


Fonctionnalités


Les bases de l'indexation des bases de données
MySQLPostgreSQLMariaDBperformancedonnéesflux de travail du développeur
04 août 2025
Cette page a été rédigée en anglais par nos experts, puis traduite par une IA pour vous y donner accès rapidement! Pour la version originale, c’est par ici.
Nous sommes tous passés par là un jour ou l'autre : une application fonctionnant parfaitement ralentit soudainement à mesure que votre base de données s'agrandit. L'application, qui fonctionnait auparavant à la vitesse de l'éclair avec des requêtes portant sur 10 000 enregistrements, prend désormais une éternité avec 10 millions d'enregistrements. Le coupable ? Des index de base de données manquants.
L'indexation de la base de données peut transformer les balayages de table lents en recherches rapides comme l'éclair en créant des structures de données optimisées qui agissent comme des raccourcis vers vos informations. C'est un peu comme s'il était préférable de feuilleter toutes les pages d'un annuaire téléphonique plutôt que d'accéder directement à la bonne section en utilisant les onglets alphabétiques, sauf que la différence de performance se mesure en millisecondes plutôt qu'en minutes.
Comprendre les bases de l'indexation des bases de données et ses différents types vous permettra d'améliorer de manière significative les performances des requêtes dans les grandes bases de données.
Dans cet article, nous présentons l'indexation des bases de données et explorons les différents types de techniques d'indexation, et nous démontrons des implémentations pratiques qui peuvent améliorer considérablement les performances de vos requêtes.
Qu'est-ce que l'indexation des bases de données et comment fonctionne-t-elle ?
Un index de base de données est une structure de données supplémentaire qui fournit une référence rapide pour des colonnes spécifiques, permettant à la base de données de localiser des données sans avoir à parcourir l'ensemble de la table.
L'index est structuré sous la forme d'une liste triée de valeurs provenant des colonnes indexées, chaque valeur étant liée à un pointeur qui renvoie à la ligne correspondante dans la table principale. Lorsque vous interrogez la base de données, celle-ci consulte d'abord cet index trié pour trouver les valeurs souhaitées, puis utilise les pointeurs stockés pour accéder directement aux lignes correspondantes du tableau.
La plupart des index utilisent une structure "B-tree", qui organise les données en couches, permettant à la base de données de restreindre rapidement sa recherche en suivant les branches. Certains index, en particulier pour les valeurs uniques, utilisent une table de hachage, qui convertit les valeurs en codes uniques pointant directement vers les lignes.
Mais comme l'index est une structure distincte, il utilise un espace de stockage supplémentaire dans la base de données et doit également être mis à jour lorsque les données des colonnes indexées changent. Ces mécanismes de stockage et de mise à jour peuvent être mis en œuvre différemment selon les systèmes de base de données.
Pourquoi avons-nous besoin de l'indexation des bases de données ?
Les index améliorent les performances de recherche des bases de données en éliminant le besoin de balayage complet des tables. Sans index, lorsque vous interrogez une base de données, celle-ci doit vérifier séquentiellement chaque ligne jusqu'à ce qu'elle trouve les données recherchées. Un index permet à la base de données de localiser rapidement les enregistrements en se référant à la structure triée, ce qui est particulièrement utile pour traiter efficacement les clauses WHERE sans analyser chaque ligne. Cela améliore considérablement les performances des requêtes, en particulier pour les grands ensembles de données pour lesquels un balayage séquentiel ne serait pas pratique.
Par exemple, lorsque vous recherchez un client par son numéro de téléphone dans une base de données contenant des millions d'enregistrements, un index sur la colonne du numéro de téléphone permet à la base de données d'identifier instantanément les enregistrements correspondants.
Bien que les index améliorent considérablement les performances de lecture, ils ont une contrepartie. Chaque fois que vous insérez, mettez à jour ou supprimez des données dans une colonne indexée, la base de données doit également mettre à jour les structures d'index associées. Cela ajoute des E/S de disque supplémentaires et une surcharge de traitement, ce qui peut ralentir les opérations d'écriture. Il est donc essentiel de peser soigneusement ces compromis lors du choix des colonnes à indexer.
Types d'index
Cette section traite de trois types d'index qui peuvent améliorer les performances des requêtes SQL.
Index B-tree
Les arbres B sont un type d'index largement utilisé dans les bases de données pour organiser les données dans une structure triée en couches. Cette structure arborescente auto-équilibrée permet aux bases de données de localiser rapidement des lignes spécifiques, évitant ainsi de devoir parcourir des tables entières.

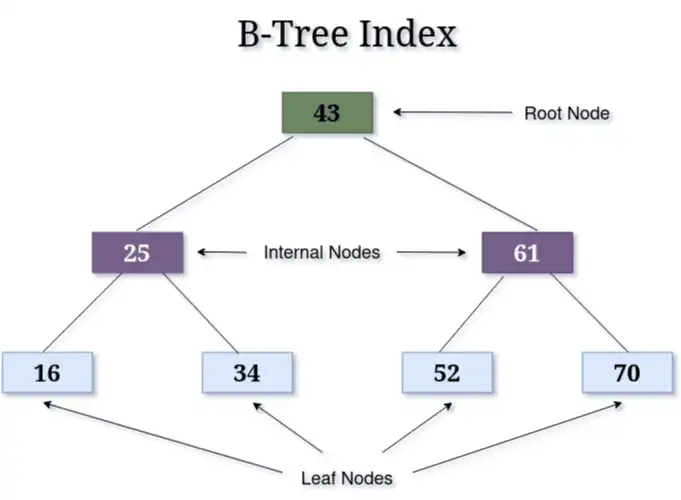
Comme le montre le diagramme, les arbres B organisent les données en sections plus petites et triées sur différentes branches. Les valeurs sont classées de la plus basse (à gauche) à la plus haute (à droite). Cette structure permet d'effectuer des requêtes efficaces sur des plages de valeurs et des recherches rapides. Au fur et à mesure que des données sont ajoutées, l'arbre B ajuste ses branches et ses nœuds afin de conserver sa forme triée et équilibrée, ce qui garantit également que les recherches restent efficaces même lorsque la base de données s'agrandit.
La base de données utilise la valeur indexée comme clé de l'arbre B et stocke un pointeur vers l'enregistrement comme valeur de l'arbre B. Lorsque vous recherchez un enregistrement à l'aide d'une clé de l'arbre B, vous pouvez utiliser la clé de l'arbre B. Lorsque vous recherchez un enregistrement avec une valeur spécifique, la base de données trouve la clé correspondante, récupère le pointeur, puis obtient l'enregistrement.
L'arbre B+ est une variante spécialement conçue pour les systèmes de stockage de bases de données. Contrairement aux arbres B standard, les arbres B+ stockent toutes les données uniquement dans les nœuds feuilles et relient ces feuilles entre elles. C'est pourquoi la plupart des moteurs de base de données (comme InnoDB de MySQL) utilisent des arbres B+ plutôt que des arbres B standard pour leurs index.
Le saviez-vous ? De nombreuses bases de données populaires, telles que MySQL, PostgreSQL et Oracle, utilisent des index B-tree ou B+ tree comme méthode d'indexation par défaut, y compris pour les clés primaires.
Index de hachage
Les index de hachage diffèrent des arbres B par leur mécanisme sous-jacent. Ils utilisent une fonction de hachage, un algorithme mathématique qui convertit les données d'entrée en un code unique, ou hachage, représentant ces données.
L'indexation par hachage fonctionne en deux étapes :
- La valeur de la colonne indexée passe par la fonction de hachage pour générer un code de hachage unique.
- Ce code de hachage sert de pointeur à l'emplacement de la ligne dans la table de la base de données.
Le diagramme ci-dessous illustre la manière dont les index de hachage font correspondre les valeurs hachées aux emplacements de la base de données.

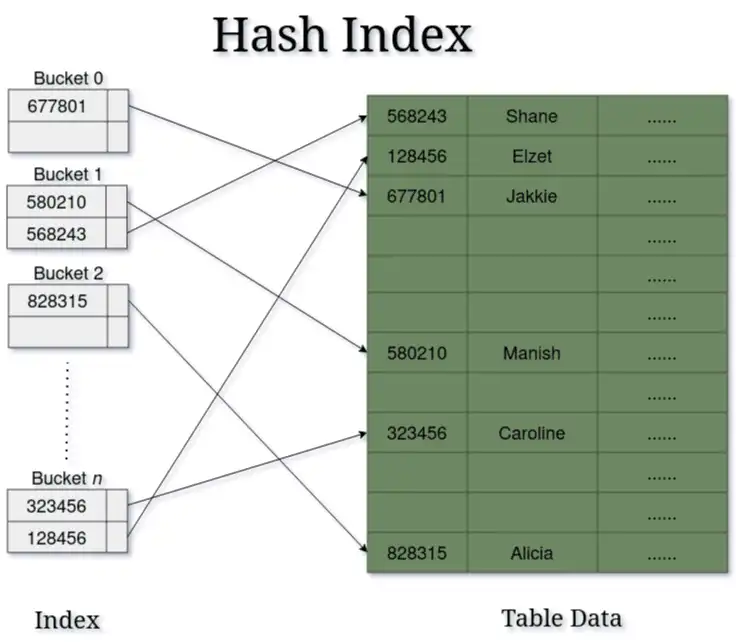
Cette approche de mise en correspondance directe permet des recherches en temps constant O(1), ce qui rend les index de hachage particulièrement efficaces pour les requêtes de correspondance exacte, telles que la recherche d'un numéro d'identification de client ou d'un numéro de commande spécifique avec les clauses WHERE column = 'value'.
Cependant, les index de hachage ont une limitation critique : ils ne fonctionnent que pour les correspondances exactes. Étant donné que les fonctions de hachage brouillent l'ordre naturel des données, vous ne pouvez pas utiliser les index de hachage pour les requêtes de plage (comme WHERE age > 25), les opérations de tri ou les correspondances de motifs. Ils ne conviennent donc pas à la plupart des scénarios réels nécessitant une grande souplesse d'interrogation.
Index plein texte
Les index plein texte sont des index spécialisés qui accélèrent considérablement la recherche dans les champs de texte volumineux en indexant des mots individuels (termes) dans une colonne de texte. Plutôt que de traiter un texte comme une entité unique pour une correspondance exacte, un index plein texte le décompose en termes consultables, ce qui améliore la vitesse de la base de données lors du traitement de recherches textuelles complexes, comme la recherche de tous les enregistrements contenant un mot ou une phrase spécifique.
Une structure couramment utilisée pour l'indexation plein texte est l'index inversé, qui associe essentiellement des mots (ou des termes) aux documents contenant ces mots. Par exemple, si nous avons trois documents et que le premier et le deuxième contiennent le mot " fraise", l'index inversé montrera que "fraise" pointe vers les documents 1 et 2.
Voici une illustration simple de ce concept :

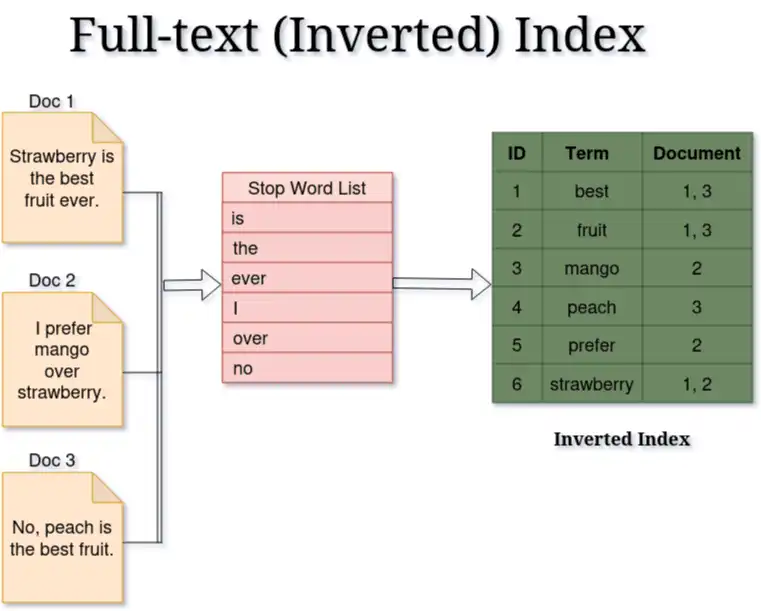
Remarque : les index en texte intégral ignorent généralement les mots courants tels que "the", "is" et "and" (appelés "stop-words") afin d'économiser de l'espace et d'améliorer les performances de recherche. En ignorant ces mots fréquents et de faible importance, l'index peut gagner de l'espace et améliorer l'efficacité de la recherche.
Les index en texte intégral sont particulièrement utiles pour les applications qui nécessitent des capacités de recherche avancées. Ils sont idéaux pour la recherche de grands volumes de texte, comme la recherche de mots-clés spécifiques dans des articles, l'identification de caractéristiques dans des descriptions de produits ou la localisation d'expressions dans des messages d'utilisateurs. Envisagez de créer un index plein texte sur un champ de texte volumineux si une application doit effectuer des recherches dans son contenu. Par exemple, vous pouvez ajouter un index plein texte au champ product_description si les utilisateurs recherchent fréquemment des caractéristiques de produits, telles que bluetooth ou sans fil.
Cependant, les index plein texte occupent un espace de stockage beaucoup plus important et nécessitent une maintenance permanente au fur et à mesure que des données textuelles sont ajoutées ou mises à jour. Ils sont également plus lents pour les simples requêtes de correspondance exacte que les autres types d'index, ce qui les rend plus adaptés aux opérations de recherche textuelle.
Index groupés et non groupés
Les index peuvent également être classés en index en grappe et en index non en grappe (secondaires). Un index en grappe définit l'ordre physique des données dans une table, et une table ne peut avoir qu'un seul index en grappe. Les index non groupés sont stockés séparément, avec des pointeurs vers les lignes concernées, et une table peut avoir plusieurs index non groupés. Un index en grappe est un livre entier organisé dans un ordre spécifique (comme un annuaire téléphonique, trié par ordre alphabétique), tandis que les index non en grappe sont comme des signets qui pointent vers les pages pertinentes.
Le saviez-vous ? Dans MySQL (InnoDB), la clé primaire sert par défaut d'index clusterisé. Dans PostgreSQL, il n'y a pas de véritables index groupés ; chaque index, y compris la clé primaire, est techniquement un index secondaire.
Quand utiliser les index et quand les éviter ?
Les index sont plus efficaces sur les colonnes qui sont fréquemment recherchées, triées ou utilisées dans les opérations de JOIN, telles que les clés primaires, les clés étrangères ou les champs dans les clauses WHERE. Une bonne pratique consiste à créer des index sur les colonnes utilisées pour filtrer des ensembles de données volumineux (comme l'âge et le niveau d'expérience) et à améliorer les performances des requêtes. En outre, envisagez d'indexer les colonnes impliquées dans le tri (ORDER BY) ou l'agrégation (GROUP BY), car ces opérations bénéficient d'un accès plus rapide aux données grâce aux index. Les index peuvent également être utiles pour les colonnes impliquées dans les agrégations (fonctions SQL telles que SUM(...) et AVG(...)), où la synthèse des données peut devenir un goulot d'étranglement en l'absence de chemins d'accès rapides.
Mais les index ajoutent des frais généraux de stockage et de maintenance, il faut donc être prudent lorsqu'on les utilise sur des tables fréquemment mises à jour. Si une table est constamment insérée ou mise à jour, chaque changement nécessite la modification de l'index, ce qui peut ralentir les opérations d'écriture. Évitez de créer des index sur des colonnes peu sélectives, telles que les champs booléens ou binaires, car ils ont peu de valeurs distinctes et n'offrent que peu d'avantages en termes de performances, tout en ajoutant des frais généraux inutiles. Enfin, pour les très petites tables, l'indexation est souvent inutile car la base de données peut rapidement analyser la totalité de la table sans impact notable sur les performances.
Exemples concrets d'indexation de bases de données
Examinons quelques exemples concrets d'indexation de bases de données. Les sections suivantes utilisent une table SQL de base pour démontrer comment l'indexation peut améliorer les performances des requêtes. Ces exemples utilisent la syntaxe SQL standard, sauf mention contraire.
Voici une table "utilisateurs" de base avec des colonnes pour le nom, l'adresse électronique, l'âge, la biographie et l'identifiant en tant que clé primaire :
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100) UNIQUE,
age INT,
bio TEXT
);
Exemple d'index B-tree
Supposons que vous interrogiez fréquemment la colonne age pour trouver des utilisateurs d'une tranche d'âge spécifique, par exemple ceux âgés de vingt-cinq à trente-cinq ans. Une requête typique serait la suivante :
SELECT * FROM users WHERE age BETWEEN 25 AND 35 ;
Sans index, la base de données effectue un balayage complet de la table, en vérifiant chaque ligne pour voir si age est compris dans la fourchette. Cette approche peut s'avérer très lente au fur et à mesure que la table s'agrandit.
Pour optimiser ces requêtes, vous pouvez créer un index B-tree sur la colonne age:
CREATE INDEX idx_age ON users(age) ;
Remarque: B-tree est le type d'index par défaut dans MySQL et PostgreSQL, de sorte que lorsque vous créez un index standard, il s'agit généralement d'un index B-tree.
Avec cet index en place, la base de données peut naviguer dans la colonne triée de l'age en utilisant la structure B-tree. Cela lui permet d'ignorer les lignes non pertinentes et de se concentrer uniquement sur celles qui correspondent aux conditions de la requête. Pour les requêtes de plage telles que BETWEEN, les index B-tree sont particulièrement efficaces car ils sont conçus pour prendre en charge l'accès aux données ordonnées.
Ainsi, si vous exécutez la même requête avec l'index, la charge de travail de la base de données est considérablement réduite, ce qui se traduit par une exécution plus rapide de la requête. Ce gain de performance devient de plus en plus important au fur et à mesure que la table s'agrandit.
Exemple d'index de hachage
Un autre cas d'utilisation courant est la recherche d'utilisateurs par leur adresse électronique, par exemple au cours d'une procédure de connexion. Les adresses électroniques étant uniques et recherchées avec précision, l'indexation par hachage peut être une solution efficace pour les requêtes de correspondance exacte.
Voici une requête qui recherche un utilisateur par son adresse électronique :
SELECT * FROM users WHERE email = 'jane.doe@example.com' ;
Sans index, la base de données doit vérifier la valeur exacte du champ e-mail de chaque ligne, ce qui peut s'avérer très lent pour les tables volumineuses.
Pour garantir de bonnes performances sur cette requête cruciale, vous pouvez créer un index de hachage avec le code SQL suivant :
CREATE INDEX idx_email_hash ON users USING hash(email) ;
Si vous réexécutez la même requête maintenant, avec l'index en place, la base de données saute directement à la ligne de courriel correspondante (ou vérifie le hachage spécifique), ce qui accélère considérablement les correspondances exactes.
Là encore, la base de données n'a plus besoin de parcourir chaque ligne ; elle utilise l'index de hachage pour localiser directement la ligne correspondante, ce qui rend les recherches exactes extrêmement efficaces, en particulier pour les grands ensembles de données.
Ainsi, toute application ayant un grand nombre d'utilisateurs qui se connectent avec leur adresse électronique bénéficierait grandement d'un index de hachage sur le champ de l'email.
Remarque: les index de hachage sont pris en charge en natif par PostgreSQL, mais MySQL ne dispose pas d'index de hachage en natif. Même lorsque vous demandez à une table InnoDB de créer un index de hachage, elle le transforme en un arbre B.
Exemple d'index plein texte
Enfin, imaginons que vous disposiez d'une base de données d'utilisateurs contenant des biographies engageantes et que vous souhaitiez trouver les utilisateurs intéressés par les films.
Une requête courante serait la suivante :
SELECT * FROM users WHERE bio LIKE '%movies%' ;
Sans index plein texte, cette requête nécessite d'analyser le champ bio de chaque ligne et de vérifier s'il contient le texte spécifié (à l'aide du motif "%keyword%" ), ce qui peut s'avérer extrêmement lent pour les champs texte volumineux.
Si vous devez fréquemment rechercher des mots-clés spécifiques dans de grands champs de texte d'une base de données, la création d'un index plein texte peut considérablement améliorer les performances.
La syntaxe de création d'un index plein texte diffère d'une base de données à l'autre. Voici comment en créer un dans PostgreSQL et MySQL :
-- PostgreSQL
CREATE INDEX idx_bio_fulltext ON users USING GIN (to_tsvector('english', bio));
-- MySQL
CREATE FULLTEXT INDEX idx_bio_fulltext ON users(bio);
MySQL dispose d'un support intégré pour l'indexation plein texte sur les colonnes VARCHAR et TEXT. Dans PostgreSQL, vous créez un index plein texte en utilisant l'index inversé généralisé (GIN) sur le résultat de la fonction to_tsvector.
Avec l'index plein texte en place, vous pouvez maintenant exécuter des requêtes de recherche plein texte pour trouver les utilisateurs intéressés par les films:
-- PostgreSQL
SELECT * FROM users WHERE to_tsvector('english', bio) @@ to_tsquery('movies');
-- MySQL
SELECT * FROM users WHERE MATCH(bio) AGAINST ('movies' IN NATURAL LANGUAGE MODE);
Avec un index plein texte, la base de données peut rechercher des mots-clés dans de grands champs de texte, ce qui évite d'avoir à parcourir chaque ligne. Les recherches de mots-clés sont donc beaucoup plus rapides, en particulier lorsqu'il s'agit de colonnes contenant beaucoup de texte.
Conclusion
L'indexation de la base de données n'est pas seulement une optimisation des performances ; elle fait souvent la différence entre une application qui évolue et une autre qui s'effondre sous la charge. Les techniques que nous avons abordées aujourd'hui peuvent transformer vos requêtes les plus lentes en opérations rapides comme l'éclair, mais seulement si vous les mettez en œuvre de manière stratégique.
Quelle est la prochaine étape ? Commencez par identifier les requêtes les plus fréquentes et les modèles de trafic les plus importants de votre application. Concentrez-vous sur l'indexation des colonnes qui apparaissent dans les clauses WHERE, les conditions JOIN et les instructions ORDER BY. N'oubliez pas que chaque index est un compromis entre la vitesse de lecture et les performances d'écriture ; choisissez-le judicieusement.
Mais voici la réalité: gérer l'optimisation des performances de la base de données dans plusieurs environnements, surveiller les modèles de requêtes et maintenir les index au fur et à mesure de l'évolution de votre application peut rapidement devenir insurmontable. Vous avez besoin de plus que de simples connaissances en matière d'indexation ; vous avez besoin d'une plateforme qui rend l'optimisation des performances transparente.
C'est là qu'Upsun transforme votre flux de développement. Au lieu de jongler avec les configurations de base de données entre staging et production, Upsun fournit un clonage instantané de l'environnement avec des données réelles, de sorte que vous pouvez tester vos stratégies d'indexation par rapport à des modèles de requêtes réels avant qu'elles ne soient mises en ligne. Grâce au profilage d'observabilité intégré, vous repérez instantanément les goulets d'étranglement en matière de performances et obtenez des recommandations concrètes pour l'optimisation.
Prêt à arrêter de deviner les performances de la base de données ? Commencez votre essai gratuit d'Upsun et découvrez ce que c'est que d'optimiser en toute confiance, avec les outils et les informations qui rendent la gestion des performances des bases de données sans effort.
Votre meilleur travail
est à l'horizon
ComparerAlternative à VercelAlternative à AmazeeAlternative à HerokuAlternative à PantheonAlternative à l'hébergement géréAlternative à Fly.ioAlternative à RenderAlternative à AWSAlternative à AcquiaAlternative à DigitalOcean
ProduitAperçuSupport and servicesPreview environmentsMulti-cloud and edgeGit-driven automationObservability and profilingSecurity and complianceScaling and performanceBackups and data recoveryTeam and access managementCLI, console, and APIIntegrations and webhooksPricingPricing calculator
Cas d'utilisationSolutions backendApplication modernisationCommerce électroniqueHébergement CMSGestion multi sitesExtensions SaaS
Join our monthly newsletter
Compliant and validated