


Fonctionnalités


Surveillance et journalisation des applications : Le guide du développeur pour prendre le contrôle
observabilitéDevOpsperformanceautomatisation
18 août 2025
Cette page a été rédigée en anglais par nos experts, puis traduite par une IA pour vous y donner accès rapidement! Pour la version originale, c’est par ici.
Aucun développeur ne souhaite des pannes de serveur et des alertes de performance urgentes à 3 heures du matin, mais c'est exactement ce qui peut se produire sans une surveillance solide des applications. De mauvaises performances et des pannes ont un impact direct sur votre chiffre d'affaires.
Les recherches d'Akamai et de SOASTArévèlent les conséquences économiques brutales des problèmes de performances : une simple augmentation de 100 ms de la latence réduit les taux de conversion de 7 %, tandis que les temps d'arrêt prolongés peuvent entraîner une hémorragie de plusieurs milliers de dollars par heure. Ce lien direct entre les performances techniques et les résultats commerciaux est précisément la raison pour laquelle votre pile de surveillance doit évoluer au-delà du simple suivi pour devenir un système d'alerte précoce, qui détecte et résout les problèmes avant même qu'ils n'atteignent les écrans de vos utilisateurs.
La surveillance des performances des applications consiste à arrêter les problèmes avant qu'ils ne se produisent. Des objectifs de niveau de service (SLO) bien configurés transforment les catastrophes potentielles en corrections mineures.
"Le meilleur moment pour corriger un bogue est avant qu'il n'existe" - Andrew Hunt, co-auteur de The Pragmatic Programmer (Le programmeur pragmatique)
Dans ce guide, nous explorerons ces domaines clés :
- Les systèmes d'alerte précoce qui détectent les problèmes dès leur apparition
- Des alertes précises qui identifient les causes profondes
- Planification de la maintenance basée sur des données
- Des outils éprouvés qui s'adaptent à votre système
Pourquoi surveiller ? Le coût réel des temps d'arrêt
Il n'y a rien de plus douloureux que de se réveiller à 3 heures du matin et de voir son chiffre d'affaires chuter après une panne de système. Voici comment une surveillance intelligente permet d'arrêter les incendies avant qu'ils ne se déclarent :
- Voir la panne : les utilisateurs ne vous diront pas quand les choses ralentissent - ils vous enverront un message fantôme.
- Réparez plus rapidement : Des informations précises sur le système peuvent réduire considérablement votre temps de résolution.
- Évoluez intelligemment : Surveillez les mesures de capacité pour adapter les ressources en fonction de la demande réelle.
- Des décisions fondées sur des données : Mesurez enfin l'impact réel de vos choix techniques.
Sécurité proactive : N'attendez pas qu'une brèche se produise. Détectez et bloquez les menaces en temps réel grâce à une surveillance continue.


Les trois éléments fondamentaux de la surveillance des applications
La surveillance des applications permet à vos systèmes de rester honnêtes. Trois éléments travaillent ensemble pour vous dire ce qui se passe sous le capot.
1. Les métriques : Suivi des principaux indicateurs de santé
- Surveillez l'état de santé de votre système en temps réel - détectez les petits problèmes avant qu'ils ne se transforment en véritables maux de tête.
- Surveillez les indicateurs clés tels que l'utilisation de l'unité centrale, les temps de réponse et les taux d'erreur.
- Définissez des alertes intelligentes qui vous avertissent lorsque les mesures sortent des limites acceptables.
2. Journaux : La trace écrite numérique de votre système
- Enregistrez de manière détaillée tous les événements importants de votre application.
- Enregistrez tout ce qui se passe dans votre système. Chaque erreur, chaque avertissement et chaque action de l'utilisateur. C'est votre trace écrite numérique lorsque les choses tournent mal.
- Déboguez les problèmes grâce à des données complètes de contexte et d'horodatage.
3. Traces : La carte du parcours de votre demande
- Suivez les requêtes pendant qu'elles se déplacent dans vos services distribués
- Trouvez les goulets d'étranglement en matière de performances et améliorez les connexions aux services.
- Voyez comment les différentes parties de votre application fonctionnent ensemble, des appels d'API aux requêtes de base de données et à la communication des services.
Ces trois éléments constituent votre base de surveillance, vous aidant à détecter rapidement les problèmes et à assurer le bon fonctionnement de votre application. Vous savez ce qui est génial ? Les plateformes modernes de cloud computing ont rendu la mise en place de ces outils de surveillance très facile - pas besoin d'être un génie. Nous verrons comment dans la section suivante.
La surveillance à l'ère de l'informatique dématérialisée
La surveillance de l'informatique dématérialisée vous permet d'établir un lien direct entre l'état du système et l'impact sur l'activité de l'entreprise. La surveillance en temps réel vous permet de détecter et de résoudre les petits problèmes avant qu'ils ne se transforment en gros problèmes qui affectent vos utilisateurs. Vous pouvez optimiser votre système sur la base de mesures de performances réelles.
Les plateformes de conteneurs modernes comme Kubernetes ont changé la façon dont nous regardons les données et offrent des informations granulaires sur chaque composant de nos applications. Vous obtenez des informations granulaires tout en conservant le contexte complet de votre système.
Architecture multi-runtime : Optimisation de la surveillance dans l'ensemble de votre pile
Les applications modernes sont polyvalentes et adaptables en ce sens qu'elles utilisent différents outils spécialisés (appelés runtimes) pour accomplir efficacement diverses tâches. Rust effectue les travaux lourds, Node pilote les API web et Python traite les données. Chaque moteur d'exécution a besoin de sa propre approche de surveillance pour détecter les problèmes à un stade précoce - c'est un peu comme si vous aviez des médecins spécialisés pour les différentes parties de votre système.
| Temps d'exécution | Requêtes/sec | Modèle de mémoire | Objectif de surveillance | Cas d'utilisation courant |
|---|---|---|---|---|
| Rouille | 690 | Allocation statique | Métriques des threads, sécurité de la mémoire | Services de haute performance |
| Node.js | 100 | Axé sur les événements | Boucle d'événements, opérations asynchrones | Services API, applications en temps réel |
| Python | 50 | Comptage de références | Contrainte GIL, utilisation de la mémoire | Traitement des données, services ML |
Stratégies de surveillance spécifiques à l'exécution :
Cette stratégie permet de maintenir des performances optimales sur l'ensemble de l'application tout en réduisant le temps moyen de résolution des problèmes.
- Surveillance de Node.js
- Suivi du décalage des boucles d'événements (seuil d'alerte : >100 ms)
- Surveiller les schémas d'utilisation du tas avec des outils tels que clinic.js
- Exemple de configuration :
{ "eventLoopLag" : {"warning" : 100, "critical" : 500 }, "heapUsage" : { "warning" : "70%", "critical" : "85%" } }
- Surveillance Python
- Surveiller la contention GIL avec py-spy
- Traquer les fuites de mémoire avec memory_profiler
- Exemple de configuration :
{ "gilContentionRate" : {"warning" : "25%", "critical" : "40%" }, "memoryGrowth" : { "warning" : "10MB/min", "critical" : "50MB/min" } }
- Surveillance de la rouille
- Surveiller l'utilisation du pool de threads pour maintenir la réactivité du service
- Utilisez metrics-rs pour suivre les ressources du système.
- Exemple de configuration :
{ "threadPoolUtilization" : {"warning" : "85%", "critical" : "95%" }, "requestLatency" : { "warning" : "10ms", "critical" : "50ms" } }
Upsun rend le travail avec plusieurs runtimes moins complexe en vous donnant une visibilité sur l'ensemble de votre pile depuis un seul endroit. Vous pouvez définir et gérer les dépendances entre les services, ce qui vous aide à identifier les goulots d'étranglement potentiels. Notre surveillance unifiée vous permet de suivre les performances de toutes les technologies.
Des chiffres qui orientent les décisions
Voici les principales mesures à surveiller, avec leurs seuils et ce qu'il faut faire en cas de problème :
1. Mesures de performance (vitesse et réactivité)
test de l'espace titre
| Mesure | Normal | Avertissement | Critique |
|---|---|---|---|
| Temps de réponse | < 200 ms | > 500 ms | > 1000ms |
| Taux d'erreur | < 0.1% | > 1% | > 5% |
Contrôle du temps de réponse : Suivez la vitesse de réponse des requêtes - c'est le pouls de l'expérience utilisateur.
- Lorsque le seuil d'alerte est atteint : Établissez le profil des requêtes lentes (à l'aide d'outils de profilage de base de données), optimisez les chemins de code et vérifiez la latence du réseau (à l'aide de traceroute, mtr).
- Lorsque le seuil critique est atteint : Déployez des diagnostics APM. Tracez les goulets d'étranglement. Vérifiez les délais d'attente. Surveillez les ressources.
[2025-02-13 12:15:23] [WARN] Requête lente détectée - Endpoint : /payment - Durée : 650ms - Requête : SELECT * FROM orders WHERE user_id = ?
Surveillance du taux d'erreur : Suivez les requêtes qui échouent pour assurer le bon fonctionnement de votre service.
- Lorsque le seuil d'alerte est atteint : Analysez les modèles d'erreur dans votre pile (à l'aide d'outils de suivi des erreurs).
- Lorsque le seuil critique est atteint : Vérifiez les déploiements récents et les changements d'infrastructure.
[2025-02-13 12:30:00] [ERROR] POST /api/users - 500 Internal Server Error - Reason : La connexion à la base de données a échoué
2. Données vitales du système
| Métrique | Normal | Avertissement | Critique |
|---|---|---|---|
| Utilisation du CPU | < 70% | > 70% (5+ min) | > 85% (2+ min) |
| Utilisation de la mémoire | < 75% | > 85% | > 95% |
Surveillance de l'unité centrale : détectez rapidement les goulets d'étranglement en matière de performances et corrigez-les avant que vos utilisateurs ne s'en aperçoivent.
- Lorsque le seuil d'alerte est atteint : Établissez le profil des processus à forte intensité de CPU (à l'aide de top, htop), optimisez les algorithmes.
- Lorsque le seuil critique est atteint : Augmentez la capacité de calcul, optimisez les chemins d'exécution critiques.
[2025-02-13 14:20:33] [WARN] Utilisation élevée du CPU - Service : API - Utilisation : 82%
Surveillance de la mémoire : le suivi de l'utilisation de la mémoire permet de détecter les fuites de mémoire avant qu'elles n'endommagent votre application. Pas de plantage, pas de surprise.
- Lorsque le seuil d'alerte est atteint : Exécutez des profileurs de mémoire pour vérifier les vidages de tas et le ramassage des ordures.
- Lorsque le seuil critique est atteint : traquez les fuites de mémoire et redémarrez si nécessaire.
[2025-02-13 14:45:10] [WARN] Pression mémoire - Service : BackgroundJobProcessor - Utilisation du tas : 90%
Surveillance des E/S disque : Surveillez à la fois la vitesse à laquelle votre système de stockage peut traiter les opérations (IOPS) et la quantité de données qu'il peut déplacer en une seule fois (débit) afin d'assurer le bon fonctionnement de votre système.
- Définissez des lignes de base pour vos charges de travail spécifiques (à l'aide de iostat, iotop).
- Alerte en cas de changements significatifs
- Surveillez de près les opérations sur les bases de données et les fichiers et réglez-les lorsque les performances commencent à faiblir.
3. Objectifs de niveau de service (SLO)
Suivi de la disponibilité : Définissez des objectifs de niveau de service mesurables qui quantifient les performances de votre service. Suivez les temps de latence, les taux d'erreur et le temps de disponibilité.
- Objectif : 99,95 % de temps de fonctionnement : Viser un temps de fonctionnement de 99,95 %. Suivre le budget d'erreur (la quantité de temps d'arrêt ou d'erreurs autorisée avant la rupture des accords de niveau de service).
- En cas de violation : Déclencher une mise à l'échelle automatisée lorsque le budget d'erreur atteint 90 % afin de gérer la capacité de manière proactive.
[2025-02-13 15:00:00] [LOG] Violation de SLO détectée - Budget d'erreur : 92% - Région : US-East - Statut : Initialisation de l'analyse de la capacité
Objectifs de performance : Définir des objectifs de temps de réponse correspondant aux attentes des utilisateurs et continuer à les mesurer.
- Objectif : Maintenir le temps de latence p99 (99e percentile du temps de réponse) en dessous de 500 ms pour garantir à la plupart des utilisateurs une expérience rapide et fluide.
- Sur la brèche : Augmenter les ressources et optimiser les chemins de code pour rétablir les niveaux de service.
4. Des mesures qui comptent pour les utilisateurs réels
- Temps de chargement des pages :
- Normal : < 2s
- Avertissement : > 3s
- Critique : > 5s (les utilisateurs quittent le site)
- Mesures à prendre :
- Établir le profil des performances du frontend (à l'aide de Lighthouse, WebPageTest)
- Optimiser les actifs et les appels d'API
- Utiliser des outils de test du réseau pour identifier et résoudre les goulots d'étranglement des performances.
[2025-02-13 16:10:22] [WARN] Chargement lent de la page - URL : /produits - Temps de chargement moyen : 4.2s
- Achèvement du flux d'utilisateurs : Suivre les parcours utilisateurs réussis.
- Normal : > 95
- Avertissement : < 90%
- Critique : < 85%
- Mesures à prendre :
- Analyse de l'entonnoir
- Analyser les journaux d'erreurs
- Examiner les données de session pour détecter les points d'abandon
[2025-02-13 16:30:45] [WARN] Pic d'abandon de panier - Parcours de l'utilisateur : Checkout - Taux d'achèvement : 88%
Suivez ces mesures axées sur l'utilisateur de manière cohérente et agissez rapidement lorsque des signes d'alerte apparaissent ; vous conserverez une prestation de service solide et éviterez la frustration de l'utilisateur. Lorsque vous combinez ces informations avec votre système de surveillance et de journalisation, vous obtenez une image d'observabilité pour l'excellence technique et la réussite commerciale. Sur cette base, voyons comment protéger vos systèmes en temps réel grâce à une surveillance robuste de la sécurité.
5. Protéger vos systèmes en temps réel
La surveillance de la sécurité s'ajoute au suivi des performances pour protéger vos systèmes contre les menaces. Voici votre boîte à outils de sécurité pratique :
- Détection intelligente
- Bloquer les IP suspectes après 10 tentatives de connexion infructueuses par minute
- Alerte en cas de pic de trafic 3x supérieur à la normale dans les 5 minutes.
Analyse des événements de sécurité toutes les 30 secondes pour repérer les schémas d'attaque en temps réel - votre première défense contre les menaces émergentes.
| Type d'attaque | Méthode de détection | Réponse |
|---|---|---|
| Abus de compétences | Vitesse de connexion par IP | Limitation progressive du débit |
| Vol de données | Modèles de données inhabituels | Isolation du réseau |
- Défense active
- Limitation du débit qui s'adapte à vos schémas de trafic
- Blocage instantané des activités malveillantes
- Intégration des données sur les menaces en temps réel
- Manuel de réponse rapide
- Traitement normalisé des menaces avec MITRE ATT&CK
- Séquences de réponses automatisées
Objectifs de temps de réponse :
| Type de menace | Temps de réponse | Action requise |
|---|---|---|
| Force brute | < 5 min | Bloquer les IP, alerter la sécurité |
| Violation de données | < 15 min | Isoler les systèmes affectés |
| DDoS | < 10 min | Renforcer les défenses, filtrer le trafic |
| Zéro jour | < 30 min | Patch et mise à jour des systèmes |
6. Indicateurs de performance
Les mesures techniques de votre application ont un impact direct sur vos résultats. Voici comment traduire les données de performance en valeur commerciale :
| Mesure | Normal | Avertissement | Critique | Action |
|---|---|---|---|---|
| Succès de la transaction | ≥99% | 98-99% | <95% | Vérifier les systèmes de paiement, la santé de l'API |
| Perte de revenus | $0 | 1-5K$/hr | >10K$/hr | Activer la réponse aux incidents |
Matrice de réponse pour les problèmes de transaction :
- 98-99% : Surveiller de près
- Examiner les journaux du système
- Vérifier les déploiements récents
- 95-98% : Action immédiate
- Analyser la santé de la passerelle de paiement
- Examiner les modèles de trafic
- <95% : Réponse critique
- Activer l'équipe chargée de l'incident
- Exécuter les procédures de retour en arrière
À retenir : Suivez ces paramètres en temps réel et ajustez les seuils en fonction de vos habitudes. Une réponse rapide à la dégradation permet d'éviter un impact majeur sur les revenus.
Journaux :
Chaque événement, erreur et action de l'utilisateur est consigné dans les journaux, ce qui vous permet d'obtenir des informations complètes en cas de problème. Ils constituent votre première ligne de défense en cas de problèmes de production.
Pourquoi les journaux structurés sont-ils importants ?
- Alertes de sécurité : Détecter rapidement les schémas suspects
- Clarté du système : Voir comment les services interagissent en temps réel
- Détection précoce : Résoudre les problèmes avant que les utilisateurs ne les signalent
Ce que cela signifie pour vous :
- Recherches rapides : Recherchez les problèmes en utilisant l'identifiant de la demande, l'identifiant de l'utilisateur, le type d'erreur ou l'horodatage.
- Repérer les schémas : Identifiez les problèmes récurrents avant qu'ils ne deviennent des problèmes
- Automatiser les réponses : Mettez en place des alertes qui se déclenchent lorsque les choses nécessitent une attention particulière.
- Nettoyer les données : Analysez les journaux de manière cohérente dans l'ensemble de votre pile de données.
Pratiques de journalisation professionnelles
- Choisissez judicieusement vos niveaux de journalisation :
DEBUG: Détails réservés aux développeurs (ne pas toucher à la production)INFO: Événements normaux du systèmeWARN: Problèmes nécessitant une attention particulièreERROR: Défaillances récupérablesCRITIQUE: Tout laisser tomber et réparer maintenant
- Champs essentiels dans chaque journal :
request_id: Permet de relier les événements entre les servicestimestamp: UTC pour un suivi globaluser_id: Qui a déclenché l'événementservice_name: Où l'événement s'est produitlog_level: Niveau d'urgence
- Restez propre : Utiliser un format unique partout
- Stockez-le intelligemment : Centraliser dans ELK ou dans le cloud logging avec des plans de rétention adaptés à vos besoins
Exemple : journalisation structurée en Python
`import logging import json logger = logging.getLogger(name) def process_order(order_id, user_id, product_name, quantity) : logger.info("Processing order", extra={ "order_id" : order_id, "user_id" : user_id, "product_name" : product_name, "quantity" : quantity, "event_type" : "order_processing" # Ajout d'un contexte pour l'analyse }) try : # ... logique de traitement des commandes ... logger.info("Commande traitée avec succès", extra={ "order_id" : order_id, "status" : "success", "event_type" : "order_completion" }) except Exception as e : logger.error("Error processing order", extra={ "order_id" : order_id, "error_message" : str(e), "event_type" : "order_error" }, exc_info=True) # Inclure la trace de la pile pour les erreurs raise
Exemple d'utilisation
process_order("ORD-12345", "user-42", "Awesome Widget", 2)`
Exemple de sortie de journal (JSON) :
{"asctime" : "2025-02-13 18:00:00", "levelname" : "INFO", "name" : "__main__", "message" : "Traitement de la commande", "order_id" : "ORD-12345", "user_id" : "user-42", "product_name" : "Awesome Widget", "quantity" : 2, "event_type" : "order_processing"} {"asctime" : "2025-02-13 18:00:01", "levelname" : "INFO", "name" : "__main__", "message" : "Commande traitée avec succès", "order_id" : "ORD-12345", "status" : "success", "event_type" : "order_completion"}
Si vous avez besoin d'une journalisation structurée dans d'autres langages de programmation, voici quelques options solides :
- Winston for Node.js formate les journaux et les achemine vers plusieurs destinations
- Serilog pour .NET fournit une journalisation fortement typée avec de bonnes performances
- Logrus en Go fait passer la journalisation structurée à un niveau supérieur grâce à des champs et des crochets riches.
Chacune de ces bibliothèques offre un moyen cohérent de capturer ce que fait votre code lorsqu'il s'exécute.
Traçage distribué : connectez votre pile de bout en bout
Lorsque des requêtes circulent à travers de multiples services, vous avez besoin d'une vision claire de ce qui se passe et à quel endroit. OpenTelemetry simplifie cette tâche en reliant vos composants entre eux afin que vous puissiez trouver et corriger les problèmes rapidement.
from opentelemetry import trace from opentelemetry.trace import Status tracer = trace.get_tracer(__name__) @tracer.start_as_current_span("process_order") def process_order(order_id) : with tracer.start_span("validate_order") as span : # Ajoute le contexte métier span.set_attribute("order_id", order_id) if not is_valid(order_id) : span.set_status(Status.ERROR) return False return True
Les traces vous montrent exactement ce qui se passe lorsque les choses tournent mal dans votre système, ce qui vous aide à trouver et à résoudre les problèmes plus rapidement.
Choisir les bons outils de surveillance
Le choix des outils de surveillance détermine directement la qualité de la détection et de la résolution des problèmes. Voici un guide clair et pratique pour choisir des outils adaptés à votre pile.
1. Liste de contrôle pour le choix des outils
- Quel est votre niveau de confort technique ? Outils en ligne de commande ou interface plus simple
- Où tourne votre application ? Configuration en nuage ou hybride
- Que pouvez-vous dépenser ? De l'open source à l'entreprise
- Quels sont les besoins ? Suivi de base ou informations approfondies
2. Outils APM
Configuration rapide, visibilité totale
- Aucun problème d'installation
- Outils de surveillance prêts à l'emploi
- ✓ Commencez à suivre en quelques minutes
- Construit pour les charges de production
- ✗ Payez plus au fur et à mesure de votre croissance
- Difficile à personnaliser pour des besoins spécifiques
- Vous êtes lié à la façon de faire d'un seul fournisseur
3. La surveillance par les bricoleurs
Pour les passionnés de contrôle
- ✓ Construisez-le exactement comme vous le souhaitez
- ✓ Soutenu par la communauté open source
- ✓ Minimiser les coûts en limitant l'infrastructure
- ✓ Échanger et remplacer les outils sans friction
- Nécessite des connaissances techniques approfondies
- Vous possédez la pile de surveillance
- ✗ Faites-le évoluer vous-même
4. Surveillance native dans le nuage
Idéale lorsque vous êtes tout entier tourné vers un seul nuage
- Fonctionne avec votre plateforme
- ✓ Rapide à mettre en place
- Souvent inclus dans les coûts de la plateforme
- Un tableau de bord pour tout
- ✗ Lié à votre plateforme
- Options d'ajustement limitées
- Les fonctionnalités varient selon la plateforme
Comparaison rapide
| Fonctionnalité | SaaS APM | Open Source | Plate-forme native |
|---|---|---|---|
| Mise en place | Rapide (Datadog, Sentry) | Complexe (Prometheus + Grafana) | Intégrée (AWS CloudWatch) |
| Contrôle | Limité | Complet | Basé sur la plateforme |
| Échelle | Automatique | Manuelle | Lié à la plate-forme |
| Coût | Basé sur l'utilisation | Infrastructure + maintenance | Plate-forme incluse |
| Maintenance | Géré | Autogestion | Gestion par la plate-forme |
| Intégration | Connecteurs prédéfinis | Implémentation personnalisée | Outils natifs |
| Meilleur pour | Déploiement rapide | Flexibilité totale | Alignement de la plateforme |
Conseil : mélangez les outils en fonction de ce que vous surveillez. Utilisez SaaS APM pour les mesures de base et des outils spécialisés pour des besoins spécifiques.
Choisissez votre système de surveillance en fonction de ce qui compte le plus :
- La voie du bricolage: Lorsque vous avez besoin d'un contrôle granulaire et de fonctions de conformité personnalisées.
- Outils SaaS APM: Lorsque vous souhaitez une surveillance qui fonctionne et évolue avec vous.
- Outils natifs du cloud: Lorsque vos applications sont hébergées dans un seul nuage et que vous souhaitez que tout soit intégré.
Surveillance actionnable : transformer les données en décisions
Maintenant que nous avons abordé les outils de surveillance, mettons ces données à profit. Voici comment transformer les mesures en actions automatisées :
1. Des alertes intelligentes qui favorisent l'action
Configurez des alertes intelligentes qui transforment les données en actions :
- Conscient de l'impact : Concentration sur les mesures critiques pour l'utilisateur et l'entreprise
- Ciblage précis : Acheminement instantané des alertes vers les propriétaires de services
- Contexte riche : Inclure des données de dépannage exploitables
- Seuils dynamiques : Utilisation de lignes de base dynamiques pour réduire le bruit
Modèles d'alertes et de runbooks :
Temps de réponse > 500ms (5min)
actions :
- check_cache_hit_ratio
- vérifier_connexions_db
- scale_service_pods
Taux d'erreur > 1% (1min)
actions :
- inspecter les journaux d'erreurs
- vérifier_dépendances
- rollback_si_nécessaire
Charge CPU > 80% (3min)
actions :
- analyse de l'utilisation des ressources
- optimiser les requêtes
- ajouter_capacité
Échecs du bilan de santé
actions :
- vérifier les points de terminaison
- vérifier_les_certificats
- redémarrage en cas d'absence de réponse
2. Automatisation
Mettons en place des flux de surveillance automatisés :
- Routage des alertes :
- Le routage intelligent envoie les problèmes critiques directement aux bonnes équipes via PagerDuty/Slack.
- Auto-escalade des alertes en fonction de la gravité et des délais de réponse
- Acheminer les types d'alertes par des chemins personnalisés
- Suivi des problèmes :
- Création automatique de tickets avec contexte complet et stacktrace en 2 secondes chrono
- Surveillance des métriques et de la télémétrie comportementale pour mettre en évidence les modèles émergents (temps de réponse inférieur à 100 ms)
- Mise à l'échelle des ressources :
- Mise à l'échelle automatique basée sur des données de performance réelles
- Contrôle des versions :
- Revenir en arrière sur les déploiements et les versions canaris si la métrique commence à se diriger dans la mauvaise direction.
# Exemple de configuration d'alerte alertes : - nom : "Temps de réponse API élevé" métrique : "http_request_duration_seconds_p95" seuil : 500ms duration : "5m" severity : "warning" route_to : "dev-team-channel" notification_type : "slack" - name : "Critical Service Down" metric : "service_health_check_failed" service : "payment-service"
severity : "critical" route_to : "on-call-pager" notification_type : "pagerduty" actions : - "auto_restart_service" - "create_jira_ticket"
3. Des tableaux de bord qui s'affranchissent du bruit
Avec l'automatisation et les alertes intelligentes en place, créons des tableaux de bord ciblés pour obtenir des informations critiques. Voici ce sur quoi nous travaillons :
- Mesures de base : Suivi en temps réel de l'état du système et des performances
- Données de performance : identifiez et résolvez les problèmes de performance avant qu'ils n'affectent vos utilisateurs.
- Boîte à outils de débogage : Permet d'approfondir les mesures lorsque les choses tournent mal.
- Vues basées sur les rôles : Vues basées sur les rôles : créez des tableaux de bord personnalisés en fonction des besoins de chaque équipe.
Une surveillance efficace vous permet de détecter et de résoudre les problèmes techniques avant qu'ils n'affectent vos utilisateurs.
Contrôle des coûts
- Problème : La surveillance coûte de plus en plus cher au fur et à mesure que l'entreprise grandit.
- Solution : Suivez les coûts et optimisez les dépenses en surveillant le stockage des données et les paramètres d'utilisation.
Suivez les indicateurs clés :
Coût mensuel = (Points de données × Temps de stockage) + (Volume de logs × Taux) + (Utilisation des requêtes × Prix)
- Alertes budgétaires précoces
- Des politiques de rétention impitoyables
Faites évoluer votre surveillance
Tout comme les applications qu'ils suivent, les systèmes de surveillance doivent évoluer et s'adapter au fil du temps. Les configurations de surveillance statiques deviennent rapidement obsolètes à mesure que votre architecture évolue, que de nouveaux services sont ajoutés et que les priorités de l'entreprise changent. Une surveillance exceptionnelle n'est pas une mise en œuvre ponctuelle, c'est une pratique permanente qui offre une valeur croissante.
Fixez une fréquence trimestrielle pour évaluer l'ensemble de votre approche de l'observabilité, en examinant les mesures qui fournissent des informations exploitables et celles qui génèrent du bruit. Ce cycle de révision cohérent garantit que vos outils de surveillance détectent les problèmes les plus importants pour votre architecture actuelle et vos objectifs commerciaux, plutôt que de résoudre les problèmes d'hier.
Les organisations d'ingénierie les plus matures traitent leurs configurations de surveillance avec le même soin que le code de l'application - versionné, testé et amélioré en permanence. En abordant la surveillance comme un système vivant plutôt que comme une configuration statique, vous construirez une observabilité qui restera pertinente et utile même si votre configuration technique se transforme.
Votre liste de contrôle pour la surveillance : un point de départ pratique
Construisons votre stratégie de surveillance en fonction des besoins de votre application. Commencez par ces étapes fondamentales :
- Cartographier les principaux flux d'utilisateurs. Documentez vos transactions commerciales critiques et les chemins d'accès des utilisateurs
- Surveillez les paramètres de base : Suivez les temps de réponse, la mémoire de l'unité centrale et les erreurs.
- Ajoutez une journalisation structurée : Utilisez JSON avec des identifiants de requête pour le traçage.
- Mettre en place une surveillance de base : Configurer des contrôles de temps de fonctionnement et des tests de parcours utilisateur
- Créer des tableaux de bord ciblés : Créer des vues qui mettent en évidence les mesures importantes
- Configurer des alertes : Mettre en place des notifications qui incitent à l'action
- Examiner et améliorer : programmer des contrôles réguliers pour affiner votre configuration.
Voie d'évolution de l'observabilité
Voyons comment la surveillance évolue pour répondre à vos besoins :
| Niveau | Capacité de surveillance | Impact sur l'entreprise |
|---|---|---|
| 1 | Mesures et journaux de base | Réponse plus rapide aux incidents |
| 2 | Surveillance structurée | Prévention proactive des problèmes |
| 3 | Auto-remédiation | Temps de fonctionnement de 99,99 |
| 4 | Analyse prédictive | Changements sans impact |
Comment se déroule la surveillance

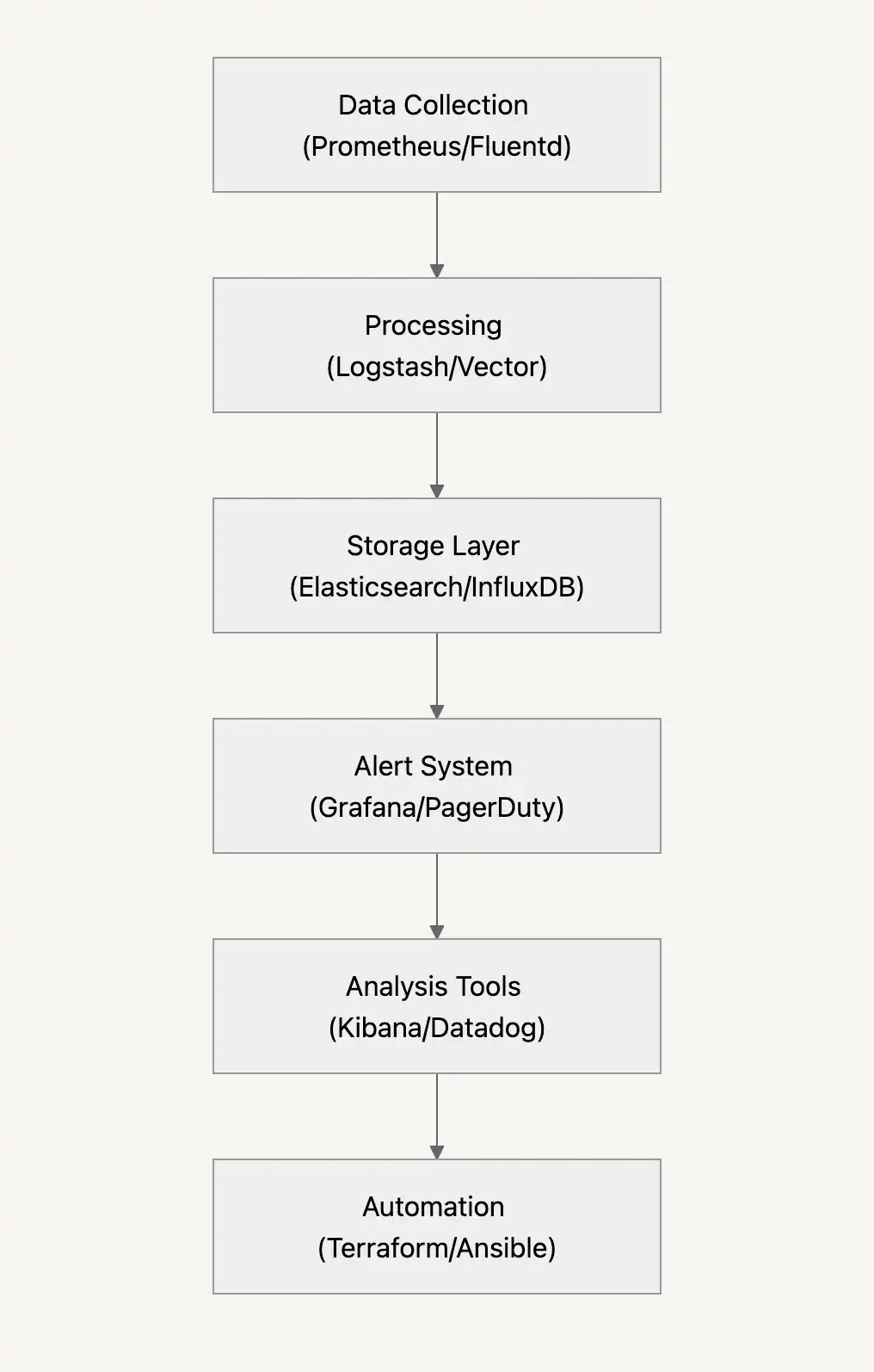
Optimisez votre pipeline de surveillance
Les systèmes de surveillance fiables ont besoin de quelques éléments clés :
- Utiliser un échantillonnage intelligent pour garder les données propres sans perdre de signaux importants.
- Équilibrer les charges de trafic pour capturer toutes les mesures critiques
- Indexer les données pour une détection rapide des problèmes
- Structurer logiquement les données pour simplifier le dépannage
Sécurité
Ce à quoi vous devez penser pour les données de surveillance :
- Filtrer les données sensibles lors de la collecte
- Mettre en œuvre des politiques de conservation conformes à la réglementation
- Contrôler les schémas d'accès dans l'ensemble du système
Mesures clés
Voici ce qu'il faut suivre pour que vos systèmes s'adaptent bien :
- Temps moyen de rétablissement (MTTR): rapidité avec laquelle vous vous remettez d'un incident.
- Temps moyen entre les défaillances (MTBF): Délai entre les problèmes du système - plus il est long, mieux c'est
- Objectifs de niveau de service (SLO) : Vos objectifs et engagements en matière de fiabilité
- Budget d'erreur et taux de consommation: Seuil de défaillance acceptable et taux de consommation
Chaque petite amélioration vous rapproche d'un système de surveillance qui prévient les problèmes plutôt que d'y réagir. Construisez-le étape par étape et regardez les alertes nocturnes devenir une chose du passé.
Votre meilleur travail
est à l'horizon
ComparerAlternative à VercelAlternative à AmazeeAlternative à HerokuAlternative à PantheonAlternative à l'hébergement géréAlternative à Fly.ioAlternative à RenderAlternative à AWSAlternative à AcquiaAlternative à DigitalOcean
ProduitAperçuSupport and servicesPreview environmentsMulti-cloud and edgeGit-driven automationObservability and profilingSecurity and complianceScaling and performanceBackups and data recoveryTeam and access managementCLI, console, and APIIntegrations and webhooksPricingPricing calculator
Cas d'utilisationSolutions backendApplication modernisationCommerce électroniqueHébergement CMSGestion multi sitesExtensions SaaS
Join our monthly newsletter
Compliant and validated