


Fonctionnalités


Suivre l'évolution des meilleures pratiques en matière de déploiement d'applications web
CI/CDGitconteneursdéploiementautomatisation
09 juillet 2020


Cette page a été rédigée en anglais par nos experts, puis traduite par une IA pour vous y donner accès rapidement! Pour la version originale, c’est par ici.
On parle souvent des "meilleures pratiques" dans le monde de la tech, mais on reconnaît rarement qu'elles peuvent changer et qu'elles changent au fil du temps. Toutes les "meilleures pratiques" ne sont rien d'autre qu'une distillation des défis d'une situation donnée en un ensemble de compromis généralement optimaux.
Cependant, au fur et à mesure que la technologie progresse, ces compromis changent. Ce qui était autrefois difficile et coûteux peut devenir plus facile et moins cher. (Et, parfois, ce qui était facile et bon marché peut devenir difficile et coûteux.) Cela signifie que les "meilleures pratiques" doivent évoluer avec elles. Ce qui était autrefois à la pointe du progrès est aujourd'hui une stratégie perdante.
Le modèle de déploiement d'applications web à 3 niveaux
Les flux de développement sont un exemple de cette évolution. Autrefois, les environnements de serveurs étaient coûteux et longs à construire et à entretenir. Ils nécessitaient du matériel physique, l'installation manuelle de logiciels et une maintenance manuelle pour les maintenir à jour.
Il fut un temps où cela justifiait de n'avoir qu'un serveur de production, rien d'autre. Cela a conduit à un modèle de développement commun : "mon bureau et la production" (ou "juste la production" si vous n'aviez pas de chance). Tout ce qui était plus robuste était trop cher et exigeait trop de travail pour toutes les installations, à l'exception des plus grandes.
Au fil du temps, le secteur s'est rendu compte qu'il s'agissait d'un mauvais compromis. Le modèle "Hack it on production" a été remplacé par le fameux modèle à trois niveaux (ou parfois à quatre niveaux si vous aviez le budget) :

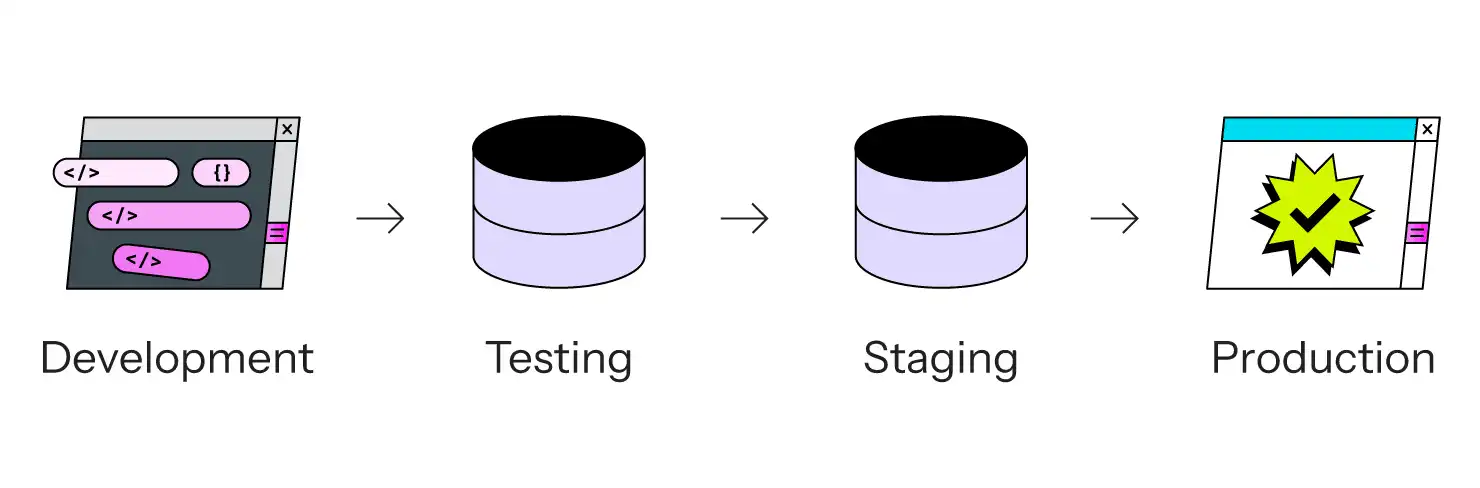
- Le développement est l'endroit où le code est édité, généralement sur l'ordinateur portable local de chaque développeur.
- Le test est la première fois que le code de plusieurs développeurs se voit. C'est là que se déroulent les tests d'intégration, les tests d'acceptation par les utilisateurs et les autres activités d'assurance qualité. Parfois, cette étape est fusionnée avec la phase de mise à l'essai.
- La pré-production (Staging) est une zone d'attente avant la sortie de la version, qui permet de tester le code dans un environnement similaire à celui de la production.
- La production est, en fait, la production. Le site en direct.
L'avantage du modèle à 3 ou 4 niveaux est que le code a la possibilité d'être revu et testé par plusieurs personnes avant d'atteindre le site réel. (Comme le dit la plaisanterie, tout le monde a un serveur de test ; certains ont la chance d'avoir également un serveur de production séparé). C'est un pas en avant par rapport au piratage sur le site de production, c'est certain. Cela signifie également qu'il existe une étape distincte où certaines activités se déroulent : l'écriture du code se fait dans le département de développement ; la fusion du code se fait dans le département de test ; l'assurance qualité se fait dans le département de test ; l'examen final se fait dans le département de mise en scène, parfois avec un instantané des données de production ; et la production est l'endroit où les clients consultent réellement le site.
Le piège du modèle à 3 niveaux dans le déploiement d'applications web dans le monde réel
Le modèle à trois niveaux présente toutefois un certain nombre d'inconvénients. En particulier, il est très facile pour le développement local de prendre du retard par rapport à l'instance de test, ce qui fait que le test devient une masse de conflits de fusion. Plus vous attendez pour fusionner du code vers Testing, plus c'est difficile à faire. D'un autre côté, plus vous fusionnez fréquemment vers Testing, plus il est difficile de tester. La chose testée peut changer à chaque fois qu'un nouveau code est fusionné, ce qui conduit à une cible mouvante. Cela devient un défi encore plus grand lorsque vous avez plusieurs testeurs, car leurs efforts peuvent se heurter les uns aux autres. (C'est particulièrement vrai pour les tests avec les utilisateurs finaux ou les tests qui impliquent une modification des données).
L'autre inconvénient majeur de ce modèle est qu'il est linéaire. Pour que le code soit mis en production, il doit passer par les phases de test et/ou de mise à l'essai, qui ne sont qu'une (chacune). Cela peut convenir lorsque tout fonctionne, mais bien sûr, il y a toujours quelque chose qui se casse. Si vous découvrez un bug en production, il est mal vu de contourner le pipeline de test/stage et de déployer directement en production sans vérifier que la correction ne casse rien d'autre. Si vous passez par les phases de test/stage appropriées, votre simple correction d'urgence pourrait être bloquée par une autre fonctionnalité qui n'est pas encore prête et qui a déjà été fusionnée dans Testing ou Staging mais qui n'a pas encore été approuvée pour la mise en production.
C'est ainsi qu'est née l'idée d'un "correctif", qui, en langage de développeur, signifie "le processus entrave la correction du bug, je vais donc abandonner le processus". C'est parfois la bonne solution, mais cela montre aussi où le processus est défectueux.
Les données constituent un autre problème. Tandis que le code remonte le long du pipeline, il faut pouvoir tester le nouveau code avec les données de production actuelles. En fonction de la configuration, le processus de transfert d'un instantané des données de production vers Staging peut s'avérer difficile et chronophage. Si c'est le cas, ce sera encore pire de le répliquer vers Testing ou Development. Cela signifie que vous ne découvrirez peut-être pas comment le nouveau code interagit avec les données réelles avant la dernière minute, ce qui est généralement plusieurs semaines plus tard que vous ne le souhaiteriez.
CI/CD pour un processus plus rapide
La solution standard aux défis posés par un modèle à trois niveaux consiste à accélérer les changements. C'est ainsi que sont nés deux concepts jumeaux :
- L'intégration continue (CI), qui se traduit grosso modo par " intégrer le code dans les tests aussi vite que possible".
- Le déploiement continu (CD), qui se traduit grosso modo par "faire passer le code dans le pipeline et le déployer en production aussi vite que possible".
Le modèle CI/CD, tel qu'il est connu aujourd'hui, tente de relever les défis du modèle à trois niveaux grâce à l'automatisation, afin de faire passer le code dans le processus plus rapidement. Cela peut impliquer un certain nombre d'options différentes.
- L'exécution automatique de tests au niveau du code sur le nouveau code avant même qu'il ne soit déployé quelque part.
- L'exécution automatique de certains tests QA ou UAT dans le cadre des tests, réduisant ainsi la nécessité de faire appel à des humains lents et surchargés.
- Faire avancer automatiquement le code dans le pipeline lorsque certains critères sont remplis (comme la réussite des tests).
Cela permet de réduire le temps nécessaire pour faire avancer le code dans le pipeline, mais ne résout pas le problème principal : le modèle à trois niveaux est linéaire, mais le développement du code ne l'est pas. Il introduit également ses propres défis, à savoir plus de pièces mobiles à mettre en place, à gérer et à faire fonctionner. Il existe même des postes spécifiques pour les ingénieurs CI/CD, les "ingénieurs DevOps" ou d'autres titres qui signifient essentiellement "prendre soin et nourrir toute cette automatisation". Cela ne semble pas très automatique, et cela peut être coûteux.
Git et les conteneurs : des changements dans l'automatisation CI/CD
Deux avancées technologiques ont rendu l'automatisation CI/CD tolérable.
La première est l'omniprésence de Git en tant que système de contrôle de version. Git excelle dans de nombreux domaines, mais en particulier, la capacité extrêmement bon marché et rapide de brancher le code et de fusionner les branches améliore considérablement la partie "intégration" de l'équation. Les développeurs les plus récents ne se souviennent peut-être pas de l'époque de Subversion ou de CVS, mais avant les systèmes de contrôle de version distribués modernes, "créer une branche" était une tâche difficile, longue et donc rare. Git a résolu ce problème facilement, et une API simple l'a rendu bien adapté aux scripts et à l'automatisation.
Le second a été l'avènement de la virtualisation, d'abord par le biais des machines virtuelles, puis, mieux encore, par celui des conteneurs, qui permettent d'abstraire l'idée d'un "système" informatique du matériel physique. Cela signifiait que la création de nouveaux environnements ne nécessitait pas la construction de nouveau matériel, mais seulement un codage suffisant.
Pendant longtemps, les conteneurs ont été utilisés principalement pour des environnements de test bon marché. Des services de CI sont apparus qui utilisaient des conteneurs pour construire des mini-systèmes temporaires dans lesquels étaient exécutés des tests au niveau du code, ou parfois des tests UAT complets. Combiné à l'automatisation basée sur Git, cela a rendu l'étape "Test" du pipeline traditionnel beaucoup plus simple et plus productive. Dans le cas idéal, chaque branche Git, lors de la poussée, est soumise à tous les tests automatisés disponibles. S'ils échouent, le développeur le sait immédiatement. S'ils réussissent, les réviseurs humains peuvent ignorer les parties automatisables et se contenter d'évaluer les aspects qualitatifs du nouveau code.
Ces services n'ont toutefois pas résolu le principal problème du modèle à trois niveaux : sa nature linéaire. Ils n'ont fait que l'accélérer.
En outre, dans la plupart des cas, le système de production n'était toujours pas synchronisé avec le développement ou les tests, et parfois pas non plus avec la mise en phase. Plus les phases de test et de mise à l'essai sont proches de la production, plus les bugs peuvent être détectés rapidement et moins il y a de variables susceptibles de mal tourner. Les différentes versions du système d'exploitation, les dépendances, les profils de ressources, les bibliothèques complémentaires, les langages d'exécution, etc. ont tous leurs propres bugs subtils qui se cachent dans chaque combinaison. Si la combinaison en production n'est pas la même qu'en phase de test et de mise en scène, ces étapes de validation ne sont que des suppositions bien informées.
L'ère du cloud computing
Ce que la virtualisation, et les conteneurs en particulier, permet vraiment, c'est la capacité de ne pas penser au matériel du tout. Un "système" informatique n'est plus un objet artisanal que l'on entretient et que l'on doit gérer. Il s'agit d'une création logique, éphémère et jetable dans un logiciel.
La mise à niveau n'implique plus de modifier le logiciel en place, mais de construire un tout nouveau "système" (conteneur) et de remplacer l'ancien, un processus qu'un bon système d'orchestration rend totalement transparent.
Idéalement, le système de fichiers de chaque conteneur est en lecture seule, avec éventuellement quelques exceptions en liste blanche pour les données des utilisateurs. Cela permet d'éviter à la fois les personnalisations accidentelles et les attaques de sécurité malveillantes. Plutôt que de modifier le système de fichiers pour effectuer un changement, vous construisez une nouvelle image du système de fichiers, vous jetez l'ancienne et vous activez la nouvelle.
La possibilité d'envisager les systèmes d'une manière strictement logicielle est aujourd'hui appelée "cloud computing", un clin d'œil au terme marketing "The Cloud" (le nuage) pour désigner les solutions hébergées en général. Bien qu'ils ne soient pas identiques, ils vont de pair. Et comme les environnements de cloud computing sont différents des anciens systèmes basés sur le matériel, ils ont un nouvel ensemble différent de meilleures pratiques.
Conteneurisation : la meilleure pratique du début à la fin
À chaque étape, les "meilleures pratiques" conventionnelles ont changé. Avec l'avènement de la conteneurisation généralisée, les meilleures pratiques actuelles reposent sur la conteneurisation de l'ensemble du processus, du début à la fin. Cela a pour effet de faire exploser le modèle traditionnel à trois niveaux.
Aujourd'hui, la stratégie de déploiement web basée sur les meilleures pratiques se présente comme suit :

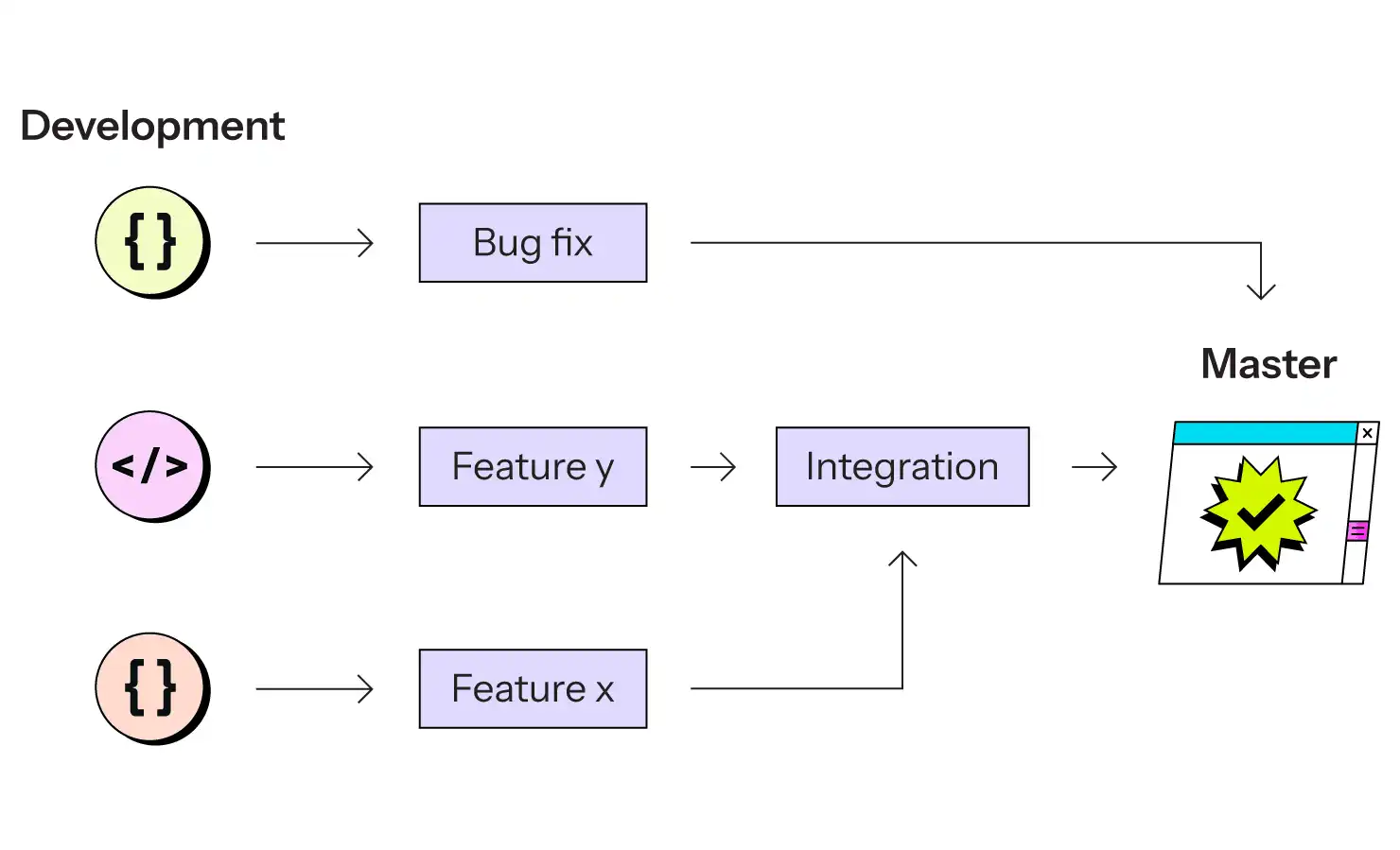
Chaque étape, du développement à la production, est construite avec des conteneurs et gérée par Git. Chaque branche correspond à un environnement basé sur des conteneurs.
Si le développement se fait toujours sur l'ordinateur local du développeur, qui peut ou non utiliser les mêmes images de conteneurs, toutes les autres étapes impliquent des conteneurs identiques au niveau du bit. La version de PHP, de Node.js ou de Java utilisée est garantie identique, jusqu'à la version du correctif et aux paramètres de compilation. La version de votre base de données SQL est identique. La version de votre serveur de recherche est identique. Les dépendances tierces de votre propre code sont identiques.
Et si elles ne le sont pas, c'est parce que vous les avez délibérément modifiées. La configuration de l'environnement est elle-même un code stocké dans Git, ce qui permet de tester les modifications de l'infrastructure (mise à niveau d'une dépendance, d'une base de données ou du moteur d'exécution de votre langage) de la même manière que les modifications du code.
Vous ne déployez pas de nouvelles versions de votre code ; vous déployez de nouvelles versions de l'ensemble de votre système, dont votre code n'est qu'une partie.
Toutes les nouvelles mises à jour d'une branche Git peuvent et doivent entraîner la reconstruction de l'environnement correspondant, à partir de zéro, de sorte qu'il n'y a pas de question de "mise à jour en place" à prendre en compte.
Évolutivité du déploiement d'applications avec Git-et-Cloud
Ce modèle Git-et-Cloud présente un certain nombre d'avantages par rapport au modèle à trois niveaux.
- Il n'est pas linéaire. Une modification ne peut pas en bloquer une autre, car toutes les modifications ont leur propre pipeline indépendant. Une version de fonctionnalité, une correction de bug critique, une mise à jour de routine, toutes peuvent se dérouler en parallèle et être déployées indépendamment les unes des autres, dès qu'elles sont terminées.
- Le nombre de lignes de travail parallèles n'est limité que par le nombre de conteneurs que vous pouvez créer. En supposant que vous utilisiez un environnement cloud virtualisé, cela signifie que le coût incrémentiel d'un plus grand nombre d'environnements est faible et qu'il évolue de façon approximativement linéaire.
- Comme chaque environnement est jetable et construit à la volée à partir d'instructions répétables, vos environnements de préversion peuvent être réellement identiques à ceux de la production.
- L'"intégration" n'est plus qu'une question d'utilisation des branches Git. Lorsqu'une nouvelle modification est fusionnée en production, n'importe quelle autre branche peut facilement fusionner les mises à jour de la production, parce que Git rend cela facile. S'il y a un conflit, il sera immédiatement détecté.
- Vous pouvez également disposer d'une branche Git pour les tests de pré-version vers laquelle vous fusionnez d'autres branches afin d'y effectuer des tests d'intégration. En d'autres termes, ce modèle vous permet de simuler l'ancien modèle à trois niveaux si vous le souhaitez. Ce n'est généralement pas nécessaire, mais c'est possible si cela a du sens. Les flux de travail possibles ne sont limités que par les compétences de votre équipe avec Git.
- Comme le système de fichiers est en lecture seule, vous avez la garantie qu'aucune modification ne peut être apportée sans passer par Git et une couche de sécurité supplémentaire pour vous protéger contre les intrus.
Il existe de nombreux outils possibles pour construire un flux de travail d'hébergement et de déploiement Git et Cloud pour une application moderne. Certains sont auto-hébergés tandis que d'autres sont des services hébergés. Dans la plupart des cas, un service hébergé, tel qu'Upsun.com, permet de réaliser de meilleures économies à long terme. L'inconvénient majeur du modèle Git-and-Cloud est la complexité de l'outil sous-jacent qui le permet, et cette complexité est mieux gérée par des équipes dédiées qui peuvent gérer cet outil en masse.
De nouvelles normes de test avec Upsun.com
La cerise sur le gâteau, offerte par seulement quelques fournisseurs tels qu'Upsun.com, est la réplication des données. Pour qu'un modèle Git et Cloud brille vraiment, il faut non seulement des environnements bon marché et un flux de code simple, mais aussi un flux de données bon marché. Plus les données de vos environnements de test sont proches de la production, plus vos efforts de validation et de test sont précis. Upsun.com vous permet, d'un simple clic, d'effectuer un clonage copie sur écriture de données arbitraires d'un environnement à l'autre - pas de vidage et de restauration SQL lents qui pourraient prendre des dizaines de minutes ou des heures, bloquant potentiellement l'instance de production au cours du processus. Cela prend un temps à peu près constant, de l'ordre d'une à trois minutes en moyenne.
Cela permet de tester une nouvelle modification, qu'il s'agisse d'une petite correction de bug, d'une nouvelle fonctionnalité importante ou d'une mise à niveau de dépendance avec des données et une configuration de production pendant quelques minutes ou quelques jours. Il s'agit de l'expérience la plus précise possible de "mise à l'essai comme en production", tout en évitant le concept de serveur de "mise à l'essai".
C'est le processus de déploiement web de pointe d'aujourd'hui.
Pérenniser le processus de déploiement d'applications web
Au fur et à mesure que la technologie s'améliore, l'utilisation optimale de la technologie évolue également. Il y a 10 ou 15 ans, une architecture à 3 ou 4 niveaux était le processus standard de l'industrie et ce que la plupart des organisations auraient dû faire. C'était la "bonne méthode" à l'époque.
Les outils ont changé et les "meilleures pratiques" aussi. Aujourd'hui, avec la disponibilité généralisée de Git et des environnements de cloud computing, le déploiement continu n'a plus la même signification qu'à l'époque des processus de construction artisanaux. Cela signifie disposer d'un nombre arbitraire d'environnements parallèles, de flux de travail non linéaires et de conteneurs bon marché et jetables qui peuvent être construits à partir de zéro à la demande.
Quelle sera la meilleure pratique dans 10 ans ? Nous le découvrirons quand nous y serons.
Liens utiles
Votre meilleur travail
est à l'horizon
ComparerAlternative à VercelAlternative à AmazeeAlternative à HerokuAlternative à PantheonAlternative à l'hébergement géréAlternative à Fly.ioAlternative à RenderAlternative à AWSAlternative à AcquiaAlternative à DigitalOcean
ProduitAperçuSupport and servicesPreview environmentsMulti-cloud and edgeGit-driven automationObservability and profilingSecurity and complianceScaling and performanceBackups and data recoveryTeam and access managementCLI, console, and APIIntegrations and webhooksPricingPricing calculator
Cas d'utilisationSolutions backendApplication modernisationCommerce électroniqueHébergement CMSGestion multi sitesExtensions SaaS
Join our monthly newsletter
Compliant and validated