


Fonctionnalités


Comprendre les principes de conception d'une API RESTful
APIDevOpsmicroservicesl'allocation des ressources
19 décembre 2024
Cette page a été rédigée en anglais par nos experts, puis traduite par une IA pour vous y donner accès rapidement! Pour la version originale, c’est par ici.
Les API RESTful permettent aux applications clientes d'accéder à des ressources (données) hébergées sur un serveur distant et de les manipuler à l'aide d'un ensemble normalisé de règles et de protocoles. REST (representational state transfer) est un ensemble de principes architecturaux qui définissent la manière de concevoir et de mettre en œuvre ces interfaces. Les principes clés de la conception RESTful comprennent l'utilisation de méthodes HTTP telles que POST, GET, PATCH et DELETE pour effectuer des opérations CRUD (create, read, update, delete), l'identification des ressources par le biais d'URLs uniques et le transfert de données dans un format léger tel que le JSON. Les API RESTful constituent un moyen souple et standard pour les systèmes de communiquer entre eux sur Internet, ce qui en fait un élément fondamental des applications web et mobiles modernes.
Cet article couvre les principes fondamentaux de la conception d'une API RESTful. À la fin, nous explorerons les principes clés de REST, leur comparaison avec d'autres paradigmes et les meilleures pratiques pour la conception d'API RESTful.
Principes de conception des API
Avant d'entrer dans les détails, examinons brièvement comment RESTful se compare à d'autres méthodologies populaires de conception d'API.
RESTful
Comme nous l'avons mentionné, les API REST sont structurées autour de ressources (noms) plutôt que d'actions, et utilisent des méthodes HTTP standard (GET, POST, PUT, DELETE) pour manipuler ces ressources. Les API RESTful s'articulent autour de plusieurs principes clés pour des services web cohérents et évolutifs :
- Communication sans état. Les requêtes de l'API REST contiennent toutes les informations nécessaires, sans qu'aucun contexte client ne soit stocké sur le serveur entre les requêtes.
- Interface uniforme. Ce principe garantit une identification et une manipulation cohérentes des ressources grâce à des messages auto-descriptifs utilisant des en-têtes HTTP et des codes de statut standard. Il intègre également le principe HATEOAS (hypermedia as the engine of application state), qui permet aux clients de découvrir les capacités de l'API de manière dynamique.
GraphQL
Créé par Facebook, GraphQL est un langage de requête et un moteur d'exécution qui permet de récupérer des données de manière plus efficace et plus souple que les points de terminaison REST traditionnels. Ses principes de conception fondamentaux sont les suivants :
- Flexibilité des requêtes. Cela permet aux clients de spécifier les données dont ils ont besoin dans la réponse. Cela signifie que plusieurs ressources peuvent être demandées en une seule requête, tout en éliminant la recherche excessive ou insuffisante de données.
- Architecture à point d'accès unique. Elle achemine toutes les demandes par l'intermédiaire d'un seul point d'accès, en différenciant les opérations en fonction des types de requêtes et de mutations. Un schéma définit toutes les opérations et tous les types possibles au sein de l'architecture.
- Système de typage fort. Il sert de contrat entre le client et le serveur, fournissant une validation de type et une documentation intégrées tout en permettant de puissants outils de développement et de vérification de type.
gRPC
Créé par Google, gRPC est un cadre d'appel de procédure à distance (RPC, remote procedure call) basé sur HTTP/2. Son fonctionnement repose sur les principes fondamentaux suivants :
- Développement par contrat d'abord. Utilise protobuf comme langage de définition d'interface (IDL) strict, permettant la génération automatique de code pour les implémentations du client et du serveur.
- Prise en charge de la diffusion en continu. Inclut des capacités de streaming unaire, serveur, client et bidirectionnel, ce qui le rend efficace pour la communication en temps réel et les transferts de données importants, en particulier dans le cadre de la communication entre microservices.
- Protocole binaire. Il utilise HTTP/2 comme couche de transport, ce qui permet une sérialisation binaire très efficace. Il en résulte une latence plus faible et de meilleures performances par rapport aux protocoles basés sur le texte.
Aperçu des principes de conception des API
Voici un tableau qui résume certaines des différences entre ces conceptions :
| REST | GraphQL | gRPC | |
| Cas d'utilisation | Meilleur pour les opérations CRUD et l'extraction de ressources standard | Idéal pour les requêtes complexes et les scénarios dans lesquels les clients ont besoin de données spécifiques | Idéal pour les microservices et les applications à haute performance nécessitant une communication en temps réel |
| Format des données | JSON et XML, entre autres | JSON | protobuf (binaires) |
| Style de requête | Orienté ressources (CRUD) | Orienté requête | Orienté procédure |
| Mise en cache | Mise en cache HTTP intégrée | Implémentation personnalisée requise | Implémentation personnalisée requise |
| Sécurité des types | Pas de sécurité de type intégrée | Système de type fort | Système de type fort |
| Gestion des erreurs | Codes de statut HTTP standard | Réponses d'erreur personnalisées via JSON | Gestion personnalisée des erreurs via protobuf |
Vue d'ensemble de l'architecture de l'API RESTful
Un système utilisant une API RESTful comprend généralement trois composants clés : le client, le serveur et la base de données. Il comprend également des éléments supplémentaires tels qu'un équilibreur de charge, une mise en cache et un service d'authentification.

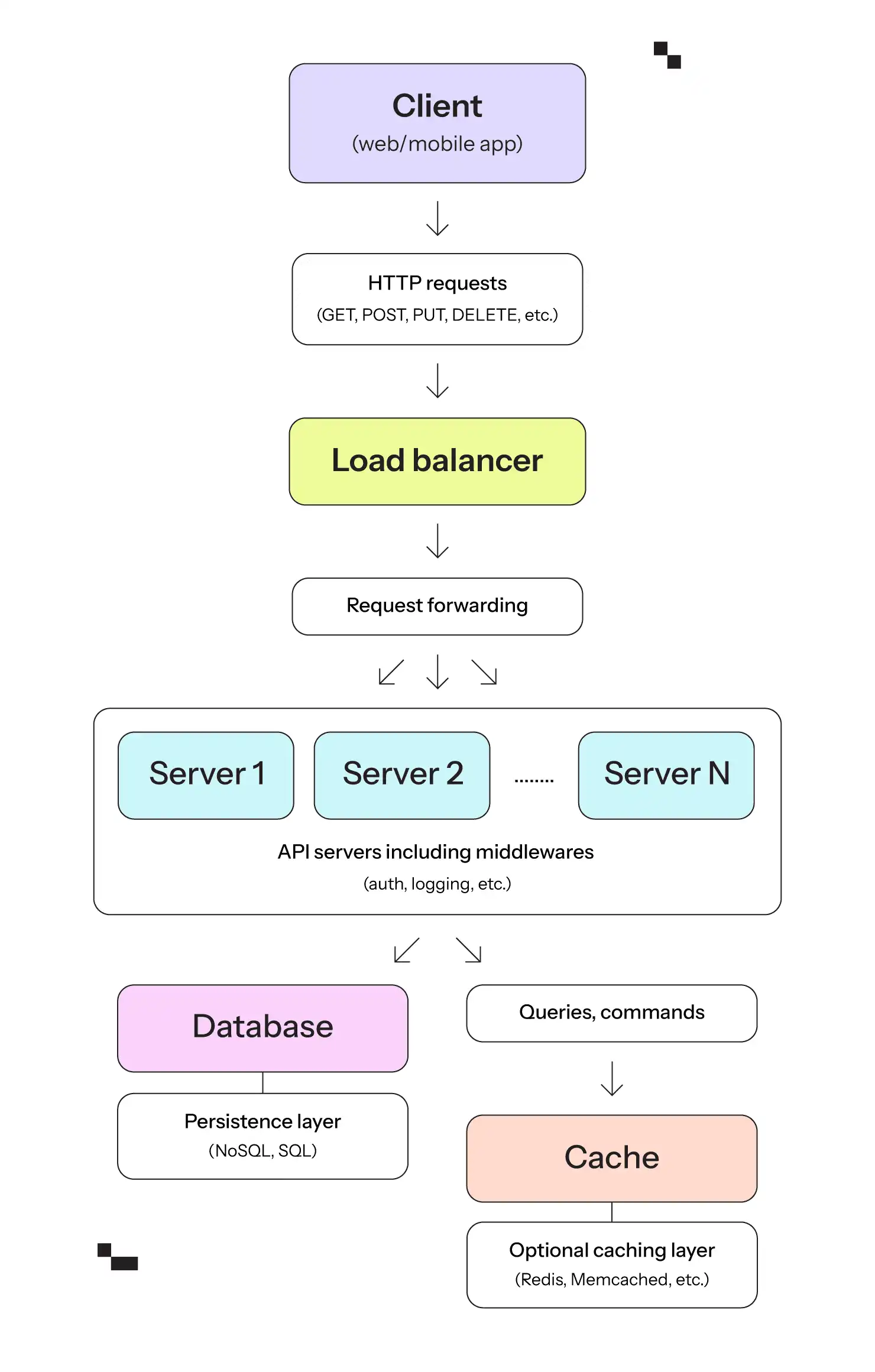
Le client
Le client est une application ou un appareil qui utilise l'API. Il peut s'agir d'un navigateur web, d'une application mobile ou d'un autre serveur dans une architecture microservices. Les clients envoient des demandes au serveur à l'aide de méthodes HTTP ( GET, POST, PUT, DELETE, etc) pour effectuer des opérations CRUD sur les ressources - par exemple, une application mobile qui récupère les données de l'utilisateur en effectuant une demande GET à l'adresse https://api.example.com/users.
Serveur API
Le serveur héberge l'API et est chargé de traiter les demandes entrantes des clients, d'interagir avec la base de données ou d'autres services et de renvoyer les réponses. Le serveur interprète les requêtes HTTP, effectue les opérations nécessaires (telles que la création, l'extraction, la mise à jour ou la suppression de ressources) et renvoie les codes de statut HTTP et les données appropriés.
Les intergiciels (middleware) constituent des couches optionnelles qui peuvent être intégrées dans l'architecture du serveur pour gérer des fonctionnalités supplémentaires. Il peut s'agir de l'authentification, de la journalisation, de la validation des données, de la gestion des erreurs et de la transformation des requêtes/réponses. L'intergiciel traite les demandes avant qu'elles n'atteignent la logique centrale du serveur et peut également modifier les réponses avant qu'elles ne soient renvoyées au client.
Base de données
La base de données stocke les données de l'application. Il peut s'agir d'une base de données relationnelle (comme PostgreSQL ou MySQL), d'une base de données NoSQL (comme MongoDB) ou de toute autre forme de stockage de données. Le serveur utilise la base de données pour stocker et récupérer de manière persistante des données, telles que les informations sur les utilisateurs, les détails des produits ou l'historique des transactions.
Dans la base de données, une couche de mise en cache stocke des copies des données fréquemment demandées afin de réduire la nécessité d'accéder à la base de données de manière répétée. Elle contribue à réduire le temps de latence en fournissant des données à partir du cache au lieu d'interroger la base de données à chaque fois. Pour ce faire, on utilise souvent des bases de données en mémoire, telles que Redis ou Memcached.
Équilibreur de charge
Un équilibreur de charge peut être utilisé pour répartir les demandes des clients entrants sur plusieurs instances de serveur. Cela permet d'assurer une haute disponibilité et une grande évolutivité, en évitant qu'un seul serveur ne devienne un goulot d'étranglement. Il équilibre le trafic entre plusieurs instances de serveur afin d'améliorer les temps de réponse, assure la tolérance aux pannes en réacheminant les demandes si un serveur ne répond plus, et peut également gérer la terminaison SSL afin de décharger les serveurs du chiffrement et du déchiffrement.
Principales caractéristiques des API REST
Les API REST reposent sur plusieurs principes fondamentaux qui définissent leur architecture et leur comportement.
Architecture client-serveur
Dans une architecture d'API RESTful, le client et le serveur fonctionnent indépendamment l'un de l'autre. Le client (par exemple un navigateur web ou une application mobile) est responsable de l'interface utilisateur et lance les demandes, tandis que le serveur s'occupe du traitement des données et des réponses. Cette séparation des préoccupations permet une maintenance et une flexibilité à long terme.
Par exemple, une application mobile peut interagir avec le serveur REST à l'aide de son API sans avoir à comprendre les détails de la mise en œuvre. Si l'API du backend comprend le code de l'interface utilisateur, cela crée un couplage étroit entre le client et le serveur, ce qui pose des problèmes de dépendance et rend les mises à jour plus difficiles.
Communication sans état
Comme nous l'avons mentionné, dans une architecture sans état, chaque demande du client au serveur contient toutes les informations nécessaires au traitement de la demande. Le serveur ne stocke aucune donnée de session spécifique au client. Il est donc plus facile pour la couche serveur de l'API de s'étendre horizontalement. Comme chaque demande est autonome, les serveurs peuvent les traiter indépendamment, ce qui simplifie l'équilibrage de la charge. Cela signifie également que les serveurs n'ont pas besoin de stocker l'état de la session, ce qui réduit la charge de mémoire.
Par exemple, un appel API de connexion doit inclure les informations d'identification de l'utilisateur dans chaque demande plutôt que de s'appuyer sur un identifiant de session stocké sur le serveur. Cela permet à n'importe quel serveur d'une grappe de traiter la demande sans avoir besoin d'un contexte préalable. Si un serveur s'appuie sur des données de session stockées entre les requêtes, il complique la mise à l'échelle et permet difficilement aux équilibreurs de charge de distribuer les requêtes de manière homogène.
Réponses pouvant être mises en cache
Les réponses des API RESTful peuvent être mises en cache, ce qui permet aux clients ou aux intermédiaires de stocker les réponses pendant un certain temps. Cela minimise le besoin de demandes répétées pour les mêmes données. Les données mises en cache peuvent être servies plus rapidement qu'en interrogeant le serveur à chaque fois. Elles réduisent également la latence et la charge du serveur, ce qui améliore l'expérience de l'utilisateur et l'évolutivité.
Une réponse d'API peut inclure des en-têtes de mise en cache tels que Cache-Control et Expires, permettant au client de stocker temporairement les données et d'éviter les appels inutiles au serveur. Par exemple, une réponse d'API météorologique pouvant être mise en cache peut réduire la nécessité de mises à jour fréquentes si les données restent inchangées pendant une heure. Si les réponses ne comportent pas d'en-têtes de mise en cache, les clients demanderont à plusieurs reprises les mêmes données, ce qui alourdira inutilement la charge du serveur et ralentira le temps de réponse pour l'utilisateur final.
Système en couches
Un système en couches permet aux API de fonctionner sur plusieurs couches, telles que des intermédiaires, des équilibreurs de charge et des passerelles, sans que le client n'ait connaissance de ces couches. Cette approche offre une sécurité et une évolutivité accrues. Par exemple, les équilibreurs de charge peuvent aider à distribuer le trafic sans que le client ait besoin de savoir comment la charge est équilibrée. Cette modularité facilite l'évolution ou la sécurisation de certaines parties du système sans qu'il soit nécessaire de revoir la conception de l'ensemble de l'API.
Lorsqu'un client fait un appel à une API, il peut être automatiquement acheminé par un équilibreur de charge et un pare-feu, ce qui permet d'optimiser les performances et la sécurité sans modifier le code du client. Si un client doit interagir directement avec plusieurs serveurs dorsaux ou comprendre comment les demandes sont distribuées, cela introduit de la complexité et rompt l'abstraction en couches.
Interface uniforme
Un autre principe fondamental des API REST est la contrainte d'interface uniforme, qui est un ensemble de règles standard pour interagir avec l'API. Cela inclut l'utilisation cohérente des méthodes HTTP (GET, POST, PUT, DELETE), des modèles d'URL standard et des formats de réponse prévisibles. Une interface uniforme améliore la convivialité de l'API, en permettant aux développeurs de prévoir plus facilement la manière dont l'API répondra aux demandes. Cette cohérence réduit la courbe d'apprentissage et la probabilité d'erreurs.
Une API RESTful utilise des méthodes HTTP de manière cohérente pour toutes les ressources (par exemple, GET /users récupère les utilisateurs, POST /users crée un utilisateur), ce qui garantit l'uniformité et la prévisibilité. Une API qui utilise des méthodes non standard ou qui mélange des méthodes HTTP (par exemple, l'utilisation de GET pour créer une ressource) peut dérouter les développeurs et rendre l'API plus difficile à utiliser de manière fiable.
Code à la demande
Le code à la demande est une contrainte architecturale REST facultative qui permet aux serveurs d'étendre les fonctionnalités des clients en leur transmettant du code exécutable tel que JavaScript au moment de l'exécution, par exemple en chargeant des widgets dynamiques ou en mettant à jour des composants de l'interface utilisateur sans rafraîchissement de la page.
Cela permet au client d'étendre les fonctionnalités de manière dynamique sans avoir à mettre à jour son code. Il apporte de la flexibilité et peut améliorer la fonctionnalité en permettant aux clients d'exécuter du code directement à partir du serveur, en particulier dans les applications web dynamiques.
Conclusion
Cet article a exploré le concept des principes de conception des API RESTful et les composants essentiels qui rendent une API RESTful. Nous avons commencé par une présentation des différentes possibilités de conception d'API et une topologie de l'architecture typique d'un système RESTful, puis nous avons approfondi les composants clés des API RESTful. Le respect des principes de conception des API RESTful peut améliorer la qualité du code et garantir que vos API servent les utilisateurs de manière efficace et efficiente, ce qui rend votre application plus performante à long terme.
Upsun permet aux équipes de développement modernes d'expérimenter facilement, d'itérer rapidement et d'évoluer sans effort dans toutes les dimensions. Il s'agit d'une plateforme d'application en nuage libre-service, entièrement gérée, sécurisée et axée sur les développeurs, avec une observabilité intégrée, une mise en cache multicloud, un déploiement fiable et la liberté de choisir votre pile et votre fournisseur de nuage. Avec Upsun, vous pouvez créer et exécuter des applications API RESTful en utilisant les langages de programmation et les frameworks de votre choix. Vous avez un contrôle total sur la façon dont les applications évoluent (horizontalement ou verticalement) tandis qu'Upsun gère le gros du travail, y compris l'allocation des ressources et les pics de trafic.
Votre meilleur travail
est à l'horizon
ComparerAlternative à VercelAlternative à AmazeeAlternative à HerokuAlternative à PantheonAlternative à l'hébergement géréAlternative à Fly.ioAlternative à RenderAlternative à AWSAlternative à AcquiaAlternative à DigitalOcean
ProduitAperçuSupport and servicesPreview environmentsMulti-cloud and edgeGit-driven automationObservability and profilingSecurity and complianceScaling and performanceBackups and data recoveryTeam and access managementCLI, console, and APIIntegrations and webhooksPricingPricing calculator
Cas d'utilisationSolutions backendApplication modernisationCommerce électroniqueHébergement CMSGestion multi sitesExtensions SaaS
Join our monthly newsletter
Compliant and validated