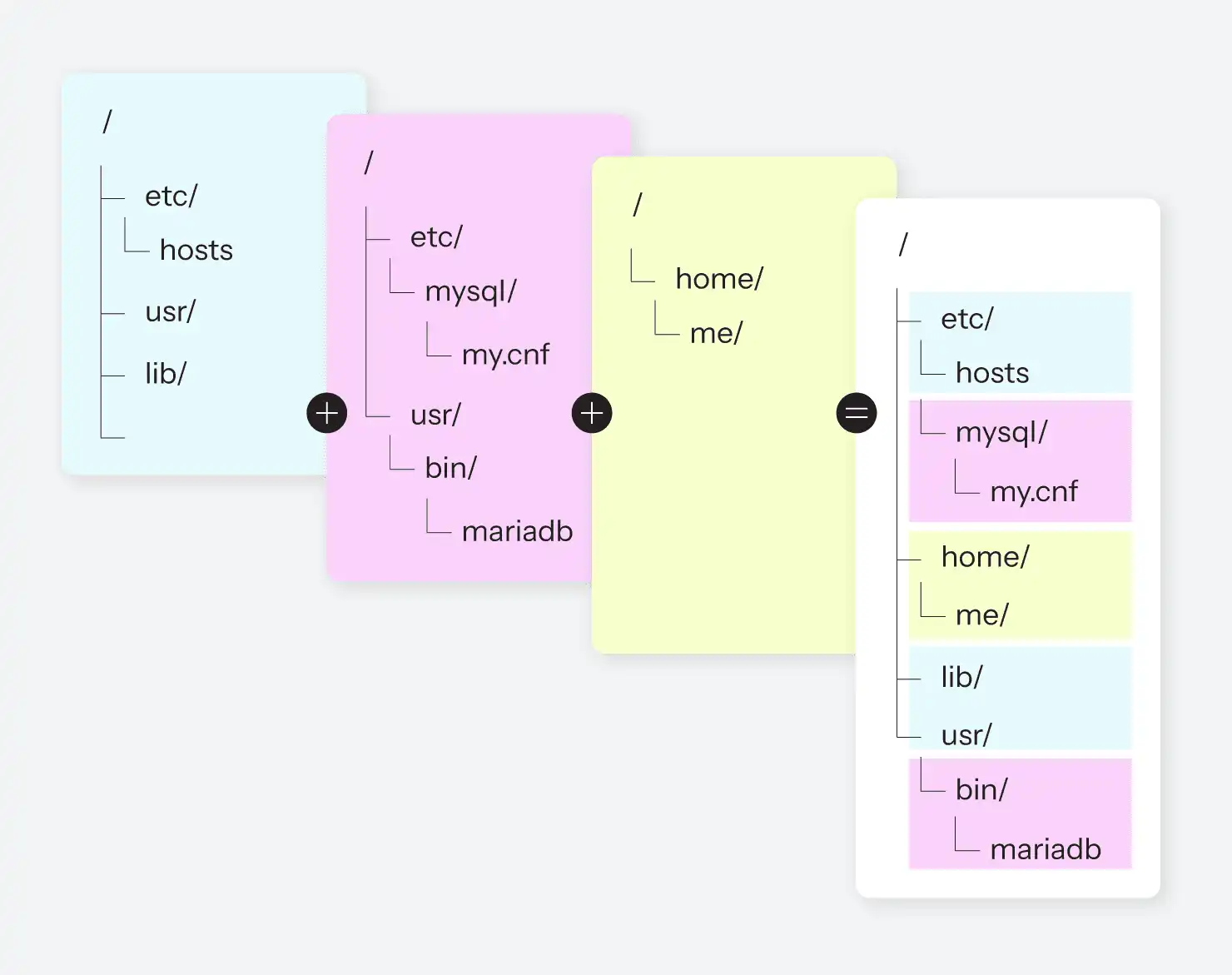
L'espace de noms le plus ancien est de loin l'espace de noms mount, qui remonte à 2002. L'espace de noms mount permet au système d'exploitation de présenter un système de fichiers différent à un ensemble de processus différent.
La commande chroot(), qui fait partie de Linux depuis pratiquement toujours, permet à un processus sélectionné (et à ses enfants) de visualiser un sous-ensemble spécifique du système de fichiers comme s'il s'agissait du système de fichiers complet. Ces "prisons chroot" étaient souvent utilisées pour essayer de segmenter un système de manière à ce que certains processus ignorent ce qu'il y a d'autre sur le même ordinateur. Il reste cependant une grande arborescence de système de fichiers. Avec un espace de noms de montage, il est possible d'avoir des arborescences de système de fichiers complètement différentes qui ne se chevauchent pas du tout et qui fonctionnent en même temps ; chaque espace de noms de montage ne voit et ne peut modifier qu'une seule de ces arborescences.
Et ce n'est pas tout ! Cela signifie non seulement que pour deux processus donnés, la racine du système de fichiers pourrait être deux partitions de disque complètement différentes, mais aussi qu'ils pourraient être deux partitions de disque complètement différentes, mais aussi monter tous les deux une troisième partition à des endroits différents dans les deux arborescences. Cela ressemble un peu à la figure 3.

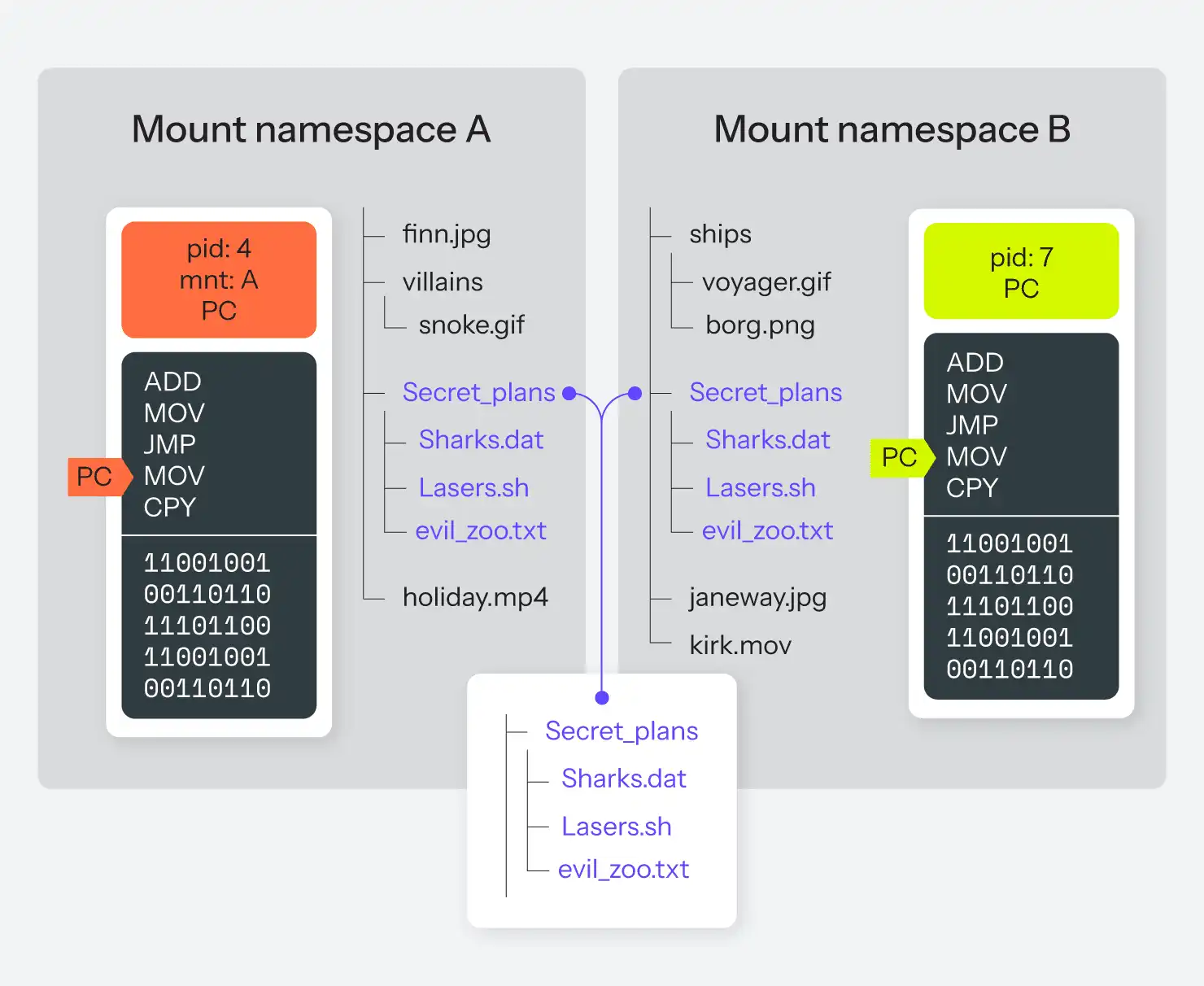
N'oubliez pas non plus que n'importe quel périphérique bloc ou pseudo-bloc peut être monté dans un système de fichiers. Il peut s'agir d'une partition sur un disque dur, mais il peut tout aussi bien s'agir d'un lecteur réseau sur un autre ordinateur, d'un périphérique amovible local tel qu'un DVD ou une clé USB, ou d'un fichier image du système de fichiers qui se trouve sur... un autre système de fichiers.
Le potentiel de mensonges et de tromperies est ici époustouflant.
Espace de noms IPC
Celui-ci est un peu obscur ; rappelez-vous que nous avons dit plus tôt que les processus pouvaient communiquer entre eux par l'intermédiaire du système d'exploitation de diverses manières. Collectivement, c'est ce qu'on appelle la communication interprocessus (IPC), et il existe des moyens standard de le faire. La plupart d'entre elles consistent simplement à transmettre des messages par l'intermédiaire de files d'attente et, en fait, il existe des API standard dans POSIX (la norme officielle qui constitue tout système *nix de bas niveau) pour celles-ci. Les espaces de noms IPC permettent au noyau de les séparer et de refuser l'accès à certains canaux IPC à certains processus, en fonction de leur espace de noms.
Espace de noms des processus
Nous arrivons maintenant à l'aspect le plus intéressant. Nous avons dit précédemment que le processus ayant le PID 1 est toujours init, et que tous les autres processus sont des enfants d'init, ou des enfants d'enfants d'init, etc. Chaque processus reçoit un PID numérique unique qui permet de le suivre.
Vous pouvez consulter les processus en cours d'exécution sur votre système à l'aide de la commande ps. Cette commande offre de nombreuses possibilités d'activation et de désactivation, mais nous n'en aborderons que quelques-unes ici.
Exécutez ps -A pour obtenir une liste de tous les processus en cours d'exécution sur le système. La sortie devrait être assez longue, mais si vous faites défiler la liste jusqu'en haut, vous verrez un PID 1, avec une colonne CMD qui indique le programme d'initialisation utilisé par votre système. Par exemple, le début de la sortie de ps pour mon système Ubuntu est le suivant :
$ ps -A
PID TTY TIME CMD
1 ? 00:00:14 systemd
2 ? 00:00:00 kthreadd
4 ? 00:00:00 kworker/0:0H
6 ? 00:00:03 ksoftirqd/0
7 ? 00:05:36 rcu_sched
8 ? 00:00:00 rcu_bh
9 ? 00:00:00 migration/0
10 ? 00:00:00 lru-add-drain
11 ? 00:00:00 watchdog/0
12 ? 00:00:00 cpuhp/0
13 ? 00:00:00 cpuhp/1
14 ? 00:00:00 watchdog/1
15 ? 00:00:00 migration/1
Bien qu'il y ait plus de 300 processus au total. L'exécution de ps xf affichera tous les processus de votre utilisateur et montrera la hiérarchie des processus qui sont enfants d'un autre processus. De même, ps axf affichera tous les processus de tous les utilisateurs du système, y compris leur hiérarchie.
Il s'agit d'une information très utile, mais il y a un problème potentiel : Vous pouvez voir exactement quels sont les processus exécutés par n'importe quel autre utilisateur sur le système ! S'agit-il d'un problème de sécurité ? Sur votre ordinateur portable, probablement pas, mais sur un système réellement multi-utilisateurs, cela pourrait l'être. Tout utilisateur malveillant (ou un programme d'un utilisateur malveillant) peut trivialement voir ce qui est en cours d'exécution et son ID, ce qui facilite l'attaque si l'attaquant connaît une autre vulnérabilité à utiliser.
Les espaces de noms PID font leur apparition. Les espaces de noms PID sont essentiellement ce que leur nom indique : Il s'agit d'un espace de noms distinct pour les identifiants de processus. Lorsque vous créez un nouvel espace de noms PID, vous spécifiez un processus qui sera le PID 1 dans cet espace de noms. Il peut s'agir d'une autre instance de votre programme init (systemd dans l'exemple ci-dessus), ou de n'importe quel processus arbitraire. Ce processus peut être connu sous le nom de PID 345 dans l'espace de noms "global", mais il est également connu sous le nom de PID 1 dans son espace de noms restreint. S'il se greffe sur un autre processus, ce dernier recevra également deux PID : 346 dans l'espace de noms parent et 2 dans son espace de noms délimité.
Cependant, et c'est là l'aspect le plus important, ce processus ne connaîtra pas les deux PID. Il s'exécute dans un espace de noms qui ne compte que deux processus, et il se reconnaîtra comme PID 2. C'est le seul PID qu'il connaîtra, et s'il demande au système d'exploitation une liste de tous les processus sur le système, il ne verra que les 2 processus dans son espace de noms (mensonge !). Il ne peut pas établir de communication avec un processus situé en dehors de son espace de noms. Il ne sait même pas qu'ils existent. Un processus de l'espace de noms parent, cependant, peut voir et initier une communication avec un processus dans l'espace de noms enfant.
Si vous avez du mal à comprendre, consultez la figure 4 pour une version visuelle.
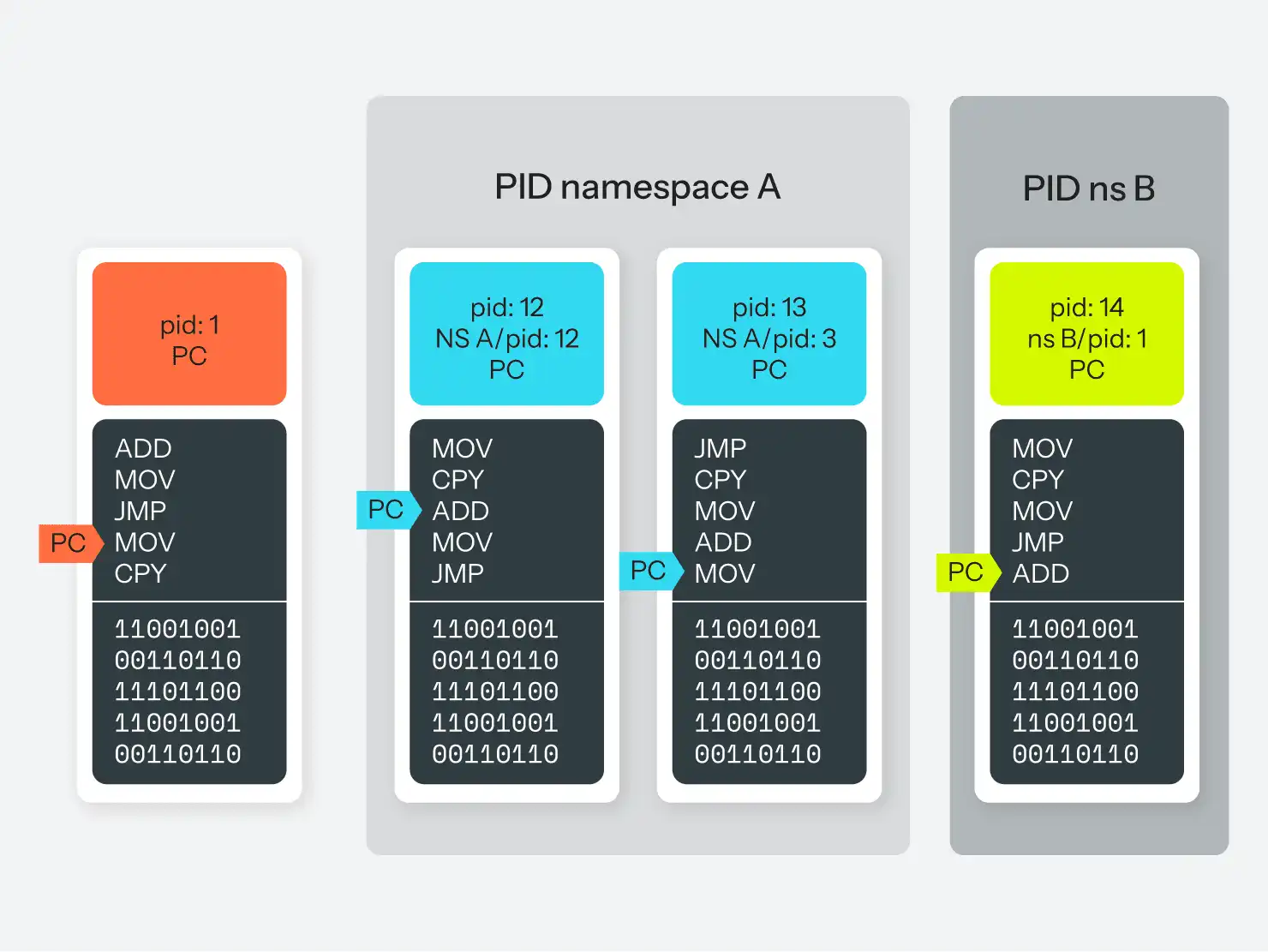
Bien entendu, comme une grande partie de la gestion des processus est gérée par le système de pseudo-fichiers /proc, les choses peuvent devenir bizarres si l'espace de noms des processus n'est pas aligné sur l'espace de noms de montage. Que ce soit bien ou mal, cela dépend de la façon dont vous l'avez configuré.
Espace de noms réseau
L'espace de noms réseau est similaire à l'espace de noms mount en ce sens qu'il permet la création d'une collection de ressources entièrement distincte. Dans ce cas, les ressources sont des périphériques réseau plutôt qu'une arborescence de fichiers. Contrairement aux espaces de noms de montage, ces ressources ne peuvent pas être partagées ; un périphérique réseau ne peut appartenir qu'à un seul espace de noms à la fois. De plus, les périphériques réseau physiques (ceux qui correspondent à une carte Ethernet ou à un adaptateur WiFi physique) ne peuvent rester que dans l'espace de noms racine, et un nouvel espace de noms réseau commence donc sa vie sans aucun périphérique, et donc sans aucune connexion avec quoi que ce soit. (Techniquement, il dispose d'un périphérique de bouclage, mais celui-ci est désactivé par défaut).
Cependant, Linux peut créer un nombre illimité de périphériques réseau virtuels (mensonges !), qui peuvent être placés dans un espace de noms réseau. Les périphériques de réseau virtuels peuvent également être créés par paires, de manière à ce qu'ils puissent être connectés l'un à l'autre, même au-delà d'une limite d'espace de noms.
Cela permet de réaliser cette astucieuse supercherie :
- Créez un nouvel espace de noms de réseau, A.
- Créez une paire d'équipements réseau virtuels en regardant l'un de l'autre. Nous les appellerons
veth0etveth1. - Gardez
veth0dans l'espace de noms racine et déplacezveth1dans le nouvel espace de noms du réseau. - Attribuez à
veth0l'adresse IP 10.0.0.1 et àveth1l'adresse 10.0.0.2. Ces deux périphériques réseau peuvent maintenant se connecter l'un à l'autre, car ils sont surveillés ensemble par le noyau. - Attribuez un ou plusieurs processus à ce nouvel espace de noms réseau, par exemple un processus nginx.
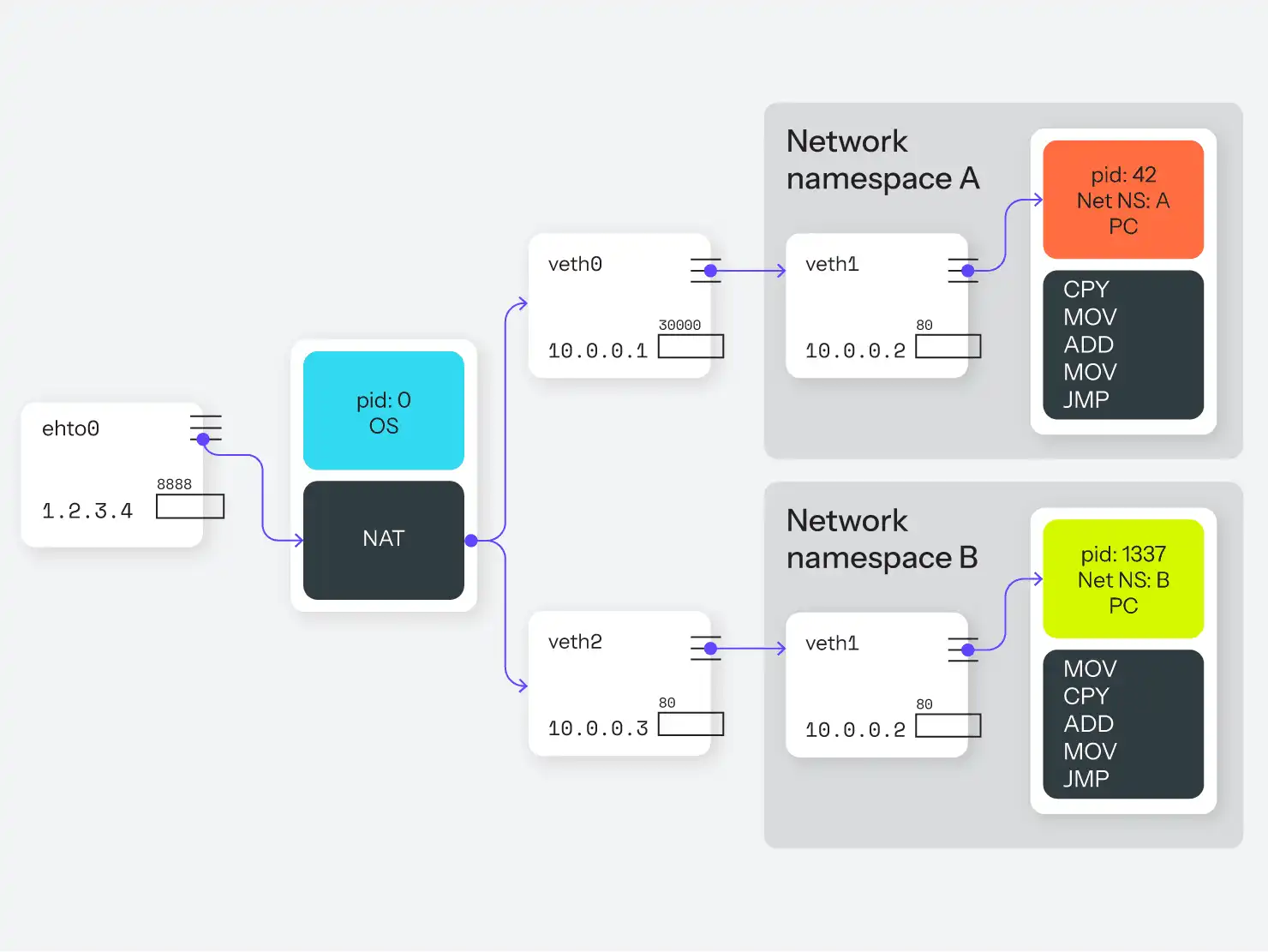
Ce processus nginx commence maintenant à écouter le port 80 sur veth1, à l'adresse 10.0.0.2. De retour dans l'espace de noms global, nous configurons des règles de routage et de pare-feu (par exemple, NAT) pour transférer les requêtes sur le port 8888 vers 10.0.0.2:80. Ainsi, les requêtes entrantes sur le port 8888 seront transférées via veth0 vers veth1 sur le port 80, jusqu'à l'endroit où nginx l'écoute.
Voir la figure 5 pour la version graphique.
Espace de noms de l'utilisateur
Enfin, l'espace de noms qui met la cerise sur le gâteau. Tous les processus, en plus de leur PID, ont un utilisateur et un groupe associés. Ces marqueurs d'utilisateur et de groupe ont à leur tour un impact sur le contrôle d'accès ; un processus ne peut pas tuer de force le processus d'un autre utilisateur, par exemple, à moins qu'il n'appartienne à root.
Avec les espaces de noms utilisateur, tout processus peut désormais créer un nouvel espace de noms utilisateur, à l'intérieur duquel ce processus est détenu par n'importe quel utilisateur, y compris root. Cela signifie que tout comme un processus peut avoir un PID dans l'espace de noms et un PID hors de l'espace de noms, un processus peut avoir un utilisateur dans l'espace de noms qui est distinct de son utilisateur hors de l'espace de noms. Son utilisateur dans l'espace de noms peut être root, ce qui lui donne un accès root à tous les autres processus de l'espace de noms, même s'il n'est qu'un processus utilisateur ordinaire dans l'espace de noms parent. De plus, si un processus appartient à root dans l'espace de noms parent, il peut définir une correspondance entre tous les utilisateurs de l'espace de noms parent et les utilisateurs de l'espace de noms enfant.
Si ce paragraphe vous a fait tourner la tête, vous n'êtes pas le seul. La figure 6 vous permettra peut-être de mieux comprendre.

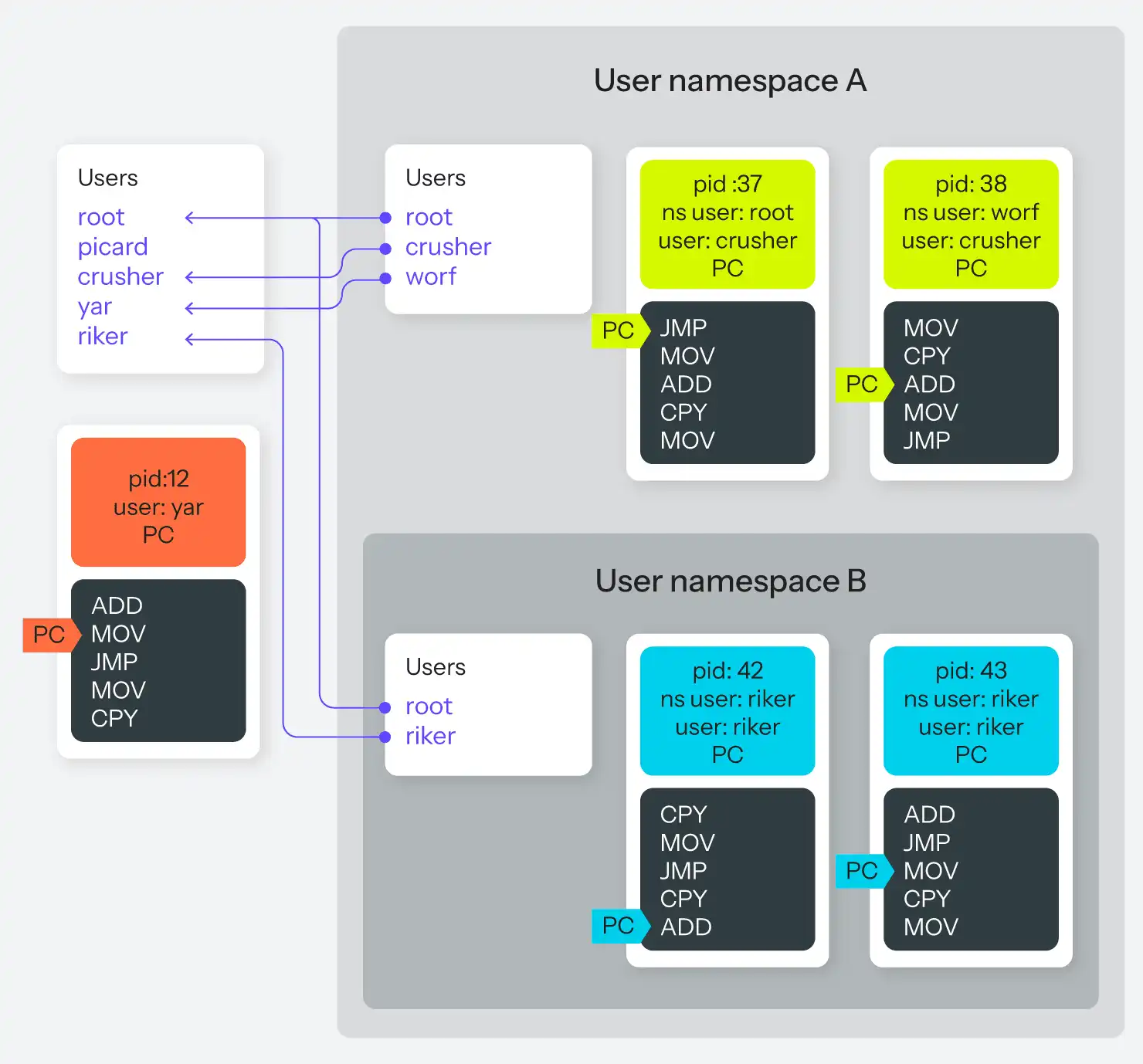
Ce qu'il faut retenir ici, c'est qu'il est désormais possible pour un processus d'avoir le pouvoir suprême sur un groupe sélectionné d'autres processus, plutôt que d'avoir le pouvoir de tout ou rien sur l'ensemble du système. Il existe de nombreuses autres conspirations pour donner aux processus des utilisateurs internes et externes, mais la racine sélective est la plus amusante.
Groupes de contrôle
L'autre pièce du puzzle n'est pas tant la tromperie que l'ajustement de l'ordonnanceur. Comme nous l'avons dit précédemment, le noyau, via l'ordonnanceur, fait entrer et sortir différents processus du processeur de temps en temps pour simuler le multitâche. Comment décide-t-il quels processus sont autorisés à passer plus ou moins de temps sur leur temps partagé avec l'unité centrale ? Il existe de nombreuses méthodes automatisées pour répartir le temps plus ou moins équitablement, mais elles partent toutes du principe qu'aucun processus particulier ne sera particulièrement gourmand. Après tout, un programme peut trivialement se diviser en plusieurs processus et obtenir ainsi des parts supplémentaires du gâteau de l'unité centrale.
Il en va de même pour l'utilisation de la mémoire. L'ordinateur dispose d'une quantité fixe de mémoire physique et, lorsque les programmes la remplissent de code et de données, le système d'exploitation commence à échanger les parties apparemment moins utilisées de la mémoire contre un espace de pagination sur le disque (appelé "périphérique d'échange" ou "fichier d'échange", en fonction de l'implémentation). Mais cela signifie toujours qu'un programme gourmand ou inefficace peut évincer d'autres processus simplement en demandant beaucoup de mémoire en même temps.
Les groupes de contrôle sont la réponse de Linux à ce problème. Les groupes de contrôle fonctionnent en créant une hiérarchie parallèle de processus, indépendante de la hiérarchie de création utilisée par les espaces de noms. Les processus peuvent alors être associés à une et une seule feuille de cette hiérarchie.
Tout nœud de cette hiérarchie peut être associé à un ou plusieurs "contrôleurs". Il existe une douzaine de contrôleurs actuellement mis en œuvre, dont certains se contentent de suivre l'utilisation des ressources, d'autres la limitent, et d'autres encore font les deux. Les deux contrôleurs les plus importants pour nos besoins sont le CPU et la mémoire, qui peuvent plafonner l'utilisation totale du CPU ou de la mémoire d'une arborescence de processus.
Par exemple, nous pouvons créer un groupe de contrôle de processus, y affecter tous les processus nginx et y placer un contrôleur qui limite l'utilisation du CPU à 25 % et les restreint à deux des quatre cœurs de CPU de l'ordinateur. Nous pouvons ensuite créer un autre groupe de contrôle, y affecter le processus MariaDB et le restreindre à 100 % de l'un des CPU restants. Maintenant, bien qu'il soit toujours possible qu'une mauvaise requête fasse consommer à MariaDB tout son temps de CPU disponible, cela n'aura pas d'impact sur les processus nginx en cours d'exécution. Ils sont séparés par des CPU différents et des limites d'utilisation, de sorte que si MariaDB peut ralentir, nginx continuera à fonctionner, ainsi que tous les autres processus dans le groupe de contrôle de haut niveau. (Voir la figure 7.)

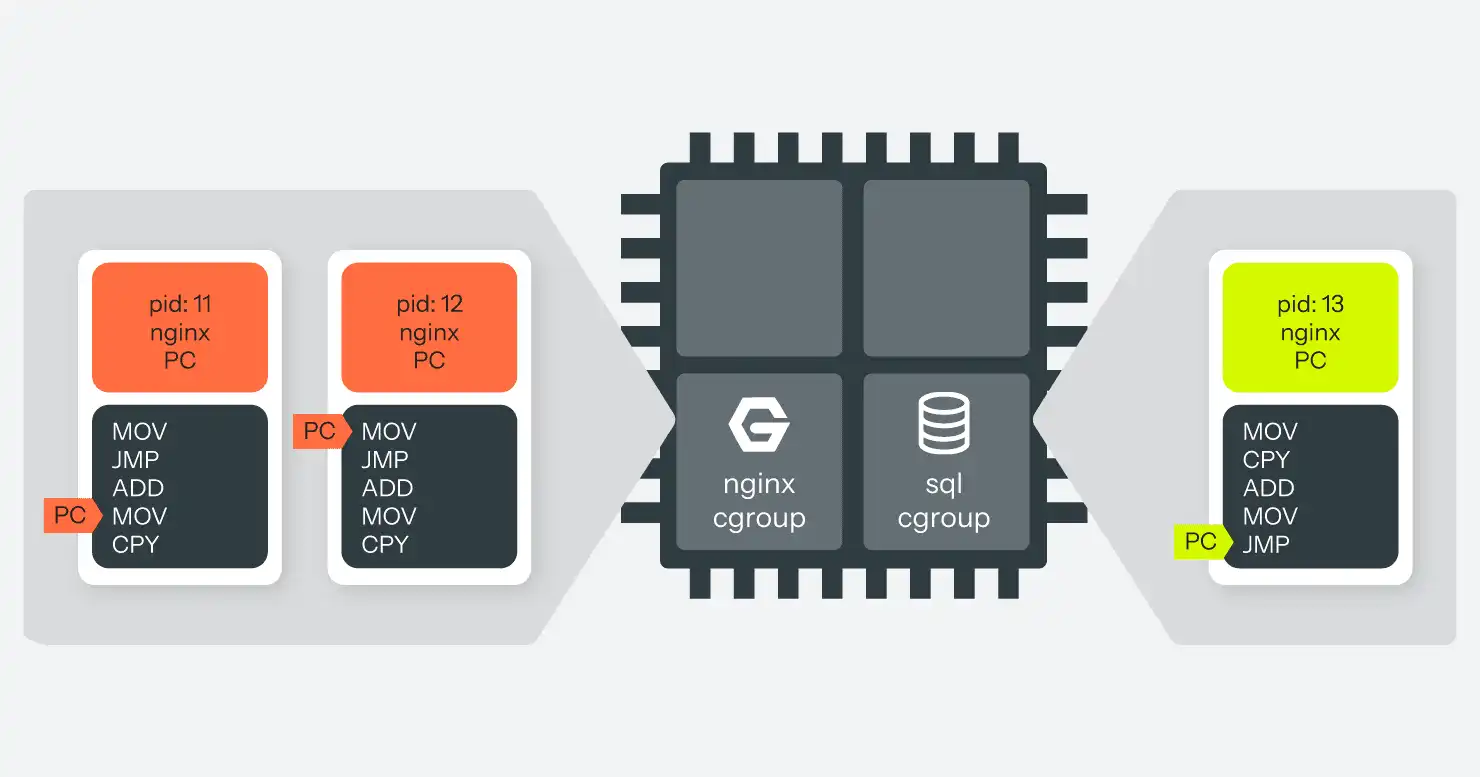
Un processus dans un groupe de contrôle sait toujours qu'il est dans un groupe de contrôle et qu'il ne reçoit qu'une partie des ressources totales du système. Cependant, à moins que le processus ne soit détenu par root, il ne sera pas en mesure de modifier cette configuration.
Chevauchement des espaces de noms
Il est important de noter que sous Linux, contrairement à la plupart des anciens Unix, chacun de ces espaces de noms et groupes de contrôle est distinct. Il est tout à fait possible que les processus 2, 3 et 4 partagent un espace de noms mount, alors que le processus 3 se trouve également dans un espace de noms user et que le processus 4 se trouve dans un espace de noms UTS. Vous pouvez alors placer les processus 2 et 4 dans un cgroup très limité en termes de CPU, tandis que le processus 3 dispose d'autant de temps CPU qu'il le souhaite.
Une telle configuration, bien que possible, est également assez complexe. Bien qu'il puisse en résulter une fonctionnalité tout à fait fascinante, elle peut aussi aboutir à un désordre totalement inutilisable. Plus généralement, seules quelques caractéristiques de l'espace de nommage sont utilisées pour atteindre des objectifs de segmentation très spécifiques.
La combinaison la plus pratique et la plus applicable est cependant "tout ce qui précède", comme le montre la figure 8. Considérons que nous pouvons maintenant créer un groupe de processus qui :
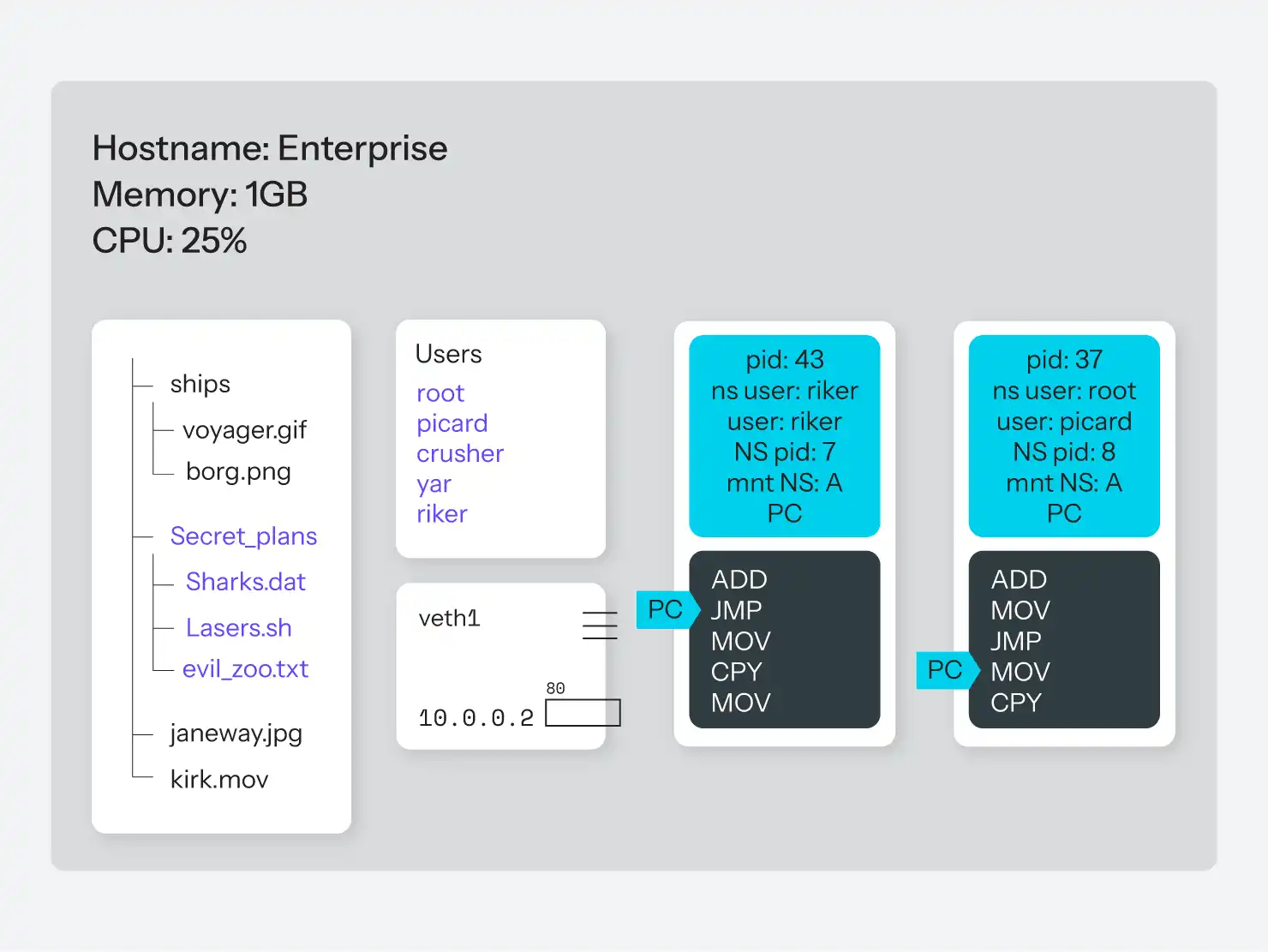
- Ne connaissent que les uns des autres, à l'exclusion de tout autre processus sur le système.
- L'un d'entre eux pense avoir accès à la racine, et les autres processus pensent qu'il s'agit de la racine, mais ce n'est pas le cas sur l'ensemble du système.
- ont leur propre arborescence de fichiers, de haut en bas, et n'ont aucun moyen d'accéder à d'autres systèmes de fichiers
- Ont leur nom d'hôte.
- ont leur adresse IP qu'ils pensent utiliser, avec leur propre jeu de ports, et même leurs propres règles de routage IP pour l'accès au réseau.
- Ils n'ont aucun moyen d'accéder à des processus extérieurs à ce groupe, ni même de savoir qu'il existe des processus extérieurs à ce groupe.
- n'utiliseront pas, collectivement, plus de 25 % du temps de l'unité centrale et pas plus de 256 Mo de mémoire vive.
En ce qui concerne un processus de ce groupe, quelle est la différence avec un processus fonctionnant sur son ordinateur complet ? En pratique, très peu. Il offre presque toute la puissance d'isolation des machines virtuelles, mais avec une fraction infime des frais généraux ; en fait, les seuls frais généraux sont les tables de consultation du noyau pour garder la trace des mensonges qu'il dit à tel ou tel processus. La seule limitation est qu'il n'y a toujours qu'une seule instance du noyau qui fonctionne et qui contrôle tout.
Cette combinaison de mensonges "tout ce qui précède" est si souvent souhaitée qu'elle porte même un nom commun : les conteneurs.
En fin de compte, c'est tout ce qu'est un "conteneur" : C'est un nom abrégé pour "utiliser tous les espaces de noms mensongers en même temps pour tromper les processus en leur faisant croire qu'ils tournent sur leur propre ordinateur alors que ce n'est pas le cas". Et cela s'avère extrêmement puissant.
Abstractions de conteneurs
Alors que le noyau offre toutes sortes d'API pour manipuler les espaces de noms et les processus à un niveau fin, cela n'est souvent pas très utile lorsqu'on essaie de construire un système à un niveau plus grossier, comme un "conteneur" de macros. C'est pourquoi, comme c'est souvent le cas en programmation, divers autres outils ont vu le jour pour abstraire ces API de bas niveau en API de plus haut niveau plus faciles à utiliser. Il existe de nombreux systèmes de ce type écrits dans différents langages. Tout langage capable d'émettre des commandes libc peut fonctionner.
Il existe de nombreux outils d'abstraction de ce type, qui font tous plus ou moins la même chose. En voici quelques-uns dont vous avez peut-être entendu parler.
- LXC (pour LinuX Containers, écrit en C) : https://linuxcontainers.org/
- Docker (écrit en Go) : https://www.docker.com/
- lmctfy (abréviation de Let Me Contain That For You) : https://github.com/google/lmctfy/
- Rocket / CoreOS : https://github.com/coreos/rocket
- Vagga (écrit en Rust) : https://github.com/tailhook/vagga
- Bocker (écrit en Bash) : https://github.com/p8952/bocker
Une liste encore plus importante peut être trouvée sur https://dogger.io/, et au moins Bocker vaut la peine d'être examiné juste pour voir à quel point un tel système peut être basique.
Docker est de loin l'outil de gestion de conteneurs le plus populaire, bien qu'il ne soit ni le premier ni le plus récent. Il s'est simplement avéré être la nouvelle option à la mode lorsque le marché a décidé qu'il était "prêt" pour les conteneurs. À l'origine, il a été conçu comme une couche supplémentaire au-dessus de LXC, bien qu'il ait depuis remplacé sa dépendance à LXC par sa bibliothèque, appelée runC.
Bien qu'il soit un peu plus bas que ce que la plupart des utilisateurs finaux et des administrateurs système souhaiteraient, LXC est l'une des options les plus puissantes. Il dispose également de bindings permettant d'automatiser davantage ses capacités à l'aide de divers langages, notamment C, Python, Go et Haskell.
Quel que soit l'outil, il s'agit simplement d'abstractions permettant de dire "démarrer un processus, créer un certain nombre d'espaces de noms sur ce processus, et y monter ce système de fichiers". Cette routine est généralement appelée "démarrage" d'un conteneur.
Orchestration
Une autre couche d'abstraction souvent utilisée est l'"orchestration". L'orchestration est une autre couche d'abstraction au-dessus du logiciel de conteneur. D'une manière générale, il s'agit simplement d'un code qui coordonne la copie des images du système de fichiers entre plusieurs ordinateurs, qui appelle le logiciel de conteneur sur chaque ordinateur et lui demande de démarrer un conteneur, puis qui indique au logiciel de conteneur comment configurer ce conteneur (notamment les détails à mettre en place pour les différents espaces de noms et cgroups).
Dans la pratique, il est courant de vouloir utiliser plusieurs conteneurs en tandem, en communiquant comme s'ils étaient sur un réseau alors qu'il s'agit en réalité de processus différents sur le même ordinateur. La configuration manuelle est généralement simple mais très fastidieuse. Les systèmes d'orchestration automatisent la tâche consistant à créer plusieurs conteneurs et à les connecter avec une syntaxe plus agréable. Kubernetes est le grand nom de cet espace à l'heure actuelle, mais de nombreux autres exemples existent, y compris Upsun lui-même.
Conteneurs en lecture seule
Il est très courant que les implémentations de conteneurs encouragent ou exigent l'utilisation de systèmes de fichiers en lecture seule. Il y a plusieurs raisons à cela. Tout d'abord, c'est tout simplement très efficace. Linux est tout à fait capable de prendre un instantané d'un système de fichiers et d'en produire une représentation en un seul fichier, qui peut ensuite vivre sur un autre système de fichiers. (Pensez aux images du système de fichiers "ISO" pour les CD et les DVD. De nombreux autres formats similaires sont disponibles). Lors de la création d'un conteneur, il est donc très facile de placer ses processus dans un espace de noms de montage, puis de monter ce fichier image du système de fichiers en tant que racine dans l'espace de noms de montage. Maintenant, tout processus dans le conteneur, c'est-à-dire dans l'espace de noms de montage, verra ce système de fichiers comme l'univers entier.
Ce qui est utile, cependant, c'est de faire plusieurs copies de ce conteneur. Deux conteneurs différents (c'est-à-dire des espaces de noms de montage) peuvent utiliser la même image de système de fichiers comme point de montage racine. Si l'image est accessible en écriture, cela soulève toutes sortes de questions sur la manière de synchroniser les écritures entre les deux conteneurs. Que se passe-t-il si un processus dans un conteneur effectue une modification importante pour un processus dans l'autre conteneur ? La réponse est "c'est le bordel".
Toutefois, si le système de fichiers est en lecture seule, non seulement les problèmes de synchronisation sont évités, mais le système d'exploitation n'a besoin que d'une seule copie. Deux, trois ou 30 espaces de noms de montage (conteneurs) peuvent monter la même image de système de fichiers de 10 Go sur leur répertoire racine, mais le système d'exploitation n'a besoin de lire les données qu'une seule fois. Et comme il n'a pas besoin de charger l'ensemble du système de fichiers en mémoire, cela signifie que la surcharge de mémoire pour démarrer 30 conteneurs avec ce même système de fichiers de 10 Go est de quelques Ko de données comptables à l'intérieur du système d'exploitation pour garder ses mensonges corrects.
Bravo aux machines virtuelles !
Portabilité des conteneurs
Le marketing autour des conteneurs fait souvent référence aux conteneurs d'expédition, qui ont révolutionné l'industrie du fret en créant des boîtes de taille standard dans lesquelles les objets les plus encombrants pouvaient être placés, puis empilés proprement sur les navires, les camions et les avions. Le discours commercial prétend souvent qu'un conteneur est un format standard qui peut être utilisé "n'importe où", tout comme les conteneurs d'expédition.
Malheureusement, ce marketing n'est pas seulement erroné, il est aussi complètement à l'envers. Il s'agit encore d'un mensonge.
En règle générale, les instantanés du système de fichiers, ou "images", dont nous avons parlé précédemment sont configurés pour ne fonctionner correctement que lorsqu'ils sont chargés par une bibliothèque d'abstraction de conteneur spécifique. Ils incluent souvent non seulement un système de fichiers, mais aussi des métadonnées que la bibliothèque d'abstraction utilise pour décider des espaces de noms et des cgroups à configurer. Ce conteneur doit-il avoir un espace de noms réseau qui autorise l'accès sortant ? Sur quels ports ? Quels systèmes de fichiers supplémentaires doivent être montés ? Toutes ces métadonnées sont dans un format spécifique à la bibliothèque. Une image construite par Docker ne fonctionnera pas sur Vagga ou LXC, et vice versa.
Si elles ne sont pas portables, quel est l'avantage ?
L'avantage vient de l'intérieur. Presque tous les programmes importants reposent sur des centaines d'autres programmes et bibliothèques. Ceux-ci sont généralement installés par la distribution Linux à des versions fixes connues... ou du moins à des versions essentiellement connues et fixes. Ils sont corrigés en permanence au fur et à mesure que les bugs et les failles de sécurité sont corrigés (ou introduits). Lorsque les gens parlent de "faire correspondre la production à la mise en scène", ils parlent de la longue combinaison de versions possibles de diverses bibliothèques. Même un simple script PHP repose sur Apache ou Nginx, PHP-FPM, le moteur PHP lui-même, les extensions PHP, les bibliothèques C utilisées par ces extensions, et probablement une douzaine d'autres choses. Dans un monde idéal, les différentes combinaisons de bibliothèques fonctionneraient parfaitement, mais nous savons tous que la réalité est rarement idéale et qu'il peut être fastidieux de trouver des bugs introduits lorsque la combinaison est différente.
Ce que les conteneurs vous offrent, c'est la possibilité de regrouper toutes ces bibliothèques dans un instantané du système de fichiers. Presque invariablement, un programme (processus) en démarre un autre en demandant au système d'exploitation : "Démarrer un nouveau processus utilisant ce fichier sur le disque". Si le "disque" qu'il connaît est un montage à l'intérieur d'un espace de noms de montage, et que ce montage est un fichier image du système de fichiers, vous pouvez maintenant contrôler étroitement la version exacte de chaque dépendance que vous mettez dans cette image du système de fichiers. La seule exception notable est le noyau lui-même. Tout le reste peut être livré avec votre programme.
C'est comme si vous aviez un lien statique avec l'ensemble de votre ordinateur ! Ce qui signifie que, oui, vous devez à nouveau compiler des choses, même si vous écrivez dans un langage de script comme PHP ou Node.
Ce que les conteneurs vous apportent, c'est la possibilité de livrer non pas votre application, mais votre application et toutes ses dépendances, épinglées à une version précise. Lorsque vous chargez ce conteneur sur un autre ordinateur, il démarre un espace de noms PID, un espace de noms mount, un espace de noms utilisateur, etc., autour de l'ensemble des dépendances que vous fournissez et utilise (potentiellement) des cgroups pour contenir tous ces processus à un fragment des ressources sur le matériel réel. Cette image du système de fichiers peut également être raisonnablement petite, puisque vous savez de quels outils vous aurez besoin et que vous pouvez n'inclure que ceux-là. Le mensonge de votre application est maintenu ; elle ne sait pas si elle s'exécute dans un conteneur ou non, et elle ne devrait pas s'en soucier.
C'est aussi la raison pour laquelle les langages qui compilent en un seul exécutable comme Go (ou Rust, en fonction de vos paramètres) sont bien adaptés aux configurations de conteneurs. Ils regroupent déjà toutes leurs dépendances en un seul programme, de sorte que le "système de fichiers plein de dépendances" dont vous avez besoin est trivialement petit : souvent, c'est juste l'exécutable du programme lui-même.
Parce que les frais généraux de chaque conteneur sont si faibles, l'exécution de 50 copies d'un conteneur n'est pas plus coûteuse que l'exécution de 50 copies du même programme sans conteneur. Avec les cgroups, il est peut-être moins coûteux et certainement plus facile de les empêcher de se heurter les uns aux autres. Contrairement aux machines virtuelles, où chaque instance ajoute non seulement quelques processus en cours d'exécution et un peu de comptabilité, mais aussi des copies complètement dupliquées du noyau Linux, de tous les outils de l'espace utilisateur et de n'importe quel programme que vous essayez d'exécuter.
Les conteneurs chez Upsun
Il existe de nombreuses façons de mettre en place cette nouvelle flexibilité, dont beaucoup ne sont applicables que dans certaines situations. Comme exemple pratique, regardons comment notre implémentation de conteneurs ici à Upsun gère les conteneurs pour les clients et comment elle diffère de Docker, qui est largement utilisé pour le développement local.
Upsun traite les images de conteneurs comme un artefact de construction. En d'autres termes, ce qui se trouve dans le dépôt Git de votre projet n'est pas ce qui est déployé en production. Nous vérifions plutôt ce qui se trouve dans Git, puis nous exécutons votre "hook de construction" à partir du fichier upsun/config.yaml dans votre référentiel. Cela peut inclure le téléchargement des dépendances avec Composer, npm, les modules Go, etc., ainsi que la compilation des fichiers Sass ou Less, la minimisation des scripts JS, ou toute autre commande de construction que vous souhaitez. Le résultat est juste "un tas de fichiers sur un disque" sur un serveur de compilation.
Ce "tas de fichiers sur le disque" est ensuite compressé dans un fichier squashfs. Squashfs est un système de fichiers compressé, en lecture seule, qui est lui-même un fichier unique sur le disque, un peu comme une image ISO. Cette "image d'application" est ensuite téléchargée, avec les métadonnées dérivées de vos fichiers de configuration, dans l'une des nombreuses machines virtuelles en cours d'exécution.
Sur la VM, nous assemblons alors un conteneur. Upsun utilise LXC, plutôt que Docker, car il offre une plus grande flexibilité de bas niveau, sur laquelle nous avons notre propre logiciel de coordination et d'orchestration. La première étape consiste à créer un nouveau conteneur LXC, qui indique à LXC de créer un nouveau processus init (nous utilisons runit) avec ses espaces de noms mount, pid, UTS, network et user.
Dans cet espace de noms mount, nous montons ensuite une image de base, telle que définie par les métadonnées susmentionnées. L'image de base est un fichier squashfs contenant une installation Debian minimale avec un langage d'exécution et une version choisis par l'utilisateur : PHP 8.4, Python 3.12, ou Go 1.18, par exemple. C'est maintenant le système de fichiers que tout processus dans le conteneur (c'est-à-dire dans tous ces espaces de noms) verra. Et comme il s'agit d'une image standard et commune, des dizaines de conteneurs peuvent être exécutés sur la même machine virtuelle sans presque aucune surcharge.
Ensuite, l'image de l'application fournie par l'utilisateur est montée à un emplacement standard, à savoir /app. Elle contient tout le code de l'utilisateur, qui varie évidemment d'un projet à l'autre, mais qui est généralement beaucoup plus petit que tout le reste de l'image partagée du système d'exploitation. Enfin, les métadonnées de configuration définissent également divers points de montage accessibles en écriture ; ceux-ci font partie d'un système de fichiers réseau accessible en écriture exposé pour chaque conteneur et monté dans l'arborescence de fichiers du conteneur à l'endroit où la configuration indique de les monter. Le résultat est un système de fichiers composé d'une image squashfs largement partagée, d'une image squashfs spécifique à l'application et de zéro ou plusieurs montages de fichiers réseau.
Une fois le système de fichiers assemblé, l'étape suivante consiste à configurer les processus. Si une application nécessite une configuration supplémentaire, ces fichiers de configuration sont générés sur un petit disque RAM inscriptible (là encore, limité à l'espace de noms du montage). Par exemple, pour PHP, le fichier php.ini et la configuration de PHP-FPM seront générés dans ce répertoire. Sur un conteneur Ruby, il s'agira de fichiers différents. Tous les conteneurs incluent également Nginx, de sorte que le fichier nginx.conf est également écrit dans ce répertoire. L'image de base inclut des liens symboliques vers l'emplacement de ces fichiers de configuration, ce qui permet au moteur d'exécution de les trouver. (Voir Figure 9.)

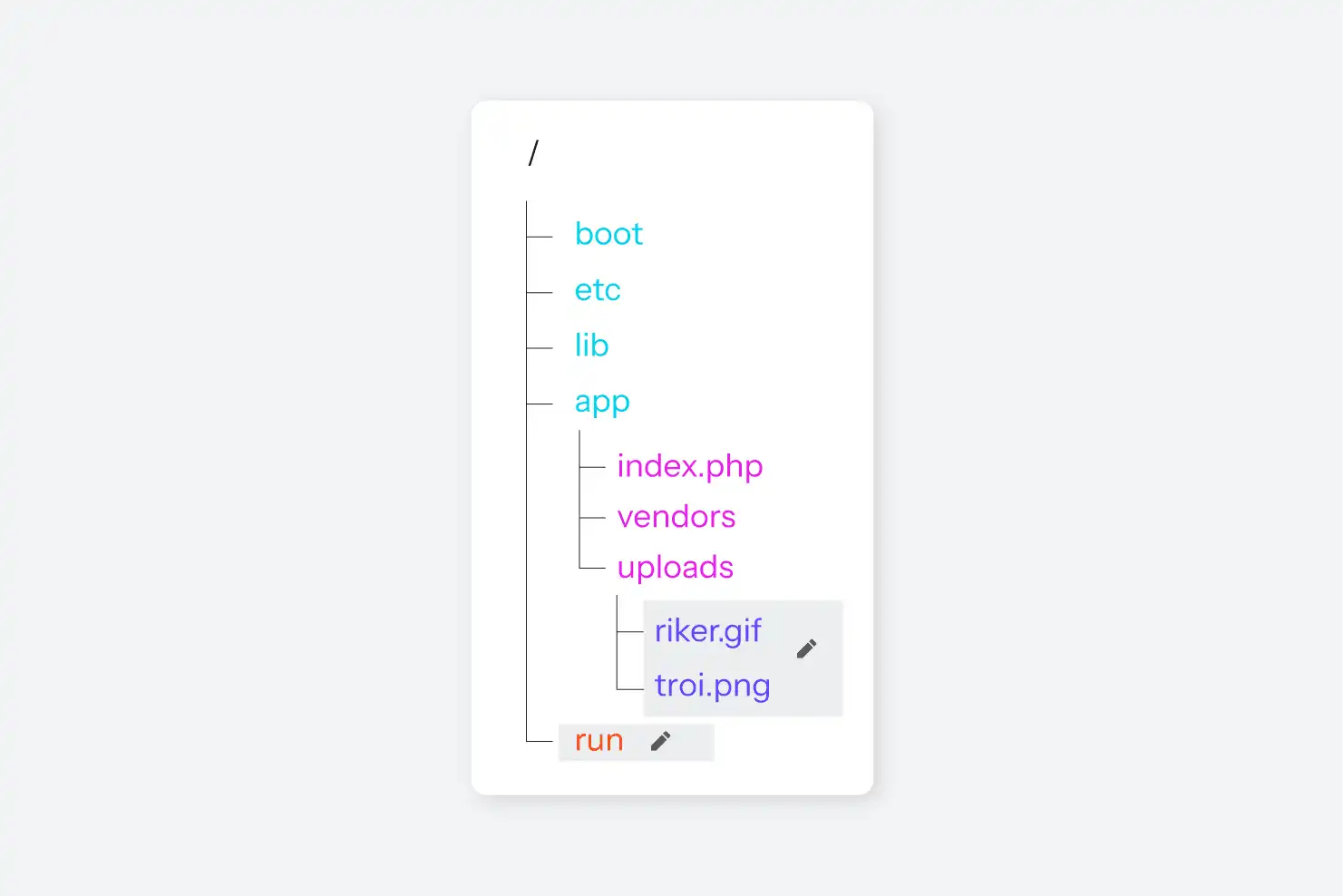
LXC permet aux processus de l'espace de noms parent d'appeler dans un conteneur et d'exécuter une commande arbitraire dans le conteneur (dans tous les espaces de noms correspondants), ce qui est la façon dont toute la logique de contrôle est construite. La dernière étape consiste à indiquer au processus init à l'intérieur du conteneur de démarrer les quelques processus dont il a besoin : SSH, nginx, et PHP-FPM s'il s'agit d'un conteneur PHP. Un ps axf exécuté depuis l'un de ces conteneurs ne montre que les quelques processus qui font partie de l'espace de noms PID du conteneur :
$ ps axf
PID TTY STAT TIME COMMAND
1 ? Ss 0:06 init [2]
72 ? Ss 0:06 runsvdir -P /etc/service log: .................................................................
78 ? Ss 0:00 \_ runsv ssh
105 ? S 0:00 | \_ /usr/sbin/sshd -D
20516 ? Ss 0:00 | \_ sshd: web [priv]
20518 ? S 0:00 | \_ sshd: web@pts/0
20519 pts/0 Ss 0:00 | \_ -bash
20605 pts/0 R+ 0:00 | \_ ps axf
79 ? Ss 0:00 \_ runsv nginx
99 ? S 0:00 | \_ nginx: master process /usr/sbin/nginx -g daemon off; error_log /var/log/error.log; -c /
104 ? S 0:00 | \_ nginx: worker process
80 ? Ss 0:00 \_ runsv newrelic
81 ? Ss 0:00 \_ runsv app
89 ? Ss 0:22 \_ php-fpm: master process (/etc/php/7.3/fpm/php-fpm.conf)Voilà, c'est fait. La machine virtuelle sur laquelle tourne le conteneur aura des milliers de processus en cours d'exécution, mais dans cet espace de noms PID, il n'y a que ssh, nginx, et PHP-FPM pour PHP 7.3, plus quelques petits processus de coordination utilisés par runit. Le noyau connaîtra ces processus à la fois par les pids listés ci-dessus et par un autre PID du système, mais de l'intérieur du conteneur, il n'y a aucun moyen pour nous de savoir ce que sont ces processus ou même de savoir qu'il y a d'autres processus, d'ailleurs.
Enfin, le logiciel de coordination demande au système d'exploitation de placer tous ces processus dans un cgroup afin de limiter leur utilisation collective du processeur et de la mémoire. Le niveau de restriction est basé sur la taille du plan du projet.
Voilà pour l'application elle-même. Cependant, une application web moderne ne se résume pas à des scripts autonomes. Selon l'application, elle peut inclure une base de données MySQL ou MariaDB, MongoDB, une base de données Redis, Memcache, éventuellement un serveur de file d'attente, et bien d'autres choses encore. Tout cela est contrôlé par le fichier services.yaml du référentiel. Si les fichiers services.yaml indiquent que "ce projet a besoin d'un serveur MariaDB, d'un serveur Elasticsearch et d'un serveur de cache Redis", le logiciel de coordination créera trois conteneurs supplémentaires, un pour chacun de ces services. Le processus est essentiellement le même que pour le conteneur d'application, sauf qu'il n'y a pas d'image d'application à monter. Il y a juste une image de base pour le service (MariaDB, Elasticsearch et Redis) et un montage accessible en écriture pour les fichiers de données du service. Pour le reste, le processus est identique.
En outre, comme chacun de ces conteneurs implique un nouvel espace de noms réseau, aucun d'entre eux n'est en mesure de communiquer avec le monde extérieur par défaut. Cela signifie que le conteneur d'application peut communiquer avec le port virtuel 3306 du conteneur MariaDB, mais avec aucun autre port. Et le conteneur MariaDB n'a aucun moyen de communiquer avec le conteneur Redis ou tout autre conteneur qui ne se connecte pas d'abord à lui. Et ainsi de suite.
Au final, la création de ces quatre conteneurs (c'est-à-dire quatre espaces de noms UTS, quatre espaces de noms PID, quatre espaces de noms utilisateur et quatre espaces de noms réseau) est minime, peut-être une seconde ou deux. Comparé au temps nécessaire au démarrage des processus eux-mêmes, à la copie de l'image de l'application dans la VM et à la comptabilité du logiciel de coordination, il s'agit d'une erreur d'arrondi.
Étant donné que les conteneurs sont si rapides, qu'ils ne sont qu'une table de recherche de mensonges, et que la majeure partie du système de fichiers est en lecture seule, il devient pratique de gérer les nouveaux déploiements de la même manière : Il suffit de tuer tous les processus impliqués et de les redémarrer. Mais nous pouvons aussi être plus intelligents. Si, par exemple, seul le code de l'application a changé, aucun des conteneurs de services backend n'a besoin d'être complètement arrêté et redémarré. Seuls les montages de fichiers sur le conteneur d'application sont mis à jour pour pointer vers une nouvelle version de l'image de l'application. Si une version plus récente de l'image de base est disponible (une nouvelle version de correction de bug de Node.js, par exemple) ou si la configuration a changé et demande maintenant une nouvelle version (pour passer de PHP 7.3 à 7.4), le conteneur d'application est complètement arrêté et redémarré avec la nouvelle image de base. Dans les deux cas, les conteneurs de service n'ont rien à faire jusqu'à ce que leur configuration change également.
Un autre avantage de la table de consultation des mensonges est que la création de plusieurs copies d'un conteneur ne prend qu'un temps supplémentaire minime. La création d'une nouvelle copie de test de l'ensemble de la base de code, des services et de tout le reste, consiste simplement à créer plus d'espaces de noms pour que le noyau puisse mentir et à monter à nouveau les mêmes images de système de fichiers dans le nouvel espace de noms de montage.
Pour Upsun, chaque branche de Git correspond à un "environnement", c'est-à-dire à un ensemble de conteneurs pour l'application et les services associés. Chaque branche peut produire une image d'application, qui peut ensuite être montée dans un nouveau conteneur (espace de noms) avec peu d'utilisation de ressources supplémentaires.
La partie délicate est le système de fichiers inscriptible pour chaque conteneur. Il est géré par un processus de copie sur écriture au niveau du volume, conceptuellement très similaire à la méthode de copie sur écriture de PHP pour gérer les variables en mémoire. Cela permet aux données d'être répliquées dans un nouveau conteneur (mount namespace) en un temps pratiquement constant, en bifurquant les données au fur et à mesure qu'elles sont modifiées. Ce processus est géré indépendamment des espaces de noms Linux, nous ne nous y attarderons donc pas ici.
Il faut également garder à l'esprit que le noyau Linux est très, très doué pour éviter de charger dans la mémoire des données dont il n'a pas besoin. S'il y a 100 conteneurs dans 100 ensembles d'espaces de noms, exécutant 100 copies de nginx à partir de la même image de système de fichiers en lecture seule... Linux ne chargera pas 100 copies du binaire nginx en mémoire. Il chargera une seule fois en mémoire les parties du binaire dont il a besoin, puis, lorsqu'il mentira à chaque processus au sujet de son espace mémoire virtuel, il lui mentira également au sujet de sa propre copie du code de l'application. Cela signifie que 100 copies de nginx ne prennent pas 100 fois plus de mémoire ; elles prennent peut-être 25 % de mémoire en plus pour les données de chaque instance. (La quantité réelle variera largement en fonction de la quantité de données d'exécution réelles que l'application stocke dans des variables).
Le résultat net est qu'une seule VM puissante, exécutant un seul noyau Linux, peut faire fonctionner des dizaines de conteneurs d'application définis par l'utilisateur, des dizaines d'instances MariaDB, une douzaine d'instances Apache Solr, une poignée d'instances RabbitMQ et un ou deux index Redis, le tout en même temps ; toutes ces applications penseront, si elles interrogent le système d'exploitation, qu'elles sont la seule application en cours d'exécution sur leur ordinateur ; et toutes ne pourront accéder qu'à un ensemble sélectionné et inscrit sur une liste blanche d'autres "systèmes" (conteneurs), selon des modalités inscrites sur une liste blanche.
Tout cela parce que Linux a appris à mentir.
Contraste avec Docker
Docker, en revanche, est conçu pour exécuter un processus unique dans chaque conteneur (ensemble d'espaces de noms). Ce processus unique peut être quelque chose comme PHP-FPM, Nginx, ou MariaDB, ou un processus de courte durée comme une commande Composer en cours d'exécution. Docker n'utilise pas de processus init, donc bien qu'il soit possible de forcer manuellement plusieurs processus dans un seul conteneur, ce n'est pas vraiment le cas d'utilisation prévu, et ces processus ne démarreront pas et ne s'arrêteront pas de manière gracieuse en cas de problème.
Docker renonce également à la configuration du système de fichiers à montages multiples en faveur d'une approche en couches. Une autre astuce du noyau Linux consiste à permettre à plusieurs images de systèmes de fichiers de se "masquer" mutuellement. Essentiellement, plusieurs systèmes de fichiers peuvent être montés sur /, et les fichiers des systèmes de fichiers ultérieurs seront utilisés à la place de ceux des systèmes de fichiers antérieurs. Cela permet aux outils de base communs d'un système Debian ou Red Hat fonctionnel, par exemple, de ne vivre qu'une seule fois sur le disque et d'être ensuite "masqués" par une installation de MariaDB ou de PHP-FPM au démarrage du conteneur. Voir la figure 10 pour l'illustration.

Pour le principal cas d'utilisation de Docker, à savoir l'exécution d'applications locales dans un conteneur, c'est tout à fait possible. Il est en fait mieux adapté aux tâches ponctuelles, telles que l'intégration d'un outil de ligne de commande comme Composer ou NPM dans un conteneur, que le modèle d'Upsun. Le modèle d'Upsun, en revanche, donne une impression plus proche d'une VM et permet à plusieurs processus liés (tels que Nginx et PHP-FPM) de fonctionner ensemble dans le même conteneur pour plus de simplicité, ce que Docker ne fait pas. Aucun des deux modèles n'est intrinsèquement "meilleur" ou "pire", ils sont simplement adaptés à différents cas d'utilisation.
La plus grande différence réside dans le fait que Docker est intrinsèquement un système à conteneur unique ; la gestion de plusieurs conteneurs de concert est laissée à des outils distincts tels que Kubernetes, Docker Compose, Docker Swarm, et ainsi de suite. Dans le cas d'Upsun, l'hypothèse est que les conteneurs seront toujours déployés en tant que groupe, même s'il s'agit d'un groupe de 1. (Rappelons la loi de Garfield, "Un est un cas particulier de plusieurs").
Il existe également d'autres systèmes de conteneurs dans la nature. FlatPak de Red Hat ou Snaps d'Ubuntu sont tous deux des systèmes basés sur des conteneurs et optimisés pour la livraison d'applications de bureau emballées dans des conteneurs. Nous n'entrerons pas dans les détails de leur fonctionnement, car cet article est déjà assez long, mais sachez qu'ils existent aussi et qu'ils répondent mieux à leurs propres besoins que la plateforme d'hébergement d'Upsun ou Docker.
L'avantage des conteneurs, tels que Linux les met en œuvre, est qu'ils peuvent être utilisés d'une grande variété de façons différentes en fonction du cas d'utilisation. Comme pour la plupart des choses dans la technologie, ils ne sont pas bons ou mauvais, ils s'adaptent simplement mieux ou moins bien à une situation donnée.
Conclusion
Bien qu'ils soient cool et qu'ils permettent une multitude de nouvelles fonctionnalités (sans jeu de mots), les conteneurs ne sont pas magiques. Ils n'ont rien à voir avec les conteneurs d'expédition, malgré le battage publicitaire. Docker n'est pas non plus le premier, le dernier ou le seul système de conteneurs sur le marché. Il existe une grande variété d'applications de coordination de conteneurs, toutes avec leurs propres avantages et inconvénients, comme sur n'importe quel autre marché de logiciels. En fin de compte, toutes ces applications sont simplement des moyens organisés et systématiques de répondre à vos programmes de manière nouvelle et créative.
Chez Upsun, nous avons adopté ces "beaux mensonges" pour créer quelque chose de puissant : une plateforme où les développeurs peuvent se concentrer sur la création d'applications étonnantes pendant que nous nous occupons de l'orchestration complexe des espaces de noms, des conteneurs et de l'infrastructure. Que vous exécutiez un simple CMS ou une architecture microservices complexe, notre implémentation de conteneurs garantit que vos applications obtiennent exactement les ressources et l'isolation dont elles ont besoin sans que vous ayez à devenir un expert en interne du noyau Linux.
Bienvenue dans le futur. S'il vous plaît, gardez vos mensonges pour vous.
Prêt à voir ces mensonges fonctionner en votre faveur ? Essayez la magie des conteneurs d'Upsun avec un essai gratuit et découvrez la puissance d'une tromperie parfaitement orchestrée.
Votre meilleur travail
est à l'horizon
ComparerAlternative à VercelAlternative à AmazeeAlternative à HerokuAlternative à PantheonAlternative à l'hébergement géréAlternative à Fly.ioAlternative à RenderAlternative à AWSAlternative à AcquiaAlternative à DigitalOcean
ProduitAperçuSupport and servicesPreview environmentsMulti-cloud and edgeGit-driven automationObservability and profilingSecurity and complianceScaling and performanceBackups and data recoveryTeam and access managementCLI, console, and APIIntegrations and webhooksPricingPricing calculator
Cas d'utilisationSolutions backendApplication modernisationCommerce électroniqueHébergement CMSGestion multi sitesExtensions SaaS
Join our monthly newsletter
Compliant and validated