



Git se met en forme : accélérer l'API de notre projet grâce au profileur Blackfire


Upsun dispose d'une architecture unique. L'un des aspects les plus intéressants de cette architecture est que, bien que certaines de nos API soient multi-locataires, notre API la plus importante — celle qui contrôle chaque projet et ses environnements — est en réalité un démon mono-locataire.
Plus intéressant encore, ce démon à locataire unique est une API multiprotocole au sein de laquelle l’API principale utilise Git. Il expose également une API REST qui, à son tour, expose toutes ses capacités Git et les enrichit d’autres fonctionnalités, comme répondre à la commande permettant de mapper un nom de domaine à un environnement, configurer les autorisations d’accès ou faire évoluer un conteneur dans un environnement de test. En substance, toute modification apportée à un cluster en cours d’exécution passe par le démon personnalisé.
Qu’est-ce qu’un démon à locataire unique a de si génial ?
Quand on parle de « single-tenant », ça veut dire que chaque projet client d’Upsun a son propre démon entièrement isolé. Chacun a son propre magasin de données qui contient absolument tout ce dont le projet a besoin pour fonctionner — le tout depuis un seul endroit.
Ça offre tout un tas d’avantages à nos utilisateurs. Notamment la réduction extrême des zones de défaillance, la possibilité de déplacer des projets entre les régions et le déploiement continu de nouvelles fonctionnalités. Le tout sans aucun risque, car un problème de performance dans un projet ne peut pas affecter un autre, grâce à cette architecture. Et mieux encore, Git n’est pas sur le chemin des requêtes d’une application en cours d’exécution ; ce qui veut dire qu’il pourrait être hors service et que les clusters configurés continueraient de fonctionner sans problème.
Comment surveiller les performances avec des applications à locataire unique ?
On a dit beaucoup de bien des applications à locataire unique, mais il y a quelques difficultés à prendre en compte, notamment en ce qui concerne l’observabilité et l’optimisation des performances. Après tout, un projet comportant des centaines de branches et un historique très fourni se comportera très différemment d’un projet avec un seul commit. Ainsi, si tu ne définis pas de méthode pour hiérarchiser les efforts d’optimisation des performances, il est facile de laisser cet aspect important, mais pas nécessairement critique, passer au second plan et de laisser les performances de ton application se dégrader progressivement. Toutes les applications en production ont besoin d’observabilité, et à mesure que les systèmes gagnent en complexité, le besoin d’informations sur les performances s’intensifie.
Alors que de nombreux ingénieurs considèrent l’observabilité comme de simples traces, journaux ou métriques, son essence réside dans l’interrogation du système et l’analyse approfondie des goulots d’étranglement potentiels ou des domaines à optimiser. Réfléchis à ceci : un ingénieur devrait passer sans heurts de la question « Quels points de terminaison sont à la traîne ? » à l’interrogation « Que se passe-t-il dans le code pendant le 1 % le plus lent des requêtes HTTP, ou qu’est-ce qui est unique à ces instances, points de terminaison ou même utilisateurs les plus lents ? » Une véritable observabilité offre à la fois profondeur et ampleur, surtout lorsqu’on utilise un outil d’observabilité puissant comme Blackfire
Découvre Blackfire, l’expert en surveillance et en profilage
Blackfire prend en charge à la fois la surveillance des applications et le profilage pour maximiser les informations sur les performances et l’optimisation. La surveillance fait référence à une vue d’ensemble des métriques système : statut HTTP, délais de requête (P50 et P99), transactions les plus fréquentes, temps de réponse et métriques de mémoire, le tout organisé par attributs HTTP et par heure. Le profilage Blackfire, quant à lui, consiste en une analyse des applications à la demande. Pour activer le profilage, il suffit d’un en-tête HTTP spécifique ou d’une instrumentation manuelle du code. Et comme Blackfire a été conçu pour être un outil de profilage puissant, il excelle dans la visualisation des données, jette un œil ici :

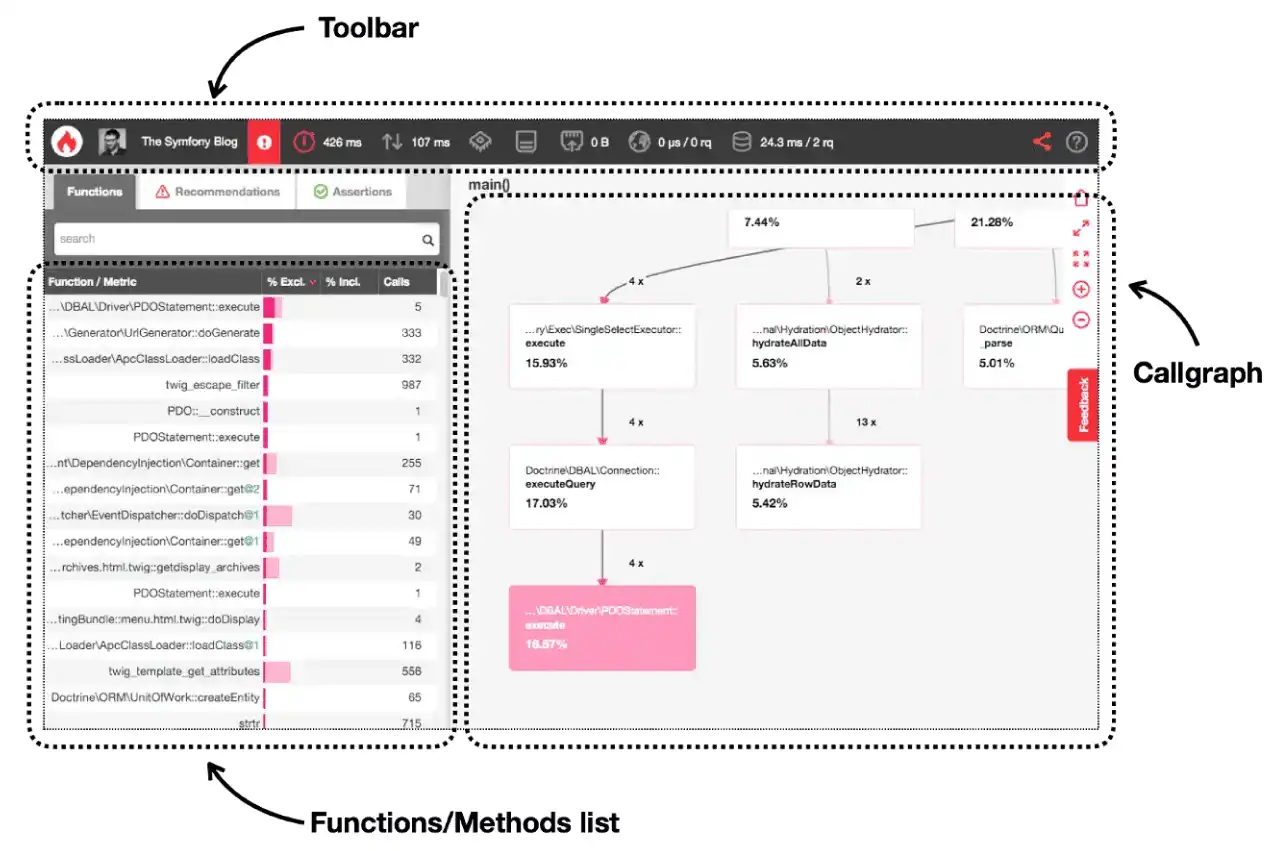
Ci-dessus, tu as une visualisation traditionnelle du callgraph, qui montre la représentation graphique de toutes les relations appelant-appelé. La timeline, quant à elle, affiche les appels de fonction qui ont eu lieu pendant le profilage sur un axe temporel.

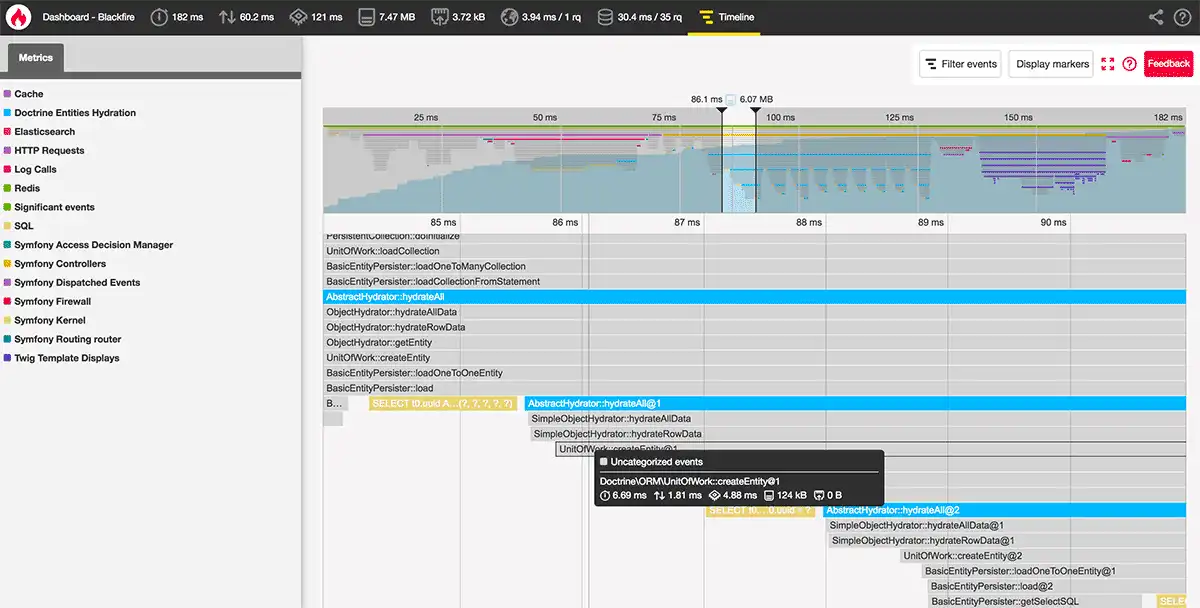
Comme tu peux le voir, Blackfire présente le temps réel, l'utilisation du CPU et la mémoire dans un seul profil. Cela te permet de voir le temps réel, le temps CPU et l'utilisation de la mémoire d'une fonction — voire les données réseau dans certains langages — en une seule session de profilage. Grâce à son profileur déterministe — qui effectue des mesures lorsqu’un événement particulier, tel qu’un appel de fonction, une sortie de fonction ou une exception, se produit —, il y a certes une certaine surcharge, mais Blackfire offre néanmoins une profondeur de profilage inégalée. Découvre-en plus sur les fonctionnalités de profilage d’Upsun et de Blackfire.
L'utilisation simultanée de la surveillance et du profilage Blackfire offre des opportunités continues d'identifier et de résoudre les goulots d'étranglement. La surveillance met en évidence les zones du système présentant les plus grands retards, tandis que le profilage nous permet d'explorer en profondeur ces goulots d'étranglement émergents et encore inexplorés, offrant ainsi une combinaison puissante pour des performances supérieures.
Dogfooding et mise en œuvre du service Git
On prend le dogfooding très au sérieux. En utilisant nos propres outils, on détecte les problèmes avant qu’ils n’atteignent nos utilisateurs et on améliore continuellement nos offres. La capacité à s’auto-tester est un avantage unique pour les outils d’observabilité, et chez Upsun, on adhère pleinement à cette approche : c’est un cercle vertueux. Par exemple, on teste systématiquement chaque service qu’on fournit, quelle que soit sa taille.
Git est au cœur des interactions avec les utilisateurs d’Upsun. Qu’il s’agisse de la configuration de l’environnement ou du déploiement de code, Git, construit sur le framework Pyramid de Python, joue un rôle crucial dans notre processus. Et compte tenu des capacités Python de Blackfire, le coupler avec Git était une décision intuitive.
Notre équipe Git interne a conçu un middleware WSGI pour une interaction fluide avec Blackfire. À partir de la version 1.17.0, Blackfire prend en charge Pyramid de manière native, ce qui simplifie l'intégration. Mais comment intégrer Blackfire à Git exactement ? Tout commence par cette commande :
blackfire-python gunicorn --workers=2 test:appCette commande garantit une intégration transparente avec les frameworks pris en charge ; assure-toi simplement de disposer d’un environnement Blackfire valide et des identifiants appropriés. Une fois que tu auras configuré l’environnement interne de notre service Git et activé la surveillance, notre tableau de bord s’affichera comme ceci :

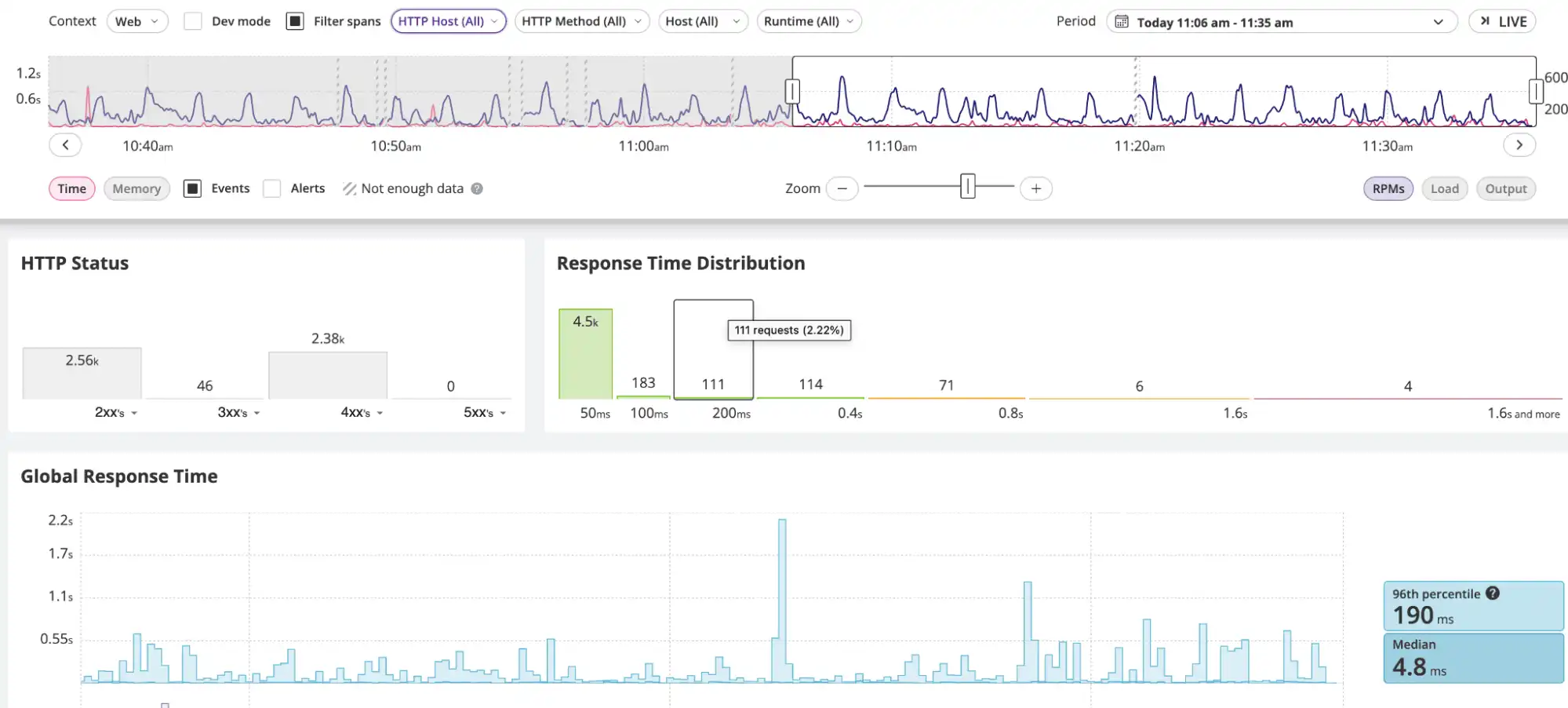
En regardant cet aperçu des données ci-dessus, il est évident que la majorité de nos commandes Git tournent autour de 50 ms, ce qui est bon signe. Pourtant, on peut quand même concentrer notre attention sur ces quatre requêtes dépassant 1,6 s, car elles représentent les transactions les plus lentes de notre système. Un excellent exemple de la façon dont l’observabilité de Blackfire peut mettre en évidence les domaines à optimiser — mais la solution à ce problème d’optimisation particulier n’est pas le sujet d’aujourd’hui.
L'optimisation des performances en action
Notre groupe Git interne a identifié plusieurs problèmes de performance se produisant uniquement dans certains environnements. La nature exacte de ces environnements restait inconnue, rendant la reproduction locale difficile. C’est là que le profilage à la demande de Blackfire s’est avéré inestimable. L’équipe a profilé des requêtes HTTP spécifiques, puis a analysé les résultats avec Blackfire. Voici une capture d’écran du profilage d’un point de terminaison Git lent :

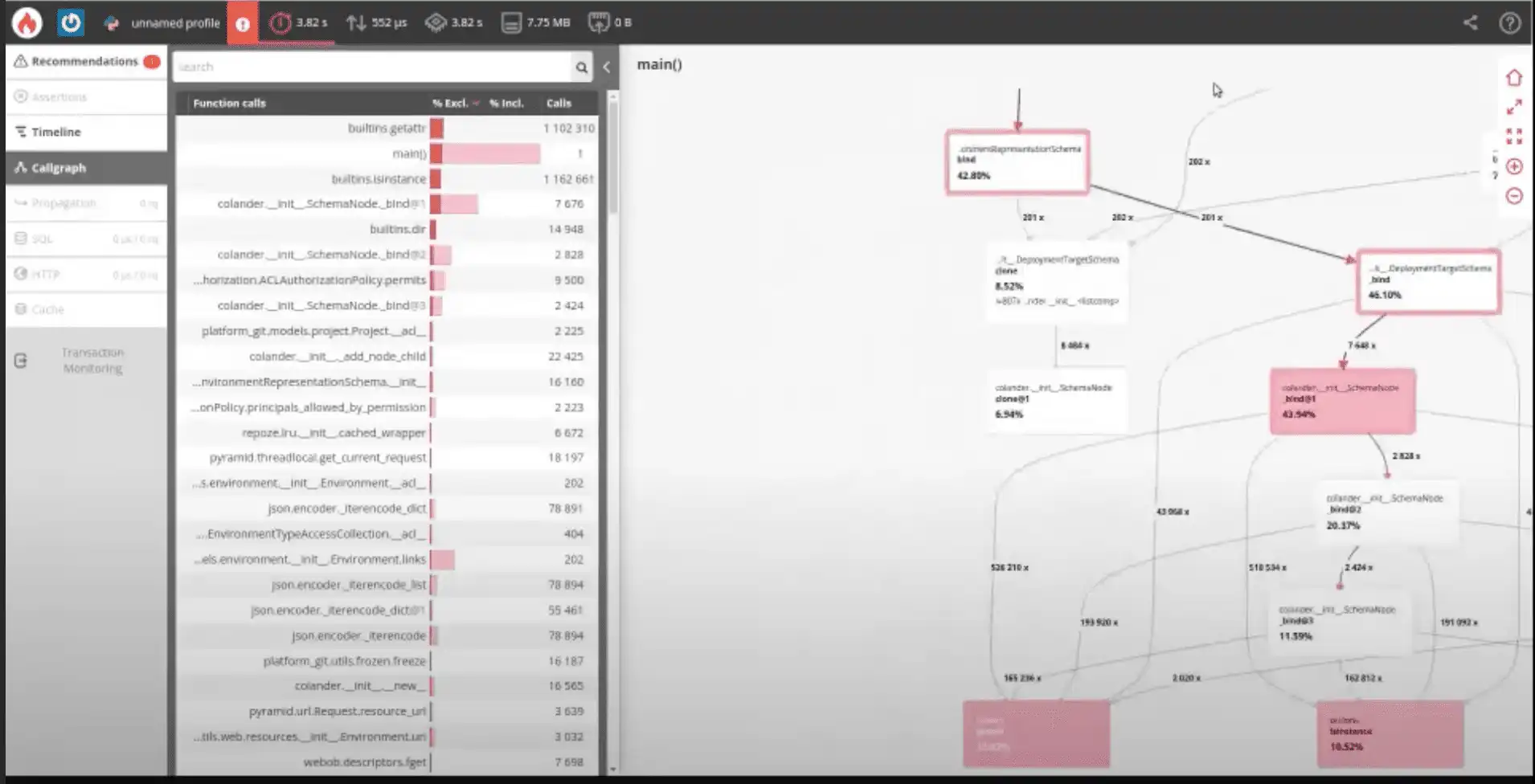
Un rapide coup d’œil aux principales métriques révèle que le temps réel et le temps CPU sont identiques, ce qui suggère un processus gourmand en CPU au sein de l’application. En revanche, si le goulot d’étranglement était lié aux E/S, comme un appel de microservice lent ou une lecture de fichier volumineuse, le temps réel refléterait le temps d’E/S.
En creusant davantage, la visualisation du callgraph de Blackfire identifie les freins aux performances en mettant en évidence en rouge la chaîne d'appels la plus chronophage, indiquant ainsi le chemin critique. Ce chemin met en évidence les fonctions mûres pour l'optimisation. L'analyse de l'équipe Git a révélé une fonction redondante dans ce chemin critique, traitant un grand tableau et effectuant des vérifications isinstance inutiles. L'élimination de cette fonction redondante a permis de réduire le temps d'exécution d'environ 40 %.
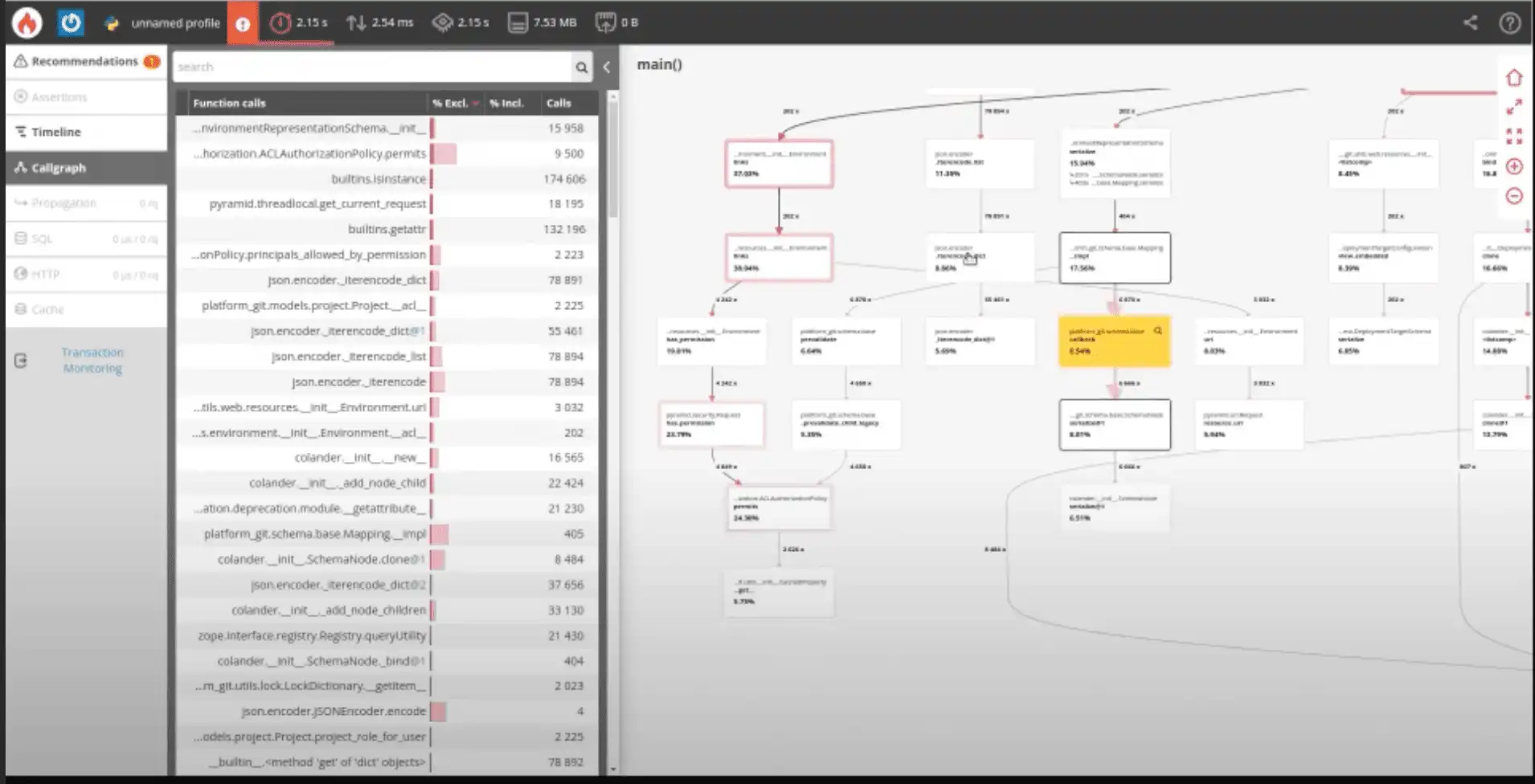
Grâce à cette optimisation, le graphe d'appels n'affiche plus de chemin critique, ce qui signifie qu'il ne reste plus de domaines évidents permettant des améliorations immédiates des performances. En d'autres termes, cela signifie que d'autres optimisations sont possibles, mais que les gains pourraient être moins importants.
Conclusion sur le profilage Blackfire
Blackfire nous permet de nous concentrer facilement sur les optimisations les plus évidentes, mais il n’est pas nécessaire de s’arrêter là. Grâce au profilage et à la surveillance intégrés, tu peux identifier divers goulots d’étranglement dans les systèmes de production, et ne les traiter que lorsque les corrections sont faciles à mettre en œuvre et rentables.
Tu seras peut-être surpris par les opportunités que tu rates sans un outil comme Blackfire, en particulier avec du code de production hérité qui ne disposait pas auparavant de capacités de surveillance. Découvre plus de détails sur nos fonctionnalités d’observabilité ou commence un essai gratuit dès aujourd’hui.
Votre meilleur travail
est à l'horizon

Join our monthly newsletter
Compliant and validated